 MySQL (2)
MySQL (2)
更新日:2022年03月11日
作成日:2016年07月03日
複数のテーブルの利用
以下のようなテーブルを使用します。
- tb :売り上げ・テーブル(ID、売り上げ、月)
- tb1 :社員・テーブル1(ID、 名前、生年月日)
- tb2 :社員・テーブル2(ID、 名前、生年月日)
- tb3 :社員・テーブル3(ID、 出身地)
mysql> DESC tb; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | varchar(10) | YES | | NULL | | | sales | int(11) | YES | | NULL | | | month | int(11) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.05 sec) mysql> SELECT * FROM tb; +------+-------+-------+ | id | sales | month | +------+-------+-------+ | C001 | 100 | 4 | | C003 | 77 | 5 | | C007 | 312 | 4 | | C002 | 238 | 4 | | C004 | 98 | 5 | | C006 | 156 | 4 | | C001 | 210 | 5 | | C007 | 180 | 5 | | C004 | 222 | 6 | | C003 | 198 | 6 | +------+-------+-------+ 10 rows in set (0.00 sec) mysql> DESC tb1; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | varchar(10) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | | birth | date | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.04 sec) mysql> SELECT * FROM tb1; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C003 | 田中 | 1978-08-15 | | C004 | 青山 | 1967-09-17 | | C005 | 伊東 | 1984-10-10 | +------+------+------------+ 5 rows in set (0.00 sec) mysql> DESC tb2; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | varchar(10) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | | birth | date | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.03 sec) mysql> SELECT * FROM tb2; +------+--------+------------+ | id | name | birth | +------+--------+------------+ | C006 | 小野山 | 1990-03-03 | | C007 | 金沢 | 1972-11-05 | | C008 | 中川 | 1982-09-07 | | C009 | 一之瀬 | 1966-04-08 | | C010 | 本田 | 1989-02-11 | +------+--------+------------+ 5 rows in set (0.00 sec) mysql> DESC tb3; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | varchar(10) | YES | | NULL | | | pref | varchar(10) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 2 rows in set (0.01 sec) mysql> SELECT * FROM tb3; +------+--------+ | id | pref | +------+--------+ | C001 | 長野県 | | C002 | 埼玉県 | | C003 | 東京都 | | C004 | 沖縄県 | | C005 | 福岡県 | +------+--------+ 5 rows in set (0.00 sec)
複数の抽出結果を表示 UNION
単純に複数のテーブルから抽出したデータを集めて表示するには UNION を使用します。
一緒に表示するカラムのデータ型は基本的には一致している必要があります。以下が書式です。
SELECT カラム名1 FROM テーブル名1 UNION SELECT カラム名2 FROM テーブル名2;
以下は、同じカラム構造の2つのテーブルのデータを集めて表示する例です。
mysql> SELECT * FROM tb1
-> UNION
-> SELECT * FROM tb2;
+------+--------+------------+
| id | name | birth |
+------+--------+------------+
| C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 |
| C005 | 伊東 | 1984-10-10 |
| C006 | 小野山 | 1990-03-03 |
| C007 | 金沢 | 1972-11-05 |
| C008 | 中川 | 1982-09-07 |
| C009 | 一之瀬 | 1966-04-08 |
| C010 | 本田 | 1989-02-11 |
+------+--------+------------+
10 rows in set (0.00 sec)
mysql> SELECT * FROM tb1;
+------+------+------------+
| id | name | birth |
+------+------+------------+
| C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 |
| C005 | 伊東 | 1984-10-10 |
+------+------+------------+
5 rows in set (0.00 sec)
mysql> SELECT * FROM tb2;
+------+--------+------------+
| id | name | birth |
+------+--------+------------+
| C006 | 小野山 | 1990-03-03 |
| C007 | 金沢 | 1972-11-05 |
| C008 | 中川 | 1982-09-07 |
| C009 | 一之瀬 | 1966-04-08 |
| C010 | 本田 | 1989-02-11 |
+------+--------+------------+
5 rows in set (0.00 sec)
前述の例では2つのテーブルからデータを集めましたが、UNION ではいくつでもテーブルを集めることができます。
SELECT * FROM tb1 UNION SELECT * FROM tb2; UNION SELECT * FROM tb3;
条件を付けて複数の抽出結果を表示
UNION を使って条件を付けて抽出するには、それぞれの SELECT 文の後に WHERE 等で条件を設定します。
次のような条件で抽出してみます。
- テーブル tb で、カラム sales の値が200以上のレコードの id
- テーブル tb1 で、カラム birth の値が 1980-01-01 より小さいレコードの id
mysql> SELECT * FROM tb;
+------+-------+-------+
| id | sales | month |
+------+-------+-------+
| C001 | 100 | 4 |
| C003 | 77 | 5 |
| C007 | 312 | 4 |
| C002 | 238 | 4 |
| C004 | 98 | 5 |
| C006 | 156 | 4 |
| C001 | 210 | 5 |
| C007 | 180 | 5 |
| C004 | 222 | 6 |
| C003 | 198 | 6 |
+------+-------+-------+
10 rows in set (0.00 sec)
mysql> SELECT * FROM tb1;
+------+------+------------+
| id | name | birth |
+------+------+------------+
| C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 |
| C005 | 伊東 | 1984-10-10 |
+------+------+------------+
5 rows in set (0.00 sec)
mysql> SELECT id FROM tb WHERE sales >= 200
-> UNION
-> SELECT id FROM tb1 WHERE birth < '1980-01-01';
+------+
| id |
+------+
| C007 |
| C002 |
| C001 |
| C004 |
| C003 |
+------+
5 rows in set (0.00 sec)
それぞれの SELECT 文を別々に実行してみます。
mysql> SELECT id FROM tb WHERE sales >= 200;
+------+
| id |
+------+
| C007 |
| C002 |
| C001 |
| C004 |
+------+
4 rows in set (0.00 sec)
mysql> SELECT id FROM tb1 WHERE birth < '1980-01-01';
+------+
| id |
+------+
| C002 |
| C003 |
| C004 |
+------+
3 rows in set (0.00 sec)
mysql> SELECT id FROM tb WHERE sales >= 200
-> UNION
-> SELECT id FROM tb1 WHERE birth < '1980-01-01';
+------+
| id |
+------+
| C007 |
| C002 |
| C001 |
| C004 |
| C003 |
+------+
5 rows in set (0.00 sec)
上記の結果から、UNION は「重複したデータを省く」処理も行っていることがわかります。上記の例では、「C002」と「C004」が重複しています。
重複を許容する UNION ALL
大量のデータがある場合、重複を省く処理により、かなりの待ち時間が発生します。大量のデータを処理する場合に、重複を省く処理をしないようにするには、UNION の後に ALL を付けます。
mysql> SELECT id FROM tb WHERE sales >= 200
-> UNION ALL
-> SELECT id FROM tb1 WHERE birth < '1980-01-01';
+------+
| id |
+------+
| C007 |
| C002 |
| C001 |
| C004 |
| C002 |
| C003 |
| C004 |
+------+
7 rows in set (0.00 sec)
内部結合(INNER JOIN)
複数のテーブルを何かのキーで結びつけて処理することを結合といいます。また、複数のテーブルで一致するレコードを取り出す結合を「内部結合」といいます。
内部結合を行うには JOIN を使います。または、明示的に内部結合であることを示すには INNER JOIN と記述することもできます(JOIN と INNER JOIN は同じです)。
以下が書式です。
SELECT カラム名 FROM テーブル 1 JOIN 結合するテーブル 2 ON テーブル 1 のカラム = テーブル 2 のカラム;
ON の後に2つのテーブルを結合する(紐付ける)カラムをイコール(=)で結んで指定します。
テーブル 1 のカラムというのは「テーブル名 . カラム名」のようにテーブル名とカラム名をドットでつないで記述します。
例えばテーブル tb のカラム id とテーブル tb1 のカラム id の場合、以下のようになります。
ON tb.id = tb1.id
「テーブル tb のカラム id」と「テーブル tb1 のカラム id」を一致させるキーにする(2つのテーブルを紐付ける)というような意味になります。
以下のようなテーブル tb と tb1 がある時、両方に共通のカラム id をキーにして内部結合で表示してみます。
mysql> SELECT * FROM tb;
+------+-------+-------+
| id | sales | month |
+------+-------+-------+
| C001 | 100 | 4 |
| C003 | 77 | 5 |
| C007 | 312 | 4 |
| C002 | 238 | 4 |
| C004 | 98 | 5 |
| C006 | 156 | 4 |
| C001 | 210 | 5 |
| C007 | 180 | 5 |
| C004 | 222 | 6 |
| C003 | 198 | 6 |
+------+-------+-------+
10 rows in set (0.00 sec)
mysql> SELECT * FROM tb1;
+------+------+------------+
| id | name | birth |
+------+------+------------+
| C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 |
| C005 | 伊東 | 1984-10-10 |
+------+------+------------+
5 rows in set (0.00 sec)
mysql> SELECT * FROM tb
-> JOIN tb1
-> ON tb.id = tb1.id;
+------+-------+-------+------+------+------------+
| id | sales | month | id | name | birth |
+------+-------+-------+------+------+------------+
| C001 | 100 | 4 | C001 | 山田 | 1980-01-23 |
| C003 | 77 | 5 | C003 | 田中 | 1978-08-15 |
| C002 | 238 | 4 | C002 | 鈴木 | 1959-12-25 |
| C004 | 98 | 5 | C004 | 青山 | 1967-09-17 |
| C001 | 210 | 5 | C001 | 山田 | 1980-01-23 |
| C004 | 222 | 6 | C004 | 青山 | 1967-09-17 |
| C003 | 198 | 6 | C003 | 田中 | 1978-08-15 |
+------+-------+-------+------+------+------------+
7 rows in set (0.00 sec)
上記の結果を見ると、「C005」、「C006」と「 C007」は結合の結果の表示にはありません。これは「C005」、「C006」と「 C007」が片方のテーブルにしか存在しないので、内部結合では取り出されないためです。
USING
結合に使うキー(カラム名)が同じ名前の場合、USING(キーとなるカラム名)と記述することもできます。この場合、抽出結果にはキーとなるカラムは一度しか表示されません。
SELECT カラム名 FROM テーブル 1 JOIN 結合するテーブル2 USING(キーとなるカラム名);
mysql> SELECT * FROM tb
-> JOIN tb1
-> USING (id);
+------+-------+-------+------+------------+
| id | sales | month | name | birth |
+------+-------+-------+------+------------+
| C001 | 100 | 4 | 山田 | 1980-01-23 |
| C003 | 77 | 5 | 田中 | 1978-08-15 |
| C002 | 238 | 4 | 鈴木 | 1959-12-25 |
| C004 | 98 | 5 | 青山 | 1967-09-17 |
| C001 | 210 | 5 | 山田 | 1980-01-23 |
| C004 | 222 | 6 | 青山 | 1967-09-17 |
| C003 | 198 | 6 | 田中 | 1978-08-15 |
+------+-------+-------+------+------------+
7 rows in set (0.00 sec)
カラムを指定して表示
前述の例では、「*」を使って全てのカラムを表示しましたが、カラムを指定して表示することもできます。
但し、テーブルを結合する場合、単にカラム名を記述してもどのテーブルのカラムかわからないため「テーブル名 . カラム名」と記述する必要があります。
表示されるカラムの順番は、指定した順番で表示されます。また、同じカラムを何回表示してもかまいません。
以下は、テーブル tb と tb1 の両方に共通のカラム id をキーにして内部結合し、tb のからむ id、tb1 のカラム name、tb のカラム sales を表示する例です。
mysql> SELECT tb.id, tb1.name, tb.sales
-> FROM tb
-> JOIN tb1
-> USING (id);
+------+------+-------+
| id | name | sales |
+------+------+-------+
| C001 | 山田 | 100 |
| C003 | 田中 | 77 |
| C002 | 鈴木 | 238 |
| C004 | 青山 | 98 |
| C001 | 山田 | 210 |
| C004 | 青山 | 222 |
| C003 | 田中 | 198 |
+------+------+-------+
7 rows in set (0.00 sec)
テーブル名にエイリアスを使う
テーブル名にエイリアスを設定することもできます。カラムにエイリアスを付ける場合と同じように「AS」を使います。
複雑で長いテーブル名の場合「テーブル名 . カラム名」と記述すると読みづらくなりますが、エイリアスを使うと「エイリアス.カラム名」と簡潔に記述できます。
このサンプルの場合、テーブル名が短いのであまり違いはありませんが、テーブル tb に「X」、テーブル tb1 に「Y」というエイリアスを付けて実行する例です。
mysql> SELECT X.id, Y.name, X.sales
-> FROM tb AS X
-> JOIN tb1 AS Y
-> USING (id);
+------+------+-------+
| id | name | sales |
+------+------+-------+
| C001 | 山田 | 100 |
| C003 | 田中 | 77 |
| C002 | 鈴木 | 238 |
| C004 | 青山 | 98 |
| C001 | 山田 | 210 |
| C004 | 青山 | 222 |
| C003 | 田中 | 198 |
+------+------+-------+
7 rows in set (0.00 sec)
WHERE で条件を設定して抽出
結合したテーブルで WHERE で条件を設定してデータを抽出する場合、カラム名は「テーブル名 . カラム名」のようにテーブル名を付けて記述します。また、テーブルにエイリアスが設定されている場合は、「エイリアス.カラム名」と記述することもできます。
以下は、テーブル tb にテーブル tb1 を内部結合し、テーブル tb のカラム sales の値が200以上のレコードを表示する例です。
mysql> SELECT tb.id, tb1.name, tb.sales
-> FROM tb
-> JOIN tb1
-> USING (id)
-> WHERE tb.sales >= 200;
+------+------+-------+
| id | name | sales |
+------+------+-------+
| C002 | 鈴木 | 238 |
| C001 | 山田 | 210 |
| C004 | 青山 | 222 |
+------+------+-------+
3 rows in set (0.00 sec)
3つ以上のテーブルを結合
JOIN を使ってテーブルを結合する場合、その数に制限はありません。但し、たくさんのテーブルを結合すればそれだけ処理に時間がかかります。
2つ以上のテーブルを内部結合するには、以下のようにします。
SELECT ~ FROM
テーブル名1
JOIN テーブル名2
ON キーとなるテーブル1のカラム名 = キーとなるテーブル2のカラム名
JOIN テーブル名3
ON キーとなるテーブル1のカラム名 = キーとなるテーブル3のカラム名
...
;
//または USING を使って
SELECT ~ FROM
テーブル名1
JOIN テーブル名2
USING ( キーとなるカラム名 )
JOIN テーブル名3
USING ( キーとなるカラム名 )
...
;
以下のテーブル tb, tb1, tb3 には、共通の値を持ったカラム id があります。
mysql> SELECT * FROM tb; +------+-------+-------+ | id | sales | month | +------+-------+-------+ | C001 | 100 | 4 | | C003 | 77 | 5 | | C007 | 312 | 4 | | C002 | 238 | 4 | | C004 | 98 | 5 | | C006 | 156 | 4 | | C001 | 210 | 5 | | C007 | 180 | 5 | | C004 | 222 | 6 | | C003 | 198 | 6 | +------+-------+-------+ 10 rows in set (0.00 sec) mysql> SELECT * FROM tb1; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C003 | 田中 | 1978-08-15 | | C004 | 青山 | 1967-09-17 | | C005 | 伊東 | 1984-10-10 | +------+------+------------+ 5 rows in set (0.00 sec) mysql> SELECT * FROM tb3; +------+--------+ | id | pref | +------+--------+ | C001 | 長野県 | | C002 | 埼玉県 | | C003 | 東京都 | | C004 | 沖縄県 | | C005 | 福岡県 | +------+--------+ 5 rows in set (0.01 sec)
以下は、カラム id をキーにして、テーブル tb, tb1, tb3 を結合し、tb.id, tb.sales, tb1.name, tb3.pref のカラムを表示する例です。
mysql> SELECT tb.id, tb.sales, tb1.name, tb3.pref
-> FROM tb
-> JOIN tb1 USING(id)
-> JOIN tb3 USING(id);
+------+-------+------+--------+
| id | sales | name | pref |
+------+-------+------+--------+
| C001 | 100 | 山田 | 長野県 |
| C003 | 77 | 田中 | 東京都 |
| C002 | 238 | 鈴木 | 埼玉県 |
| C004 | 98 | 青山 | 沖縄県 |
| C001 | 210 | 山田 | 長野県 |
| C004 | 222 | 青山 | 沖縄県 |
| C003 | 198 | 田中 | 東京都 |
+------+-------+------+--------+
7 rows in set (0.00 sec)
//ON を使った場合
mysql> SELECT tb.id, tb.sales, tb1.name, tb3.pref
-> FROM tb
-> JOIN tb1 ON tb.id = tb1.id
-> JOIN tb3 ON tb.id = tb3.id;
+------+-------+------+--------+
| id | sales | name | pref |
+------+-------+------+--------+
| C001 | 100 | 山田 | 長野県 |
| C003 | 77 | 田中 | 東京都 |
| C002 | 238 | 鈴木 | 埼玉県 |
| C004 | 98 | 青山 | 沖縄県 |
| C001 | 210 | 山田 | 長野県 |
| C004 | 222 | 青山 | 沖縄県 |
| C003 | 198 | 田中 | 東京都 |
+------+-------+------+--------+
7 rows in set (0.00 sec)
外部結合
前述の内部結合(JOIN または INNER JOIN)は、キーが一致しているレコードのみを取り出します。
そのため、以下のようなテーブルがある場合、内部結合を行うと片方のテーブルにしかない、「C005」、「C006」と「 C007」は表示されません。
テーブル1(tb) テーブル2(tb1)
+------+-------+-------+ +------+------+------------+
| id | sales | month | | id | name | birth |
+------+-------+-------+ +------+------+------------+
| C001 | 100 | 4 | | C001 | 山田 | 1980-01-23 |
| C003 | 77 | 5 | | C002 | 鈴木 | 1959-12-25 |
| C007 | 312 | 4 | | C003 | 田中 | 1978-08-15 |
| C002 | 238 | 4 | | C004 | 青山 | 1967-09-17 |
| C004 | 98 | 5 | | C005 | 伊東 | 1984-10-10 |
| C006 | 156 | 4 | +------+------+------------+
| C001 | 210 | 5 |
| C007 | 180 | 5 |
| C004 | 222 | 6 |
| C003 | 198 | 6 |
+------+-------+-------+
//INNER JOIN(内部結合)
mysql> SELECT * FROM tb
-> JOIN tb1
-> USING (id);
+------+-------+-------+------+------------+
| id | sales | month | name | birth |
+------+-------+-------+------+------------+
| C001 | 100 | 4 | 山田 | 1980-01-23 |
| C003 | 77 | 5 | 田中 | 1978-08-15 |
| C002 | 238 | 4 | 鈴木 | 1959-12-25 |
| C004 | 98 | 5 | 青山 | 1967-09-17 |
| C001 | 210 | 5 | 山田 | 1980-01-23 |
| C004 | 222 | 6 | 青山 | 1967-09-17 |
| C003 | 198 | 6 | 田中 | 1978-08-15 |
+------+-------+-------+------+------------+
7 rows in set (0.00 sec)
外部結合は、一致していなくても、片方のテーブルのレコードは全て取り出します。
外部結合には、結合時にどちらのテーブルのレコードを全て表示するかにより、以下の2つがあります。
- 左外部結合 LEFT JOIN
- 「一致したレコード」及び「テーブル1(左側)の全データ」を表示
- 右外部結合 RIGHT JOIN
- 「一致したレコード」及び「テーブル2(右側)の全データ」を表示
左外部結合(LEFT JOIN)
左外部結合にするには、LEFT JOIN を使います。書式は、内部結合の JOIN または INNER JOIN の代わりに、LEFT JOIN を指定するだけです。
SELECT カラム名
FROM テーブル1
LEFT JOIN 結合するテーブル2
ON テーブル1のカラム = 結合するテーブル2のカラム;
//または、USING ( キーとなるカラム名 )
「テーブル1」と「結合するテーブル2」で一致したレコード、及び左側に相当する「テーブル1」の全てを表示します。
以下は、カラム id をキーに、テーブル tb と tb1 で一致したレコードと、テーブル tb の全てのレコードを左外部結合で表示する例です。
テーブル1(tb) テーブル2(tb1)
+------+-------+-------+ +------+------+------------+
| id | sales | month | | id | name | birth |
+------+-------+-------+ +------+------+------------+
| C001 | 100 | 4 | | C001 | 山田 | 1980-01-23 |
| C003 | 77 | 5 | | C002 | 鈴木 | 1959-12-25 |
| C007 | 312 | 4 | | C003 | 田中 | 1978-08-15 |
| C002 | 238 | 4 | | C004 | 青山 | 1967-09-17 |
| C004 | 98 | 5 | | C005 | 伊東 | 1984-10-10 |
| C006 | 156 | 4 | +------+------+------------+
| C001 | 210 | 5 |
| C007 | 180 | 5 |
| C004 | 222 | 6 |
| C003 | 198 | 6 |
+------+-------+-------+
mysql> SELECT * FROM tb
-> LEFT JOIN tb1
-> USING (id);
+------+-------+-------+------+------------+
| id | sales | month | name | birth |
+------+-------+-------+------+------------+
| C001 | 100 | 4 | 山田 | 1980-01-23 |
| C001 | 210 | 5 | 山田 | 1980-01-23 |
| C002 | 238 | 4 | 鈴木 | 1959-12-25 |
| C003 | 77 | 5 | 田中 | 1978-08-15 |
| C003 | 198 | 6 | 田中 | 1978-08-15 |
| C004 | 98 | 5 | 青山 | 1967-09-17 |
| C004 | 222 | 6 | 青山 | 1967-09-17 |
| C007 | 312 | 4 | NULL | NULL |
| C006 | 156 | 4 | NULL | NULL |
| C007 | 180 | 5 | NULL | NULL |
+------+-------+-------+------+------------+
10 rows in set (0.00 sec)
両方のテーブルで一致したレコードと、左側のテーブルの全てのレコードが表示されています。右側のテーブルだけにある「C005 伊東」は表示されません。
また、左側のテーブルだけにある「C006」と「C007」の name と birth の値は NULL になります。
右外部結合(RIGHT JOIN)
右外部結合にするには、RIGHT JOIN を使います。
SELECT カラム名
FROM テーブル1
RIGHT JOIN 結合するテーブル2
ON テーブル1のカラム = 結合するテーブル2のカラム;
//または、USING ( キーとなるカラム名 )
「テーブル1」と「結合するテーブル2」で一致したレコード、及び右側に相当する「結合するテーブル2」の全てを表示します。
以下は、カラム id をキーに、テーブル tb と tb1 で一致したレコードと、テーブル tb1 の全てのレコードを右外部結合で表示する例です。また、この例では表示するカラムを * とはせずに、限定しています。
テーブル1(tb) テーブル2(tb1)
+------+-------+-------+ +------+------+------------+
| id | sales | month | | id | name | birth |
+------+-------+-------+ +------+------+------------+
| C001 | 100 | 4 | | C001 | 山田 | 1980-01-23 |
| C003 | 77 | 5 | | C002 | 鈴木 | 1959-12-25 |
| C007 | 312 | 4 | | C003 | 田中 | 1978-08-15 |
| C002 | 238 | 4 | | C004 | 青山 | 1967-09-17 |
| C004 | 98 | 5 | | C005 | 伊東 | 1984-10-10 |
| C006 | 156 | 4 | +------+------+------------+
| C001 | 210 | 5 |
| C007 | 180 | 5 |
| C004 | 222 | 6 |
| C003 | 198 | 6 |
+------+-------+-------+
mysql> SELECT tb1.id, tb1.name, tb.sales FROM tb
-> RIGHT JOIN tb1
-> ON tb.id = tb1.id;
+------+------+-------+
| id | name | sales |
+------+------+-------+
| C001 | 山田 | 100 |
| C003 | 田中 | 77 |
| C002 | 鈴木 | 238 |
| C004 | 青山 | 98 |
| C001 | 山田 | 210 |
| C004 | 青山 | 222 |
| C003 | 田中 | 198 |
| C005 | 伊東 | NULL |
+------+------+-------+
8 rows in set (0.00 sec)
両方のテーブルで一致したレコードと、右側のテーブルの全てのレコードが表示されています。右側のテーブルだけにある「C006」「C007」は表示されません。
また、SELECT で表示するカラムを tb1.id, tb1.name, tb.sales としていますが、カラム tb1.id を tb.id とした場合、テーブル tb のカラム id には C005 は存在しないので、結合の結果の表示では C005 は表示されず NULL となります。
mysql> SELECT tb.id, tb1.name, tb.sales FROM tb
-> RIGHT JOIN tb1
-> ON tb.id = tb1.id;
+------+------+-------+
| id | name | sales |
+------+------+-------+
| C001 | 山田 | 100 |
| C003 | 田中 | 77 |
| C002 | 鈴木 | 238 |
| C004 | 青山 | 98 |
| C001 | 山田 | 210 |
| C004 | 青山 | 222 |
| C003 | 田中 | 198 |
| NULL | 伊東 | NULL |
+------+------+-------+
8 rows in set (0.00 sec)
自己結合
テーブルは自分自身(同じ名前のテーブル)を結合することができ、これを自己結合と言います。結合するときには、そのままでは、カラムが識別できずエラーとなるため、必ずテーブル名にエイリアスを付けます。
自己結合を行うと、自分が持つ全てのレコードに、さらに自分が持つ全てのレコードが結合するので、その結果には、全ての組み合わせが存在します。
SELECT カラム名 FROM テーブル名 AS エイリアス1 JOIN テーブル名 AS エイリアス2;
同じテーブルに、異なる2つのエイリアスを付けます。
以下は、テーブル tb1 を自己結合して表示する例です。
mysql> SELECT * FROM tb1;
+------+------+------------+
| id | name | birth |
+------+------+------------+
| C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 |
| C005 | 伊東 | 1984-10-10 |
+------+------+------------+
5 rows in set (0.00 sec)
mysql> SELECT * FROM tb1 AS A
-> JOIN
-> tb1 AS B;
+------+------+------------+------+------+------------+
| id | name | birth | id | name | birth |
+------+------+------------+------+------+------------+
| C001 | 山田 | 1980-01-23 | C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 | C001 | 山田 | 1980-01-23 |
| C003 | 田中 | 1978-08-15 | C001 | 山田 | 1980-01-23 |
| C004 | 青山 | 1967-09-17 | C001 | 山田 | 1980-01-23 |
| C005 | 伊東 | 1984-10-10 | C001 | 山田 | 1980-01-23 |
| C001 | 山田 | 1980-01-23 | C002 | 鈴木 | 1959-12-25 |
| C002 | 鈴木 | 1959-12-25 | C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 | C002 | 鈴木 | 1959-12-25 |
| C004 | 青山 | 1967-09-17 | C002 | 鈴木 | 1959-12-25 |
| C005 | 伊東 | 1984-10-10 | C002 | 鈴木 | 1959-12-25 |
| C001 | 山田 | 1980-01-23 | C003 | 田中 | 1978-08-15 |
| C002 | 鈴木 | 1959-12-25 | C003 | 田中 | 1978-08-15 |
| C003 | 田中 | 1978-08-15 | C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 | C003 | 田中 | 1978-08-15 |
| C005 | 伊東 | 1984-10-10 | C003 | 田中 | 1978-08-15 |
| C001 | 山田 | 1980-01-23 | C004 | 青山 | 1967-09-17 |
| C002 | 鈴木 | 1959-12-25 | C004 | 青山 | 1967-09-17 |
| C003 | 田中 | 1978-08-15 | C004 | 青山 | 1967-09-17 |
| C004 | 青山 | 1967-09-17 | C004 | 青山 | 1967-09-17 |
| C005 | 伊東 | 1984-10-10 | C004 | 青山 | 1967-09-17 |
| C001 | 山田 | 1980-01-23 | C005 | 伊東 | 1984-10-10 |
| C002 | 鈴木 | 1959-12-25 | C005 | 伊東 | 1984-10-10 |
| C003 | 田中 | 1978-08-15 | C005 | 伊東 | 1984-10-10 |
| C004 | 青山 | 1967-09-17 | C005 | 伊東 | 1984-10-10 |
| C005 | 伊東 | 1984-10-10 | C005 | 伊東 | 1984-10-10 |
+------+------+------------+------+------+------------+
25 rows in set (0.00 sec)
上記の例は、JOIN(内部結合)で2つのテーブルを ON または USING を使って、結合するカラムを指定しない処理になっています。
ON または USING を使うと、以下のようになります。
mysql> SELECT * FROM tb1 AS A
-> JOIN
-> tb1 AS B
-> USING (id);
+------+------+------------+------+------------+
| id | name | birth | name | birth |
+------+------+------------+------+------------+
| C001 | 山田 | 1980-01-23 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 | 青山 | 1967-09-17 |
| C005 | 伊東 | 1984-10-10 | 伊東 | 1984-10-10 |
+------+------+------------+------+------------+
5 rows in set (0.00 sec)
自己結合を使った順位付け
以下は、自己結合を使った順位付けの例です。ORDER BY を使えば値の順番に表示することは簡単ですが、順位付けをするには工夫が必要です。(順位付けにはこの他にサブクエリ、AUTO_INCREMENT を使った順位付けなどがあります)
以下は、野球選手の ID (id), 名前 (player)、ホームラン数(hr)のテーブル tby です。
mysql> DESC tby; +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | varchar(10) | YES | | NULL | | | player | varchar(20) | YES | | NULL | | | hr | int(11) | YES | | NULL | | +--------+-------------+------+-----+---------+-------+ 3 rows in set (0.04 sec) mysql> SELECT * FROM tby; +------+---------+------+ | id | player | hr | +------+---------+------+ | Y001 | Beltran | 16 | | Y002 | McCann | 21 | | Y003 | Castro | 19 | +------+---------+------+ 3 rows in set (0.00 sec)
上記テーブル tby を自己結合すると、以下のようになります。
mysql> SELECT * FROM tby AS A
-> JOIN
-> tby AS B;
+------+---------+------+------+---------+------+
| id | player | hr | id | player | hr |
+------+---------+------+------+---------+------+
| Y001 | Beltran | 16 | Y001 | Beltran | 16 |
| Y002 | McCann | 21 | Y001 | Beltran | 16 |
| Y003 | Castro | 19 | Y001 | Beltran | 16 |
+------+---------+------+------+---------+------+
| Y001 | Beltran | 16 | Y002 | McCann | 21 |
| Y002 | McCann | 21 | Y002 | McCann | 21 |
| Y003 | Castro | 19 | Y002 | McCann | 21 |
+------+---------+------+------+---------+------+
| Y001 | Beltran | 16 | Y003 | Castro | 19 |
| Y002 | McCann | 21 | Y003 | Castro | 19 |
| Y003 | Castro | 19 | Y003 | Castro | 19 |
+------+---------+------+------+---------+------+
9 rows in set (0.00 sec)
この例では、カラム hr (ホームラン数) の順位付けをします。
右側のカラム player の Beltran のホームラン数(hr)16 に対して、左側にはそれぞれの選手のホームラン数(16, 21, 19)が表示されています。
最初の3行で、Beltran のホームラン数(hr)16 以上の値は、自身のホームラン数(16)と McCann(21)、Castro(19)の3つです。(順位は3番)
次の3行で、McCann のホームラン数(hr)21 以上の値は、自身のホームラン数(21)のみで1つです。(順位は1番)
次の3行で、Castro のホームラン数(hr)19 以上の値は、自身のホームラン数(19)と McCann(21)の2つです。(順位は2番)
つまり、自己結合して左側の hr の値が右側の hr の値以上になっている数を player のグループごとに数えれば、順位が得られることになります。
mysql> SELECT A.player, A.hr, COUNT(*) AS 順位
-> FROM tby AS A
-> JOIN tby AS B
-> WHERE A.hr <= B.hr
-> GROUP BY A.id;
+---------+------+------+
| player | hr | 順位 |
+---------+------+------+
| Beltran | 16 | 3 |
| McCann | 21 | 1 |
| Castro | 19 | 2 |
+---------+------+------+
3 rows in set (0.00 sec)
自己結合して、WHERE で条件「WHERE A.hr <= B.hr」を設定し、カラム id でグループ化します。そして個数を COUNT(*) で数えれば順位が得られます
以下のようにどちら側のカラムを表示するかにより、同じことを異なる記述で処理できます。
テーブル tby AS A テーブル tby AS B +------+---------+------+ +------+---------+------+ | id | player | hr | | id | player | hr | +------+---------+------+ +------+---------+------+ | Y001 | Beltran | 16 | | Y001 | Beltran | 16 | | Y002 | McCann | 21 | | Y002 | McCann | 21 | | Y003 | Castro | 19 | | Y003 | Castro | 19 | +------+---------+------+ +------+---------+------+
左側のテーブル(AS A)のカラム id でグループ化する場合(A の hr の値が小さい個数)。前述の例と同じ。
mysql> SELECT A.player, A.hr, COUNT(*) AS 順位
-> FROM tby AS A
-> JOIN tby AS B
-> WHERE A.hr <= B.hr
-> GROUP BY A.id;
+---------+------+------+
| player | hr | 順位 |
+---------+------+------+
| Beltran | 16 | 3 |
| McCann | 21 | 1 |
| Castro | 19 | 2 |
+---------+------+------+
3 rows in set (0.00 sec)
右側のテーブル(AS B)のカラム id でグループ化する場合(A の hr の値が大きい個数)
mysql> SELECT B.player, B.hr, COUNT(*) AS 順位
-> FROM tby AS A
-> JOIN tby AS B
-> WHERE A.hr >= B.hr
-> GROUP BY B.id;
+---------+------+------+
| player | hr | 順位 |
+---------+------+------+
| Beltran | 16 | 3 |
| McCann | 21 | 1 |
| Castro | 19 | 2 |
+---------+------+------+
3 rows in set (0.00 sec)
自己結合の例
以下のような社員のテーブル tbs があります。
カラム id は社員の ID、カラム name は社員の名前、カラム boss はその社員の上司の ID になっています。
カラム boss(上司の ID)が社員の ID を参照するキーになっています。
mysql> DESC tbs; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | varchar(10) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | | boss | varchar(10) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.03 sec) mysql> SELECT * FROM tbs; +------+-------+------+ | id | name | boss | +------+-------+------+ | 001 | Ken | 101 | | 002 | John | 102 | | 003 | Terry | 101 | | 101 | Irene | 201 | | 102 | David | 201 | | 201 | Scott | NULL | +------+-------+------+ 6 rows in set (0.00 sec)
このテーブルを自己結合すると以下のようになります。
mysql> SELECT * FROM tbs AS A
-> JOIN tbs AS B;
+------+-------+------+------+-------+------+
| id | name | boss | id | name | boss |
+------+-------+------+------+-------+------+
| 001 | Ken | 101 | 001 | Ken | 101 |
| 002 | John | 102 | 001 | Ken | 101 |
| 003 | Terry | 101 | 001 | Ken | 101 |
| 101 | Irene | 201 | 001 | Ken | 101 |
| 102 | David | 201 | 001 | Ken | 101 |
| 201 | Scott | NULL | 001 | Ken | 101 |
| 001 | Ken | 101 | 002 | John | 102 |
| 002 | John | 102 | 002 | John | 102 |
| 003 | Terry | 101 | 002 | John | 102 |
| 101 | Irene | 201 | 002 | John | 102 |
| 102 | David | 201 | 002 | John | 102 |
| 201 | Scott | NULL | 002 | John | 102 |
| 001 | Ken | 101 | 003 | Terry | 101 |
| 002 | John | 102 | 003 | Terry | 101 |
...............以下省略......................
自己結合して、カラム boss(上司の ID)の値が社員の ID と一致するレコードを探せば、社員と上司の組み合わせを取り出すことができます。
mysql> SELECT B.id, B.name, A.name AS 上司
-> FROM tbs AS A
-> JOIN tbs AS B
-> WHERE B.boss = A.id;
+------+-------+-------+
| id | name | 上司 |
+------+-------+-------+
| 001 | Ken | Irene |
| 002 | John | David |
| 003 | Terry | Irene |
| 101 | Irene | Scott |
| 102 | David | Scott |
+------+-------+-------+
5 rows in set (0.00 sec)
サブクエリ
サブクエリを使うと、「クエリを実行して取り出したデータを使って、さらにクエリを発行する」という2段階の処理が可能になります。(サブクエリが使える MySQL のバージョンは4.1以降です)
特定のレコードを表示
この例では以下のテーブル tb を使用します。
mysql> DESC tb; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | varchar(10) | YES | | NULL | | | sales | int(11) | YES | | NULL | | | month | int(11) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.05 sec) mysql> SELECT * FROM tb; +------+-------+-------+ | id | sales | month | +------+-------+-------+ | C001 | 100 | 4 | | C003 | 77 | 5 | | C007 | 312 | 4 | | C002 | 238 | 4 | | C004 | 98 | 5 | | C006 | 156 | 4 | | C001 | 210 | 5 | | C007 | 180 | 5 | | C004 | 222 | 6 | | C003 | 198 | 6 | +------+-------+-------+ 10 rows in set (0.00 sec)
最大値を持つレコードを表示
カラム sales の最大値を集計するには、以下のようにします。
mysql> SELECT MAX(sales) FROM tb; +------------+ | MAX(sales) | +------------+ | 312 | +------------+ 1 row in set (0.00 sec)
最大値を持つレコードを抽出するには、一度上記の集計によって得た最大値を使ってテーブル tb から抽出します。
1段階目の処理(サブクエリ):SELECT MAX(sales) FROM tb →最大値を取得
2段階目の処理:サブクエリを使って目的のレコードを抽出
SELECT * FROM tb WHERE sales = (1段階目の処理/サブクエリ);
1段階目の処理のサブクエリは括弧()で囲んで記述します。
mysql> SELECT * FROM tb
-> WHERE
-> sales = (SELECT MAX(sales) FROM tb);
+------+-------+-------+
| id | sales | month |
+------+-------+-------+
| C007 | 312 | 4 |
+------+-------+-------+
1 row in set (0.00 sec)
平均以上のレコードを抽出
以下は、カラム sales の平均値以上の値を持つレコードを抽出する例です。
1段階目の処理(サブクエリ)としてカラム sales の平均値を取得します。
mysql> SELECT * FROM tb
-> WHERE
-> sales >= (SELECT AVG(sales) FROM tb);
+------+-------+-------+
| id | sales | month |
+------+-------+-------+
| C007 | 312 | 4 |
| C002 | 238 | 4 |
| C001 | 210 | 5 |
| C007 | 180 | 5 |
| C004 | 222 | 6 |
| C003 | 198 | 6 |
+------+-------+-------+
6 rows in set (0.00 sec)
mysql> SELECT AVG(sales) FROM tb;
+------------+
| AVG(sales) |
+------------+
| 179.1000 |
+------------+
1 row in set (0.00 sec)
カラムを返すサブクエリ(IN)
前述の例では、サブクエリが1つの値を返しましたが、この例では1段階目のサブクエリで、条件に合ったカラムを返し、そのカラムを含むレコードを2段階目で抽出します。
1段階目のサブクエリの結果返されるカラムには、複数の値が含まれる可能性があるので、以下のように IN を使います。
SELECT 表示するカラム FROM テーブル名 WHERE カラム名 IN (SELECT によるサブクエリでカラムを抽出);
複数の値を返すサブクエリで、= を使うと以下のようにエラーになります。
mysql> SELECT * FROM tb1 -> WHERE -> id = (SELECT id FROM tb WHERE sales >= 200); ERROR 1242 (21000): Subquery returns more than 1 row
以下の2つのテーブル(tb, tb1)を使って、sales の値が 200 以上の人の名前を表示します。
この場合、以下のような2段階の処理になります。
- 1段階目:テーブル tb で sales の値が 200 以上の id を抽出
- 2段階目:テーブル tb1 で1段階目で抽出した id を持つ name を抽出
tb tb1 +------+-------+-------+ +------+------+------------+ | id | sales | month | | id | name | birth | +------+-------+-------+ +------+------+------------+ | C001 | 100 | 4 | | C001 | 山田 | 1980-01-23 | | C003 | 77 | 5 | | C002 | 鈴木 | 1959-12-25 | | C007 | 312 | 4 | | C003 | 田中 | 1978-08-15 | | C002 | 238 | 4 | | C004 | 青山 | 1967-09-17 | | C004 | 98 | 5 | | C005 | 伊東 | 1984-10-10 | | C006 | 156 | 4 | +------+------+------------+ | C001 | 210 | 5 | | C007 | 180 | 5 | | C004 | 222 | 6 | | C003 | 198 | 6 | +------+-------+-------+ mysql> SELECT * FROM tb1 -> WHERE -> id IN (SELECT id FROM tb WHERE sales >= 200); +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C004 | 青山 | 1967-09-17 | +------+------+------------+ 3 rows in set (0.00 sec)
上記結果で、sales の値が 200 以上で 312 の C007 が表示されないのは、C007 が tb1 に存在しないためです。
sales の値が 200 以上の全てのレコードを表示させるには、例えば以下のように左外部結合(LEFT JOIN)を使う方法があります。但し、C007 には、name, birth の値はないので NULL が表示されます。
mysql> SELECT tb.id, tb1.name, tb1.birth FROM tb -> LEFT JOIN tb1 -> USING (id) -> WHERE tb.sales >= 200; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C004 | 青山 | 1967-09-17 | | C007 | NULL | NULL | +------+------+------------+ 4 rows in set (0.00 sec)
以下のように内部結合を使うと、サブクエリを使ったのと同じ結果が得られます。
mysql> SELECT tb.id, tb1.name, tb1.birth FROM tb -> JOIN tb1 -> USING (id) -> WHERE tb.sales >= 200 -> ORDER BY tb.id; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C004 | 青山 | 1967-09-17 | +------+------+------------+ 3 rows in set (0.00 sec)
EXISTS / NOT EXISTS
存在するレコードのみを対象にするには、EXISTS を使用します。EXISTS は、「対象となるレコードが存在する」かどうかの情報を返します。
EXISTS は、サブクエリで取り出されたレコードが存在するかを確認するための演算子です。
サブクエリの前に EXISTS を指定すると、サブクエリがデータを返した場合に条件式が TRUE になります。
EXISTS は基となるテーブルの1行ごとにサブクエリを実行するため、場合によっては高負荷な処理になる可能性もあるので注意が必要です。
以下の2つのテーブル tb, tb1 で、テーブル tb に存在する人の id, name, birth をテーブル tb1 から表示します。
まず、テーブル tb に存在するレコードを抽出し、テーブル tb1 から該当するレコードを表示します。
tb tb1 +------+-------+-------+ +------+------+------------+ | id | sales | month | | id | name | birth | +------+-------+-------+ +------+------+------------+ | C001 | 100 | 4 | | C001 | 山田 | 1980-01-23 | | C003 | 77 | 5 | | C002 | 鈴木 | 1959-12-25 | | C007 | 312 | 4 | | C003 | 田中 | 1978-08-15 | | C002 | 238 | 4 | | C004 | 青山 | 1967-09-17 | | C004 | 98 | 5 | | C005 | 伊東 | 1984-10-10 | | C006 | 156 | 4 | +------+------+------------+ | C001 | 210 | 5 | | C007 | 180 | 5 | | C004 | 222 | 6 | | C003 | 198 | 6 | +------+-------+-------+ mysql> SELECT * FROM tb1 -> WHERE EXISTS -> (SELECT * FROM tb WHERE tb.id = tb1.id); +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C003 | 田中 | 1978-08-15 | | C004 | 青山 | 1967-09-17 | +------+------+------------+ 4 rows in set (0.00 sec)
(SELECT * FROM tb WHERE tb.id = tb1.id) は、両方のテーブルに id が存在するレコードをテーブル tb から抽出しています。そして EXISTS を使って、このレコードが存在するものをテーブル tb1 から抽出しています。
NOT EXISTS
NOT EXISTS は、サブクエリによって抽出されないレコードを対象に処理を行います。
以下では前述の例とは逆に、2つのテーブル tb, tb1 で、テーブル tb に存在しない人の id, name, birth をテーブル tb1 から表示します。
tb tb1
+------+-------+-------+ +------+------+------------+
| id | sales | month | | id | name | birth |
+------+-------+-------+ +------+------+------------+
| C001 | 100 | 4 | | C001 | 山田 | 1980-01-23 |
| C003 | 77 | 5 | | C002 | 鈴木 | 1959-12-25 |
| C007 | 312 | 4 | | C003 | 田中 | 1978-08-15 |
| C002 | 238 | 4 | | C004 | 青山 | 1967-09-17 |
| C004 | 98 | 5 | | C005 | 伊東 | 1984-10-10 |
| C006 | 156 | 4 | +------+------+------------+
| C001 | 210 | 5 |
| C007 | 180 | 5 |
| C004 | 222 | 6 |
| C003 | 198 | 6 |
+------+-------+-------+
mysql> SELECT * FROM tb1
-> WHERE NOT EXISTS
-> (SELECT * FROM tb WHERE tb.id = tb1.id);
+------+------+------------+
| id | name | birth |
+------+------+------------+
| C005 | 伊東 | 1984-10-10 |
+------+------+------------+
1 row in set (0.00 sec)
順位付け
以下は、サブクエリと AUTO_INCREMENT(連続番号機能)を使った順位付けの方法の1つです。自己結合を使った順位付けよりもわかりやすいです。
以下のテーブル tb を sales の値の大きい順に順位を付けてみます。
mysql> DESC tb; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | varchar(10) | YES | | NULL | | | sales | int(11) | YES | | NULL | | | month | int(11) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.04 sec) mysql> SELECT * FROM tb; +------+-------+-------+ | id | sales | month | +------+-------+-------+ | C001 | 100 | 4 | | C003 | 77 | 5 | | C007 | 312 | 4 | | C002 | 238 | 4 | | C004 | 98 | 5 | | C006 | 156 | 4 | | C001 | 210 | 5 | | C007 | 180 | 5 | | C004 | 222 | 6 | | C003 | 198 | 6 | +------+-------+-------+ 10 rows in set (0.00 sec)
以下の手順で処理します。
- テーブル tb と同じ構造のテーブル tbr を作成
- テーブル tbr に連続番号機能のあるカラム rank を追加
- テーブル tb を sales の順に表示(SELECT)するサブクエリを実行
- サブクエリの結果をテーブル tbr に挿入(INSERT)
mysql> CREATE TABLE tbr LIKE tb;
Query OK, 0 rows affected (0.04 sec)
mysql> ALTER TABLE tbr ADD rank INT AUTO_INCREMENT PRIMARY KEY;
Query OK, 0 rows affected (0.08 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> INSERT INTO tbr (id, sales, month)
-> (SELECT id, sales, month FROM tb ORDER BY sales DESC);
Query OK, 10 rows affected (0.00 sec)
Records: 10 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM tbr;
+------+-------+-------+------+
| id | sales | month | rank |
+------+-------+-------+------+
| C007 | 312 | 4 | 1 |
| C002 | 238 | 4 | 2 |
| C004 | 222 | 6 | 3 |
| C001 | 210 | 5 | 4 |
| C003 | 198 | 6 | 5 |
| C007 | 180 | 5 | 6 |
| C006 | 156 | 4 | 7 |
| C001 | 100 | 4 | 8 |
| C004 | 98 | 5 | 9 |
| C003 | 77 | 5 | 10 |
+------+-------+-------+------+
10 rows in set (0.00 sec)
ビュー VIEW
ビューとは仮想のテーブルのようなもので、SELECT した結果をあたかもテーブルのようにして残しておくことができます。
ビューを使えば複数のテーブルを結合したり、抽出条件が複雑な SELECT 文でも、好きな条件でデータを集めることができます。
また、一度ビューを作成してしまえば、普通のテーブルと同じように利用できます。
ビューの作成
以下は基本的なビューの作成(定義)方法です。
CREATE VIEW ビューの名前 AS SELECT カラム名 FROM テーブル名 WHERE 等の条件;
「SELECT したものを、ビューとして作成する」という構文になります。
条件には、ORDER BY, LIMIT, JOIN など何でも指定可能です。
何らかの条件でカラムを集め、仮想的なテーブルを作成します。
レコードを表示
SELECT でレコードを表示させるには、テーブルと同様に以下のようにします。
SELECT カラム名 FROM ビューの名前;
以下は、テーブル tb1 から name と birth のカラムだけで構成するビュー v1 を作成し、表示する例です。
mysql> SELECT * FROM tb1; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C003 | 田中 | 1978-08-15 | | C004 | 青山 | 1967-09-17 | | C005 | 伊東 | 1984-10-10 | +------+------+------------+ 5 rows in set (0.01 sec) mysql> CREATE VIEW v1 AS SELECT name, birth FROM tb1; Query OK, 0 rows affected (0.01 sec) mysql> SELECT * FROM v1; +------+------------+ | name | birth | +------+------------+ | 山田 | 1980-01-23 | | 鈴木 | 1959-12-25 | | 田中 | 1978-08-15 | | 青山 | 1967-09-17 | | 伊東 | 1984-10-10 | +------+------------+ 5 rows in set (0.00 sec)
条件を設定したビューの作成
以下は2つのテーブルから、条件を設定してビューを作成する例です。
2つのテーブル tb, tb1 を結合し、tb のカラム sales の値が200以上の人の id, name, sales を表示するビューを作成します。
tb tb1
+------+-------+-------+ +------+------+------------+
| id | sales | month | | id | name | birth |
+------+-------+-------+ +------+------+------------+
| C001 | 100 | 4 | | C001 | 山田 | 1980-01-23 |
| C003 | 77 | 5 | | C002 | 鈴木 | 1959-12-25 |
| C007 | 312 | 4 | | C003 | 田中 | 1978-08-15 |
| C002 | 238 | 4 | | C004 | 青山 | 1967-09-17 |
| C004 | 98 | 5 | | C005 | 伊東 | 1984-10-10 |
| C006 | 156 | 4 | +------+------+------------+
| C001 | 210 | 5 |
| C007 | 180 | 5 |
| C004 | 222 | 6 |
| C003 | 198 | 6 |
+------+-------+-------+
mysql> CREATE VIEW v2 AS SELECT tb.id, tb1.name, tb.sales
-> FROM tb
-> JOIN tb1 USING (id)
-> WHERE tb.sales >= 200;
Query OK, 0 rows affected (0.03 sec)
mysql> SELECT * FROM v2;
+------+------+-------+
| id | name | sales |
+------+------+-------+
| C002 | 鈴木 | 238 |
| C001 | 山田 | 210 |
| C004 | 青山 | 222 |
+------+------+-------+
3 rows in set (0.02 sec)
ビューの確認
作成したビューを確認するには、SHOW TABLES を使います。基本的にビューとテーブルの扱いは同じです。
mysql> SHOW TABLES; +---------------+ | Tables_in_db1 | +---------------+ | tb | | tb1 | ・・・中略・・・ | tbx | | tby | | v1 | | v2 | +---------------+ 18 rows in set (0.00 sec)
ビューのカラム構造の確認
テーブル同様、カラム構造は DESC (または DESCRIBE) で確認できます。
mysql> DESC v2; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | varchar(10) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | | sales | int(11) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.04 sec)
ビューの詳細情報の表示
ビューの詳細情報を表示するには、SHOW CREATE VIEW を使用します。表示結果は1行に表示されるデータが多いため、最後の「;」の代わりに「\G」を使用すると見やすくなります。
mysql> SHOW CREATE VIEW v2 \G
*************************** 1. row ***************************
View: v2
Create View: CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost` SQL
SECURITY DEFINER VIEW `v2` AS select `tb`.`id` AS `id`,`tb1`.`name` AS `name`,`t
b`.`sales` AS `sales` from (`tb` join `tb1` on((`tb`.`id` = `tb1`.`id`))) where
(`tb`.`sales` >= 200)
character_set_client: cp932
collation_connection: cp932_japanese_ci
1 row in set (0.00 sec)
ビューの更新
ビューは、元となるテーブルの一部を表示しているので、テーブルの値が更新されるとビューの値も更新されます。
また、逆にビューの値を更新すると、その元となるテーブルの値も更新されます。
ビューの値の更新は、テーブルの更新と同様に、UPDATE SET を使用します。
UPDATE ビュー名 SET カラム名 = 設定する値 WHERE 条件等;
以下は、ビュー v1 の「山田」を「森」に変更する例です。変更後のビュー v1 及びその元となるテーブル tb1 を確認するとどちらも更新されていることが確認できます。
mysql> SELECT * FROM v1; +------+------------+ | name | birth | +------+------------+ | 山田 | 1980-01-23 | | 鈴木 | 1959-12-25 | | 田中 | 1978-08-15 | | 青山 | 1967-09-17 | | 伊東 | 1984-10-10 | +------+------------+ 5 rows in set (0.00 sec) mysql> UPDATE v1 SET name = "森" WHERE name = "山田"; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> SELECT * FROM v1; +------+------------+ | name | birth | +------+------------+ | 森 | 1980-01-23 | | 鈴木 | 1959-12-25 | | 田中 | 1978-08-15 | | 青山 | 1967-09-17 | | 伊東 | 1984-10-10 | +------+------------+ 5 rows in set (0.00 sec) mysql> SELECT * FROM tb1; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 森 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C003 | 田中 | 1978-08-15 | | C004 | 青山 | 1967-09-17 | | C005 | 伊東 | 1984-10-10 | +------+------+------------+ 5 rows in set (0.00 sec)
以下は、テーブル tb1 の「森」を「山田」に変更する例です。変更後のビュー v1 を確認すると、テーブルの変更が反映されていることが確認できます。
mysql> UPDATE tb1 SET name = "山田" WHERE name = "森"; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> SELECT * FROM v1; +------+------------+ | name | birth | +------+------------+ | 山田 | 1980-01-23 | | 鈴木 | 1959-12-25 | | 田中 | 1978-08-15 | | 青山 | 1967-09-17 | | 伊東 | 1984-10-10 | +------+------------+ 5 rows in set (0.00 sec)
更新ができないビュー
ビューが更新可能であるためには、そのビュー内の行とベースとなるテーブル内の行の間に 1 対 1 の関係が存在する必要があります。また、ビューを更新不可能にするその他の特定の構造構文も存在します。詳細:「更新可能および挿入可能なビュー」
ビューへの INSERT
ビューへの INSERT には制限があります。 例えば、UNION や JOIN,サブクエリなどを使っているビューでは、INSERT や UPDATE はできません(UPDATE はできる場合もあります)。ただし、単純に1つのテーブルからカラムを抜き出したものならば、問題なく INSERT も UPDATE も可能です。詳細:「更新可能および挿入可能なビュー」
ビューは、元になるテーブルから自由にカラムを集めたものなので、ビューとして見えている部分は、元のテーブルの一部であることが多いはずです。 ビューに INSERT するということは、テーブルの一部だけにデータを挿入するということになります。データを挿入してないカラムには NULL が挿入されます。
以下はテーブル tb1 を元に作成したビュー v1 にデータを挿入する例です。
mysql> SELECT * FROM tb1;
+------+------+------------+
| id | name | birth |
+------+------+------------+
| C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 |
| C005 | 伊東 | 1984-10-10 |
+------+------+------------+
5 rows in set (0.00 sec)
mysql> SELECT * FROM v1;
+------+------------+
| name | birth |
+------+------------+
| 山田 | 1980-01-23 |
| 鈴木 | 1959-12-25 |
| 田中 | 1978-08-15 |
| 青山 | 1967-09-17 |
| 伊東 | 1984-10-10 |
+------+------------+
5 rows in set (0.00 sec)
mysql> INSERT INTO v1 VALUES ('中瀬', '1952-03-07');
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM v1;
+------+------------+
| name | birth |
+------+------------+
| 山田 | 1980-01-23 |
| 鈴木 | 1959-12-25 |
| 田中 | 1978-08-15 |
| 青山 | 1967-09-17 |
| 伊東 | 1984-10-10 |
| 中瀬 | 1952-03-07 |
+------+------------+
6 rows in set (0.00 sec)
mysql> SELECT * FROM tb1;
+------+------+------------+
| id | name | birth |
+------+------+------------+
| C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 |
| C005 | 伊東 | 1984-10-10 |
| NULL | 中瀬 | 1952-03-07 |
+------+------+------------+
6 rows in set (0.00 sec)
データが挿入されていない元のテーブル tb1 のカラム id には NULL が入っているのが確認できます。
条件の合わないデータの挿入
テーブル tb から、カラム sales の値が200以上の人の id, sales を表示するビュー v3 を作成します。
mysql> SELECT * FROM tb;
+------+-------+-------+
| id | sales | month |
+------+-------+-------+
| C001 | 100 | 4 |
| C003 | 77 | 5 |
| C007 | 312 | 4 |
| C002 | 238 | 4 |
| C004 | 98 | 5 |
| C006 | 156 | 4 |
| C001 | 210 | 5 |
| C007 | 180 | 5 |
| C004 | 222 | 6 |
| C003 | 198 | 6 |
+------+-------+-------+
10 rows in set (0.00 sec)
mysql> CREATE VIEW v3 AS SELECT id, sales FROM tb
-> WHERE sales >= 200;
Query OK, 0 rows affected (0.02 sec)
mysql> SELECT * FROM v3;
+------+-------+
| id | sales |
+------+-------+
| C007 | 312 |
| C002 | 238 |
| C001 | 210 |
| C004 | 222 |
+------+-------+
4 rows in set (0.00 sec)
このビュー v3 に、条件に合わないレコード(sales が 200未満)を挿入すると、以下のようになります。
mysql> INSERT INTO v3 VALUES ('C009', 33);
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM v3;
+------+-------+
| id | sales |
+------+-------+
| C007 | 312 |
| C002 | 238 |
| C001 | 210 |
| C004 | 222 |
+------+-------+
4 rows in set (0.00 sec)
mysql> SELECT * FROM tb;
+------+-------+-------+
| id | sales | month |
+------+-------+-------+
| C001 | 100 | 4 |
| C003 | 77 | 5 |
| C007 | 312 | 4 |
| C002 | 238 | 4 |
| C004 | 98 | 5 |
| C006 | 156 | 4 |
| C001 | 210 | 5 |
| C007 | 180 | 5 |
| C004 | 222 | 6 |
| C003 | 198 | 6 |
| C009 | 33 | NULL |
+------+-------+-------+
11 rows in set (0.00 sec)
問題なく挿入されてしまいましたが、ビュー v3 の条件(sales が 200以上)を満たしていないため、ビュー v3 には表示されませんが、元のテーブル tb には表示され、挿入されていることが確認できます。
条件に合わない場合はエラーに
ビューからの INSERT では、WHERE による条件に合わなくても、元のテーブルにはそのまま入力されてしまいます。
WHERE の条件と合わない場合に、入力ができないように設定するには CREATE VIEW でビューを作るとき、WITH CHECK OPTION を付けて実行します。
このオプションを付けると、WHERE の条件と合わない INSERT を行った場合、以下のようにエラーになります。
mysql> SELECT * FROM tb;
+------+-------+-------+
| id | sales | month |
+------+-------+-------+
| C001 | 100 | 4 |
| C003 | 77 | 5 |
| C007 | 312 | 4 |
| C002 | 238 | 4 |
| C004 | 98 | 5 |
| C006 | 156 | 4 |
| C001 | 210 | 5 |
| C007 | 180 | 5 |
| C004 | 222 | 6 |
| C003 | 198 | 6 |
+------+-------+-------+
11 rows in set (0.00 sec)
mysql> CREATE VIEW v4 AS SELECT id, sales FROM tb
-> WHERE sales >= 200
-> WITH CHECK OPTION;
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO v4 VALUES ('C009', 33);
ERROR 1369 (HY000): CHECK OPTION failed 'db1.v4'
ビューの上書き・変更・削除
ビューの上書き
同じ名前のビューがすでに存在する場合に、CREATE VIEW を実行すとエラーになります。
このような場合は CREATE OR REPLACE VIEW~ のように OR REPLACE を付ければ、上書きすることができます(すでに存在する同名のビューを削除して、新しくビューを作成)。
以下は、既存のビュー v1 を上書きする例です。
mysql> SELECT * FROM v1;
+------+------------+
| name | birth |
+------+------------+
| 山田 | 1980-01-23 |
| 鈴木 | 1959-12-25 |
| 田中 | 1978-08-15 |
| 青山 | 1967-09-17 |
| 伊東 | 1984-10-10 |
| 中瀬 | 1952-03-07 |
+------+------------+
6 rows in set (0.00 sec)
mysql> CREATE OR REPLACE VIEW v1
-> AS SELECT * FROM tb1;
Query OK, 0 rows affected (0.01 sec)
mysql> SELECT * FROM v1;
+------+------+------------+
| id | name | birth |
+------+------+------------+
| C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 |
| C005 | 伊東 | 1984-10-10 |
| NULL | 中瀬 | 1952-03-07 |
+------+------+------------+
6 rows in set (0.00 sec)
ビューの変更
ビューの定義を変更するには、ALTER VIEW を使用します。書式はビューの作成で使用する CREATE VIEW とほぼ同じです。
ALTER VIEW ビューの名前 AS SELECT カラム名 FROM テーブル名;
以下は VIEW v1 を変更する例です。
mysql> SELECT * FROM v1;
+------+------+------------+
| id | name | birth |
+------+------+------------+
| C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 |
| C005 | 伊東 | 1984-10-10 |
| NULL | 中瀬 | 1952-03-07 |
+------+------+------------+
6 rows in set (0.00 sec)
mysql> ALTER VIEW v1
-> AS SELECT id, name
-> FROM tb1;
Query OK, 0 rows affected (0.01 sec)
mysql> SELECT * FROM v1;
+------+------+
| id | name |
+------+------+
| C001 | 山田 |
| C002 | 鈴木 |
| C003 | 田中 |
| C004 | 青山 |
| C005 | 伊東 |
| NULL | 中瀬 |
+------+------+
6 rows in set (0.00 sec)
ビューの削除
ビューの削除も DROP を使用します。以下が書式です。
DROP VIEW ビューの名前;
削除の対象となるビューが存在しなければエラーになります。「IF EXISTS」をつけておけば、対象となるビューが存在しなくてもエラーにはならず、単純に削除が実行されません。
mysql> DROP VIEW IF EXISTS v3; Query OK, 0 rows affected (0.00 sec)
ストアドプロシージャー
ストアドプロシージャーは、一連の SQL 文や処理に名前をつけてサーバ側に保存し、それを「CALL ストアドプロシージャー名」というコマンドで実行することができます。(バージョン5.0以降)
作成・実行
ストアドプロシージャーを作成するには、CREATE PROCEDURE ステートメントを使います。
CREATE PROCEDURE および CREATE FUNCTION 構文
以下が書式です。ストアドプロシージャー名の後には必ず () を付けます。
CREATE PROCDURE ストアドプロシージャー名() BEGIN SQL文 SQL文 ・・・ END
BEGIN から END までが、ストアドプロシージャーでの本体になります。
ストアドプロシージャーの本体は、通常の SQL 文の集まりです。各 SQL 文の最後にはデリミタ「;」をつけますが、デリミタが入力されるとそこまでの部分を実行してしまうので、通常はデリミタを変更して終了後に元のデリミタ「;」に戻します。
そのため、ストアドプロシージャーを作成するときには、あらかじめデリミタを「;」から別のものに変えておきます。一般的には「//」を使います。
デリミタを変更するには、DELIMITER コマンドを使用します。
DELIMITER // → デリミタを「//」に変更 CREATE PROCDURE ストアドプロシージャー名() BEGIN SQL文 SQL文 ・・・ END // → デリミタ「//」により処理が実行される DELIMITER; → デリミタを元の「;」に戻す
以下は、SELECT 文を2回続けて実行するストアドプロシージャーの例です。
mysql> DELIMITER //
mysql> CREATE PROCEDURE prc1()
-> BEGIN
-> SELECT * FROM tb;
-> SELECT * FROM tb1;
-> END
-> //
Query OK, 0 rows affected (0.05 sec)
mysql> DELIMITER ;
ストアドプロシージャーの実行
ストアドプロシージャーを実行するには CALL を使います。以下が書式です。
CALL ストアドプロシージャー名;
以下は、前述の例で作成したストアドプロシージャー(prc1)を実行する例です。
mysql> CALL prc1(); +------+-------+-------+ | id | sales | month | +------+-------+-------+ | C001 | 100 | 4 | ・・・・・中略・・・・・ | C004 | 222 | 6 | | C003 | 198 | 6 | +------+-------+-------+ 10 rows in set (0.02 sec) +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | ・・・・・中略・・・・・ | NULL | 中瀬 | 1952-03-07 | +------+------+------------+ 6 rows in set (0.05 sec) Query OK, 0 rows affected (0.07 sec)
引数の指定
ストアドプロシージャーの引数には入力用(IN)や出力用(OUT)、入出力用(INOUT)の引数があります。
引数の指定は、括弧()内に引数名とそのデータ型を記述します。引数はデフォルトでは入力用(IN)です。それ以外の引数を指定するには、引数名の前にキーワード OUT または INOUT を使用します。
引数名は大文字と小文字が区別されません。
入力用引数
通常の引数の指定です。
ストアドプロシージャーの(入力用)引数は以下のように指定します。入力用の場合、IN は省略可能です。
CREATE PROCEDURE ストアドプロシージャ名(IN 引数名 データ型);
以下は、テーブル tb でカラム sales の値が引数で指定した値以上のレコードを表示する例です。
mysql> DELIMITER //
mysql> CREATE PROCEDURE prc2(x INT)
-> BEGIN
-> SELECT * FROM tb WHERE sales >= x;
-> END
-> //
Query OK, 0 rows affected (0.00 sec)
mysql> DELIMITER ;
mysql> CALL prc2(200);
+------+-------+-------+
| id | sales | month |
+------+-------+-------+
| C007 | 312 | 4 |
| C002 | 238 | 4 |
| C001 | 210 | 5 |
| C004 | 222 | 6 |
+------+-------+-------+
4 rows in set (0.00 sec)
Query OK, 0 rows affected (0.02 sec)
mysql> SELECT * FROM tb;
+------+-------+-------+
| id | sales | month |
+------+-------+-------+
| C001 | 100 | 4 |
| C003 | 77 | 5 |
| C007 | 312 | 4 |
| C002 | 238 | 4 |
| C004 | 98 | 5 |
| C006 | 156 | 4 |
| C001 | 210 | 5 |
| C007 | 180 | 5 |
| C004 | 222 | 6 |
| C003 | 198 | 6 |
+------+-------+-------+
10 rows in set (0.00 sec)
出力用引数
ストアドプロシージャーの出力用引数は以下のように指定します。
CREATE PROCEDURE ストアドプロシージャ名(OUT 引数名 データ型);
出力用引数(OUT)の場合、プロシージャーを呼び出す CALL ステートメントでユーザー定義変数を渡して、プロシージャーから戻ったときにその値を取得できるようにします。
以下は出力用引数があるストアドプロシージャーの定義とその実行例です。
SELECT ... INTO 構文で取得した値を出力引数 y に代入しています。
ストアドプロシージャを実行する際に変数 @count を引数に渡すことで、この変数に出力が格納されます。格納された値はそのあとに SELECT することで参照することができます。
mysql> DELIMITER //
mysql> CREATE PROCEDURE prc3(OUT y INT)
-> BEGIN
-> SELECT COUNT(*) INTO y FROM tb WHERE sales < 200;
-> END
-> //
Query OK, 0 rows affected (0.00 sec)
mysql> DELIMITER ;
mysql> CALL prc3(@count);
Query OK, 1 row affected (0.00 sec)
mysql> SELECT @count;
+--------+
| @count |
+--------+
| 6 |
+--------+
1 row in set (0.00 sec)
確認・削除
以下は登録されているストアドプロシージャを一覧表示する書式です。
SHOW PROCEDURE STATUS;
以下は実行例です。見やすくするために \G を使用しています。
Db でデータベース名が表示されています。ストアドプロシージャー(またはストアドファンクション)は、特定のデータベースに関連付けられています。
mysql> SHOW PROCEDURE STATUS \G
*************************** 1. row ***************************
Db: db1
Name: prc1
Type: PROCEDURE
Definer: root@localhost
Modified: 2016-06-26 16:56:57
Created: 2016-06-26 16:56:57
Security_type: DEFINER
Comment:
character_set_client: cp932
collation_connection: cp932_japanese_ci
Database Collation: utf8_general_ci
*************************** 2. row ***************************
Db: db1
Name: prc2
Type: PROCEDURE
Definer: root@localhost
Modified: 2016-06-26 18:17:01
Created: 2016-06-26 18:17:01
Security_type: DEFINER
Comment:
character_set_client: cp932
collation_connection: cp932_japanese_ci
Database Collation: utf8_general_ci
3 rows in set (0.01 sec)
ストアドプロシージャーの内容確認
以下は、作成したストアドプロシージャーの内容を表示する書式です。
SHOW CREATE PROCEDURE ストアドプロシージャー名;
以下は前述で作成したストアドプロシージャー prc2 の内容を表示する例です。
mysql> SHOW CREATE PROCEDURE prc2\G
*************************** 1. row ***************************
Procedure: prc2
sql_mode: NO_ENGINE_SUBSTITUTION
Create Procedure: CREATE DEFINER=`root`@`localhost` PROCEDURE `prc2`(x INT)
BEGIN
SELECT * FROM tb WHERE sales >= x;
END
character_set_client: cp932
collation_connection: cp932_japanese_ci
Database Collation: utf8_general_ci
1 row in set (0.00 sec)
削除
ストアドプロシージャーを削除するには、「DROP」コマンドを使います。
DROP PROCEDURE ストアドプロシージャー名;
以下は、ストアドプロシージャー prc3 を削除する例です。
mysql> DROP PROCEDURE prc3; Query OK, 0 rows affected (0.00 sec)
ストアドファンクション
ストアドファンクションは、基本的にはストアドプロシージャと同じですが以下の点が異なります。
- ストアドファンクションは実行したときに値(戻り値)を返します。
- ストアドファンクションでは引数は常に入力用引数(IN)と見なされます。
(引数に IN, OUT の指定が不要)
「ファンクション」は関数という意味です。また、ストアドファンクションもバージョン5.0以降で利用可能です。
CREATE PROCEDURE および CREATE FUNCTION 構文
以下のような構文でストアドファンクションを作成することができます。
CREATE FUNCTION ストアドファンクション名(引数 データ型) RETURNS 返す値のデータ型 BEGIN SQL文・・・ RETURN 返す値・式 END
また、ストアドプロシージャーと同様、通常はデリミタを「//」などに変更して終了後に元のデリミタ「;」に戻します。
ストアドファンクションで返された値(戻り値)は、SELECT や UPDATE などのコマンドで、通常の関数と同じように利用することができます。
以下は、引数で指定された値の二乗を返す簡単なストアドファンクションの例です。
mysql> DELIMITER //
mysql> CREATE FUNCTION my_square(n INT) RETURNS INT
-> BEGIN
-> RETURN n * n;
-> END
-> //
Query OK, 0 rows affected (0.00 sec)
mysql> DELIMITER ;
この例では、引数の型と戻り値の型を整数型(INT)にしています。少数なども扱う場合は、浮動小数点数型(DOUBLE)等にします。
ストアドファンクションの返す値を表示するには、SELECT コマンドを使います。
mysql> SELECT my_square(15); +---------------+ | my_square(15) | +---------------+ | 225 | +---------------+ 1 row in set (0.00 sec)
変数の定義
変数は値を保管する入れ物のようなものです。変数を定義するには DECLARE を使います。
DECLARE 変数名 データ型;
平均値を返すストアドファンクションの例
以下のようなテーブル tb があります。
mysql> SELECT * FROM tb; +------+-------+-------+ | id | sales | month | +------+-------+-------+ | C001 | 100 | 4 | | C003 | 77 | 5 | | C007 | 312 | 4 | | C002 | 238 | 4 | | C004 | 98 | 5 | | C006 | 156 | 4 | | C001 | 210 | 5 | | C007 | 180 | 5 | | C004 | 222 | 6 | | C003 | 198 | 6 | +------+-------+-------+ 10 rows in set (0.00 sec)
以下は、テーブル tb のカラム sales の平均値を返すストアドファンクション my_avg() の例です。
mysql> DELIMITER //
mysql> CREATE FUNCTION my_avg() RETURNS DOUBLE
-> BEGIN
-> DECLARE a DOUBLE;
-> SELECT AVG(sales) INTO a FROM tb;
-> RETURN a;
-> END
-> //
Query OK, 0 rows affected (0.00 sec)
mysql> DELIMITER ;
このストアドファンクションの戻り値は平均なので少数になる可能性があるので、DOUBLE 型を指定しています。
DECLARE a DOUBLE; で a という変数を DOUBLE 型で定義します。
テーブル tb のカラム sales の平均を取り出すには、AVG() 関数を使って以下のようになります。
SELECT AVG(sales) FROM tb;
平均値 AVG(sales) を変数 a に代入するには INTO を使用して以下のようにします。
SELECT AVG(sales) INTO a FROM tb;
そして変数 a に代入された値を RETURNS を使ってストアドファンクションの値として返します。
戻り値を表示するには、SELECT コマンドを使います。
mysql> SELECT my_avg(); +----------+ | my_avg() | +----------+ | 179.1 | +----------+ 1 row in set (0.00 sec)
ストアドファンクションの削除
ストアドファンクションを削除するには、DROP を使用します。以下が書式です。
DROP FUNCTION ストアドファンクション名;
ストアドファンクションの一覧を表示
以下が、MySQL に登録されている全てのストアドファンクションを一覧で表示するコマンドです。
SHOW FUNCTION STATUS;
但し、この方法だと実行結果で表示されるカラム数が多く、通常のコンソールだと表示が崩れるので \G オプションを使用します。
mysql> SHOW FUNCTION STATUS \G
*************************** 1. row ***************************
Db: db1
Name: my_avg
Type: FUNCTION
Definer: root@localhost
Modified: 2016-06-29 21:39:49
Created: 2016-06-29 21:39:49
Security_type: DEFINER
Comment:
character_set_client: cp932
collation_connection: cp932_japanese_ci
Database Collation: utf8_general_ci
*************************** 2. row ***************************
Db: db1
Name: my_square
Type: FUNCTION
Definer: root@localhost
Modified: 2016-06-29 20:00:33
Created: 2016-06-29 20:00:33
Security_type: DEFINER
Comment:
character_set_client: cp932
collation_connection: cp932_japanese_ci
Database Collation: utf8_general_ci
2 rows in set (0.04 sec)
ストアドファンクションの内容を表示
以下がストアドファンクションの内容を表示する書式です。
SHOW CREATE FUNCTION ストアドファンクション名;
SHOW FUNCTION STATUS 同様、実行結果で表示されるカラム数が多いため、表示が崩れるので \G オプションを使用して表示する例です。
mysql> SHOW CREATE FUNCTION my_avg \G
*************************** 1. row ***************************
Function: my_avg
sql_mode: NO_ENGINE_SUBSTITUTION
Create Function: CREATE DEFINER=`root`@`localhost` FUNCTION `my_avg`() RETURNS double
BEGIN
DECLARE a DOUBLE;
SELECT AVG(sales) INTO a FROM tb;
RETURN a;
END
character_set_client: cp932
collation_connection: cp932_japanese_ci
Database Collation: utf8_general_ci
1 row in set (0.00 sec)
トリガー
トリガー(Trigger)とは、テーブルに対してある処理(挿入、更新、または削除)が行なわれるとあらかじめ設定した処理を自動的に実行する仕組みで、バージョン5.0以降で利用可能です。
トリガーには INSERT、UPDATE、DELETE の3種類が用意されています。
トリガーが呼び出されるタイミング
トリガーはテーブルに対して「INSERT」「UPDATE」「DELETE」などのコマンドが実行される直前「BEFROE」、または実行した直後「AFTER」に、呼び出されて実行します。
- BEFORE:テーブルに対する処理が行なわれる直前に呼び出されます
- AFTER:テーブルに対する処理が行なわれた直後に呼び出されます
また、テーブルに対する処理が行なわれる直前と直後の値は、以下のように「OLD.カラム名」「NEW.カラム名」で取得できます。
- OLD.カラム名:テーブルに対する処理が行なわれる直前の「カラム名」の値
- NEW.カラム名:テーブルに対する処理が行なわれた直後の「カラム名」の値
但し、コマンドによって取り出されるものと取り出せないものがあります。(以下表で○が取り出すことができるものです)
| コマンド | 実行前(OLD.カラム名)/BEFORE | 実行後(NEW.カラム名)/AFTER |
|---|---|---|
| INSERT | X(古い行はない) | ○ |
| UPDATE | ○ | ○ |
| DELETE | ○ | X(新しい行はない) |
トリガーの構文
以下がトリガーの構文です。
CREATE TRIGGER トリガー名 BEFROE(またはAFTER) INSERTなどのコマンド※ ON テーブル名 FOR EACH ROW BEGIN 更新(OLD.カラム名)または更新後(NEW.カラム名)を使った処理 END
※コマンドは、トリガーイベント、つまりトリガーを実行する操作の種類(INSERT、UPDATE、DELETE)を指定します。
FOR EACH ROW は、対象のテーブルに対しデータが1行処理される度にトリガが1回実行されるというような意味になります。
FOR EACH ROW に続く(BEGIN と END の間の)部分に、トリガー本体(処理)を定義します。
また、ストアドプロシージャーなどと同様、通常はデリミタを「//」などに変更して終了後に元のデリミタ「;」に戻します。
トリガーの作成
以下は、テーブル tb1 のレコードを削除(DELETE)したら、削除したレコードを tb1_tr に挿入(INSERT)するトリガー trg1 を作成する例です。
テーブル tb1 と tb1_tr は以下のようになっています。
mysql> SELECT * FROM tb1; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C003 | 田中 | 1978-08-15 | | C004 | 青山 | 1967-09-17 | | C005 | 伊東 | 1984-10-10 | | NULL | 中瀬 | 1952-03-07 | +------+------+------------+ 6 rows in set (0.01 sec) mysql> CREATE TABLE tb1_tr LIKE tb1; Query OK, 0 rows affected (0.04 sec) mysql> DESC tb1_tr; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | varchar(10) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | | birth | date | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.02 sec)
テーブル tb1 のレコードを削除(DELETE)したら、削除したレコードを tb1_tr に挿入(INSERT)するトリガー trg1
mysql> DELIMITER //
mysql> CREATE TRIGGER trg1 BEFORE DELETE ON tb1
-> FOR EACH ROW
-> BEGIN
-> INSERT INTO tb1_tr VALUES(OLD.id, OLD.name, OLD.birth);
-> END
-> //
Query OK, 0 rows affected (0.02 sec)
mysql> DELIMITER ;
テーブル tb1 に対する DELETE(削除)をきっかけ(トリガーイベント)とするトリガー trg1 を設定します。
トリガーの内容は、レコードを削除する前(BEFORE)の値(OLD.id, OLD.name, OLD.birth)をテーブル tb1_tr に挿入するというものです。
以下は、テーブル tb1 のレコードを削除して上記のトリガーが実行されるかを確かめる例です。
mysql> SELECT * FROM tb1; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C003 | 田中 | 1978-08-15 | | C004 | 青山 | 1967-09-17 | | C005 | 伊東 | 1984-10-10 | | NULL | 中瀬 | 1952-03-07 | +------+------+------------+ 6 rows in set (0.01 sec) mysql> DELETE FROM tb1 WHERE id IS NULL; レコードを削除 Query OK, 1 row affected (0.01 sec) mysql> SELECT * FROM tb1_tr; +------+------+------------+ | id | name | birth | +------+------+------------+ | NULL | 中瀬 | 1952-03-07 | +------+------+------------+ 1 row in set (0.00 sec) mysql> SELECT * FROM tb1; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C003 | 田中 | 1978-08-15 | | C004 | 青山 | 1967-09-17 | | C005 | 伊東 | 1984-10-10 | +------+------+------------+ 5 rows in set (0.00 sec)
トリガーの削除
トリガーを削除するには、DROP を使用します。以下が書式です。
DROP TRIGGER トリガー名;
トリガーを表示
トリガは自動的に起動するため、意図しない処理が行なわれないように、現在設定されているトリガーを常に把握してく必要があります。
現在設定されているトリガーは以下のコマンドで確認できます。
SHOW TRIGGERS;
但し、実行結果で表示されるカラム数が多いため、通常のコンソールだと表示が崩れるので \G オプションを使用します。
mysql> SHOW TRIGGERS \G
*************************** 1. row ***************************
Trigger: trg1
Event: DELETE
Table: tb1
Statement: BEGIN
INSERT INTO tb1_tr VALUES(OLD.id, OLD.name, OLD.birth);
END
Timing: BEFORE
Created: NULL
sql_mode: NO_ENGINE_SUBSTITUTION
Definer: root@localhost
character_set_client: cp932
collation_connection: cp932_japanese_ci
Database Collation: utf8_general_ci
1 row in set (0.04 sec)
mysql> DROP TRIGGER trg1; トリガーを削除
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW TRIGGERS \G
Empty set (0.02 sec)
トランザクション
トランザクションとは、一連のデータベース操作を1つのまとめた処理として実行できる機能です。
例えば、Aさんが自分の銀行口座からBさんの銀行口座に1,000円を振り込む場合、処理は以下のようになります。
- Aさんの口座の残高が1,000円以上であることを確認します。
- Aさんの口座の残高から1,000円を引きます。
- Bさんの口座の残高に1,000円を足します。
もし、2.の時点でエラーが起きると、Aさんの1,000円はどうなってしまうのでしょうか。
このような場合、「Aさんの口座の残高から1,000円を引く」のと「Bさんの口座の残高に1,000円を足す」のを、「分割できない1つの処理」として扱い、エラーが起きたら取り消す(ロールバック)ようにすれば、1,000円がどこかに行ってしまう事態は回避できます。このように複数の処理をまとめて扱う機能をトランザクションと言います。
トランザクションを始めてから、結果をデータベースに反映させることをコミット、また反映しないで元に戻すことをロールバックと言います。
START TRANSACTION、COMMIT、および ROLLBACK 構文
MySQL には複数のストレージエンジンがあり、トランザクションを利用するには「InnoDB」というストレージエンジンを使用する必要があります。MySQL 5.5 以上では、InnoDB がデフォルトのストレージエンジンです。それ以前では、MyISAM がデフォルトでした。
デフォルトの MySQL ストレージエンジンとしての InnoDB
ストレージエンジンの確認
「SHOW CREATE TABLE」を使うと、テーブルのストレージエンジンを確認することができます。 \G オプションを使用すると見やすくなります。
ENGINE=xxxxx の部分で確認することができます。(この例の場合は InnoDB です)
mysql> SHOW CREATE TABLE tb \G
*************************** 1. row ***************************
Table: tb
Create Table: CREATE TABLE `tb` (
`id` varchar(10) DEFAULT NULL,
`sales` int(11) DEFAULT NULL,
`month` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
ストレージエンジンの設定
新しいテーブルを作成するときに、ENGINE テーブルオプションを CREATE TABLE ステートメントに加えることによって、どのストレージエンジンを利用するかを指定することができます。
CREATE TABLE t1 (i INT) ENGINE = INNODB;
ENGINE オプションを省略した場合、デフォルトのストレージエンジンが使用されます。デフォルトのエンジンは MySQL 5.5 以上では InnoDB です。デフォルトのエンジンを指定するには、--default-storage-engine サーバースタートアップオプションを使用するか、my.cnf (my.ini) 構成ファイルにある default-storage-engine オプションを設定するかします。
ストレージエンジンの変更
テーブルを別のストレージエンジンに変換するには、ALTER TABLE ステートメントを使用します。
ALTER TABLE t ENGINE = InnoDB;
「Query OK」と表示されても、ストレージエンジンが変更されないこともあるので、必ず「SHOW CREATE TABLE」で目的のストレージエンジンに変更されたことを確認します。
トランザクションの開始
トランザクションを開始するには、START TRANSACTION を使います。
mysql> START TRANSACTION; Query OK, 0 rows affected (0.00 sec)
「Query OK」が表示されることを必ず確認します。「Query OK」が表示されないと、トランザクションは働いていないことになるので注意が必要です。
START TRANSACTION; 以降に入力されたSQLクエリはトランザクションとして扱われます。
トランザクションを終了するには コミット(COMMIT:DBに結果を反映)するか ロールバック (ROLLBACK:トランザクション開始前の状態に戻す)します。どちらかを実行した時点でトランザクションは確定し、終了します。
以下はトランザクションを使って、テーブルからレコードを削除し、ロールバックで削除を取り消す例です。
テーブル tb は以下のようになっています。
mysql> SELECT * FROM tb; +------+-------+-------+ | id | sales | month | +------+-------+-------+ | C001 | 100 | 4 | | C003 | 77 | 5 | | C007 | 312 | 4 | | C002 | 238 | 4 | | C004 | 98 | 5 | | C006 | 156 | 4 | | C001 | 210 | 5 | | C007 | 180 | 5 | | C004 | 222 | 6 | | C003 | 198 | 6 | +------+-------+-------+ 10 rows in set (0.00 sec)
START TRANSACTION; でトランザクションを開始します。そしてレコードを削除し、テーブル tb を確認すると、レコードが削除されていることが確認できます。
mysql> START TRANSACTION; Query OK, 0 rows affected (0.00 sec) mysql> DELETE FROM tb WHERE month = 4; Query OK, 4 rows affected (0.00 sec) mysql> SELECT * FROM tb; +------+-------+-------+ | id | sales | month | +------+-------+-------+ | C003 | 77 | 5 | | C004 | 98 | 5 | | C001 | 210 | 5 | | C007 | 180 | 5 | | C004 | 222 | 6 | | C003 | 198 | 6 | +------+-------+-------+ 6 rows in set (0.00 sec)
続いてロールバックを実行すると、元に戻っていることが確認できます。
mysql> ROLLBACK; Query OK, 0 rows affected (0.00 sec) mysql> SELECT * FROM tb; +------+-------+-------+ | id | sales | month | +------+-------+-------+ | C001 | 100 | 4 | | C003 | 77 | 5 | | C007 | 312 | 4 | | C002 | 238 | 4 | | C004 | 98 | 5 | | C006 | 156 | 4 | | C001 | 210 | 5 | | C007 | 180 | 5 | | C004 | 222 | 6 | | C003 | 198 | 6 | +------+-------+-------+ 10 rows in set (0.00 sec)
ロールバックとコミット
何らかの理由で、START TRANSACTION 以降に実行した処理を取り消したい(元に戻す)場合はロールバック(ROLLBACK)します。
ROLLBACK;
ロールバックを実行した時点で、トランザクションは確定します。
処理が問題なく行われて、結果をデータベースに反映するにはコミット(COMMIT)します。
COMMIT;
以下はコミットする例です。コミットすると、START TRANSACTION 以降に実行した処理がデータベースに反映されます。
mysql> SELECT * FROM tb1; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C003 | 田中 | 1978-08-15 | | C004 | 青山 | 1967-09-17 | | C005 | 伊東 | 1984-10-10 | +------+------+------------+ 5 rows in set (0.02 sec) mysql> START TRANSACTION; Query OK, 0 rows affected (0.00 sec) mysql> DELETE FROM tb1 WHERE id = "C005"; Query OK, 1 row affected (0.00 sec) mysql> SELECT * FROM tb1; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C003 | 田中 | 1978-08-15 | | C004 | 青山 | 1967-09-17 | +------+------+------------+ 4 rows in set (0.00 sec) mysql> COMMIT; Query OK, 0 rows affected (0.00 sec) mysql> SELECT * FROM tb1; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C003 | 田中 | 1978-08-15 | | C004 | 青山 | 1967-09-17 | +------+------+------------+ 4 rows in set (0.00 sec)
トランザクションが利用できる範囲
トランザクションによって何でもロールバックで元に戻せるというわけではないので注意が必要です。例えば次のようなコマンドは、自動的にコミットされてしまいます。(※元に戻すことはできません)
- DROP DATABASE
- DROP TABLE
- DROP
- ALTER TABLE
自動コミット機能
MySQL でコマンドを実行すると、通常そのまま処理が確定されます。言い換えると、すべてのコマンドが自動的に「COMMIT」されます。
トランザクションの機能自体が無いストレージエンジン「MyISAM」の場合、すべてのコマンドはコミットされてしまいます。
コマンドが自動的に「COMMIT」される機能を「自動コミット機能」といいます。デフォルトでは、この自動コミット機能はオンになっています。
但し、「START TRANSACTION」を実行すると、「COMMIT」を実行するまではコミットしなくなり、ロールバックで元に戻すことが可能になっています。
自動コミット機能をオフにする
自動コミット機能は、ユーザーがオフにすることができます。「自動コミット機能」をオフにすれば、SQL 文を実行してもコミットされず、 COMMIT を実行した時点で初めてコミットされます。また、ROLLBACK を実行すれば元に戻すことができます。
自動コミット機能をオフにするには、SET AUTOCOMMIT=0; コマンドを実行します。
mysql> SET AUTOCOMMIT = 0; Query OK, 0 rows affected (0.00 sec)
以下は、自動コミット機能をオフにしてロールバックを実行する例です。
mysql> SELECT * FROM tb1;
+------+------+------------+
| id | name | birth |
+------+------+------------+
| C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 |
+------+------+------------+
4 rows in set (0.00 sec)
mysql> SET AUTOCOMMIT = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO tb1 VALUES('C005', 'Smith', '1920-03-22');
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM tb1;
+------+-------+------------+
| id | name | birth |
+------+-------+------------+
| C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 |
| C005 | Smith | 1920-03-22 |
+------+-------+------------+
5 rows in set (0.00 sec)
mysql> ROLLBACK;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM tb1;
+------+------+------------+
| id | name | birth |
+------+------+------------+
| C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 |
+------+------+------------+
4 rows in set (0.00 sec)
変更を確定するには、コミット(COMMIT)を実行します。
mysql> SET AUTOCOMMIT = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO tb1 VALUES('C005', '小川', '1920-03-22');
Query OK, 1 row affected (0.00 sec)
mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM tb1;
+------+------+------------+
| id | name | birth |
+------+------+------------+
| C001 | 山田 | 1980-01-23 |
| C002 | 鈴木 | 1959-12-25 |
| C003 | 田中 | 1978-08-15 |
| C004 | 青山 | 1967-09-17 |
| C005 | 小川 | 1920-03-22 |
+------+------+------------+
5 rows in set (0.00 sec)
※「自動コミット機能」がオフのまま作業を続け、もし「COMMIT」しないで MySQL を終了すれば、その作業内容は反映されないので注意が必要です。
自動コミット機能をオンにする
自動コミット機能を元のオンにするには SET AUTOCOMMIT=1; コマンドを実行します。
mysql> SET AUTOCOMMIT = 1; Query OK, 0 rows affected (0.00 sec)
自動コミット機能の状態を確認
現在の自動コミット機能の状態を確認するには、SELECT @@AUTOCOMMIT を実行します。
オンの場合は「1」、オフの場合は「0」が表示されます。
mysql> SELECT @@AUTOCOMMIT; +--------------+ | @@AUTOCOMMIT | +--------------+ | 1 | +--------------+ 1 row in set (0.00 sec)
ファイルを使った操作
大量のデータをテーブルに入力する場合、MySQLモニタを開いてそのすべてを入力するのは大変です。大量のデータを入力するときは、「CSV」(comma Separated Values)形式のようなテキストファイルを使います。
ファイルのインポート
ファイルからデータをインポートするには LOAD DATA INFILE というコマンドを使います。
CSVファイルが保存されているフォルダを指定するときは、パスは Windows であっても「\」を使わずに「/」を使います。以下が構文です。
LOAD DATA [LOCAL] INFILE ファイル名 INTO TABLE テーブル名 オプション;
LOCAL はオプションです。また上記のオプション部分には以下を指定することができます。(実際にはもっと多くのオプションがあります。「LOAD DATA INFILE 構文」を参照)
FIELDS TERMINATED BY 区切り文字(デフォルト'\t':タブ) LINES TERMINATED BY 改行文字(デフォルト'\n':改行) IGNORE 最初にスキップする行 LINES(デフォルトは0)
-
タブ区切りがデフォルトになっているので、カンマ区切りの CSV を読み込むには FIELDS TERMINATED BY ',' とカンマ区切りである事を指定します。
-
ファイルを Windows で作成した場合、作成に使用したエディタで \r\n が改行文字として使用されているときは、LINES TERMINATED BY '\r\n' とします。
-
IGNORE 1 LINES とすることで、先頭1行を無視することが出来ます。フィールド名を1行目に記述している場合など。
LOCAL キーワード
LOCAL が指定されている場合、ファイルはクライアントホスト上のクライアントプログラムによって読み取られ、サーバーに送信されます。このファイルは、その正確な場所を指定するためにフルパス名として指定できます。相対パス名として指定されている場合、その名前は、クライアントプログラムが起動されたディレクトリを基準にして解釈されます。
LOCAL が指定されていない場合、ファイルはサーバーホスト上にある必要があり、直接サーバーによって読み取られます。サーバーは、次のルールを使用してファイルを見つけます。
- ファイル名が絶対パス名である場合、サーバーはそれを指定されたとおりに使用します。
- ファイル名が 1 つ以上の先行コンポーネントを含む相対パス名である場合、サーバーは、サーバーのデータディレクトリを基準にしてファイルを検索します。
- 先行コンポーネントを含まないファイル名が指定されている場合、サーバーは、デフォルトデータベースのデータベースディレクトリ内でそのファイルを探します。
また、サーバーファイルに対して LOAD DATA INFILE を使用するには、FILE 権限が必要です。LOCAL を使用すると、ローカルファイルをロードするため FILE 権限は必要ありません。
LOCAL はまた、エラー処理にも影響を与えます。
- LOAD DATA INFILE では、データ解釈や重複キーのエラーによって操作が終了します。
- LOAD DATA LOCAL INFILE では、操作の最中にファイルの転送を停止する方法がサーバーにはないため、データ解釈や重複キーのエラーは警告になり、操作は続行されます。
詳細は「LOAD DATA INFILE 構文」を参照。
ファイルのインポートの例
以下のテーブル tb1 にファイルからデータをインポートします。
mysql> DESC tb1; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | varchar(10) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | | birth | date | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.04 sec) mysql> SELECT * FROM tb1; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C003 | 田中 | 1978-08-15 | | C004 | 青山 | 1967-09-17 | | C005 | 小川 | 1920-03-22 | +------+------+------------+ 5 rows in set (0.00 sec)
値は、CREATE TABLE ステートメントに指定したカラムの順序に従って記述する必要があります。
この例では文字コードに UTF-8 を指定しているので、Windows のメモ帳ではなく UTF-8 が使用できるテキストエディタでファイルを作成しています。また、区切り文字はタブを使用しています。
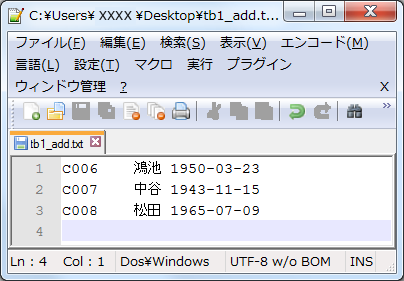
以下はデスクトップに保存した上記ファイルの内容をテーブルにロードする例です。
mysql> LOAD DATA LOCAL INFILE 'Desktop/tb1_add.txt' INTO TAble tb1
-> LINES TERMINATED BY '\r\n';
Query OK, 4 rows affected, 2 warnings (0.01 sec)
Records: 4 Deleted: 0 Skipped: 0 Warnings: 2
「Warnings: 2」と出ているので「SHOW WARNINGS」で確認します。
mysql> SHOW WARNINGS; +---------+------+--------------------------------------------+ | Level | Code | Message | +---------+------+--------------------------------------------+ | Warning | 1261 | Row 4 does not contain data for all columns| | Warning | 1261 | Row 4 does not contain data for all columns| +---------+------+--------------------------------------------+ 2 rows in set (0.00 sec) mysql> SELECT * FROM tb1; +------+------+------------+ | id | name | birth | +------+------+------------+ | C001 | 山田 | 1980-01-23 | | C002 | 鈴木 | 1959-12-25 | | C003 | 田中 | 1978-08-15 | | C004 | 青山 | 1967-09-17 | | C005 | 小川 | 1920-03-22 | | C006 | 鴻池 | 1950-03-23 | | C007 | 中谷 | 1943-11-15 | | C008 | 松田 | 1965-07-09 | | | NULL | NULL | +------+------+------------+ 9 rows in set (0.00 sec) mysql> DELETE FROM tb1 WHERE name IS NULL; Query OK, 1 row affected (0.00 sec)
インポートしたファイルの最後に空の行があったためのエラーであることが確認できます。
前述の例では、LOCAL を指定してファイルを相対パス名として指定(クライアントプログラムが起動されたディレクトリを基準)しましたが、絶対パスで指定することもできます。
mysql> LOAD DATA LOCAL INFILE 'C:/Users/XXXX/Desktop/tb1_add.txt'
-> INTO TABLE tb1
-> LINES TERMINATED BY '\r\n';
Query OK, 1 row affected (0.00 sec)
Records: 1 Deleted: 0 Skipped: 0 Warnings: 0
ファイルのエクスポート
インポートとは逆に、テーブルにあるデータを「CSV」などのテキストファイルとしてエクスポートする(取り出す)ことができます。
エクスポートしたファイルは、別のデータベースなどで利用したり、バックアップとして利用できます。以下が構文です。
SELECT * INTO OUTFILE ファイル名 オプション FROM テーブル名;
上記のオプション部分には以下を指定することができます。(インポートと同じです。)
FIELDS TERMINATED BY 区切り文字(デフォルト'\t':タブ) LINES TERMINATED BY 改行文字(デフォルト'\n':改行) IGNORE 最初にスキップする行 LINES(デフォルトは0)
以下はテーブル tb1 のデータをデスクトップに「tb1_out.txt」としてエクスポートする例です。オプションとして区切り文字を「,」に、改行文字を「\r\n」に指定しています。
mysql> SELECT * INTO OUTFILE "C:/Users/XXXX/Desktop/tb1_out.txt"
-> FIELDS TERMINATED BY ','
-> LINES TERMINATED BY '\r\n'
-> FROM tb1;
Query OK, 8 rows affected (0.01 sec)
上記の場合デスクトップに「tb1_out.txt」としてファイルが保存されます。テキストエディタ等で開いて確認することができます。
また、コマンドプロンプトの「type」コマンド(テキストファイルの内容を表示)で確認することができますが、この例の場合は、UTF-8 なので、コマンドプロンプトの設定を変更する必要があります。
コマンドプロンプトの上の枠で右クリックして「プロパティ」を選択します。「フォント」タブのフォントで「MSゴシック」を選択して OK をクリックします。
「chcp 65001」と入力して、UTF-8 に変更します。
C:\Users\XXXX>chcp 65001
「type」コマンドでファイルを指定して、内容を確認します。
Active code page: 65001 C:\Users\XXXX>type Desktop\tb1_out.txt C001,山田,1980-01-23 C002,鈴木,1959-12-25 C003,田中,1978-08-15 C004,青山,1967-09-17 C005,小川,1920-03-22 C006,鴻池,1950-03-23 C007,中谷,1943-11-15 C008,松田,1965-07-09
デフォルトに戻すには「chcp 932」と入力し、プロパティでフォントを「ラスターフォント」に戻します。それぞれの文字コードのページコードはマイクロソフトの「Code Page Identifiers」で確認できます。
SQL 文をファイルから実行
複雑な SQL 文を実行する場合、一度テキストファイルとして作成し、保存したファイルを SOURCE コマンドを使って実行することができます。
テキストファイルとして SQL 文を保存しておけば、いつでも操作が再現できます。以下が書式です。(SOURCE コマンドは SQL コマンドではないので、最後にセミコロンは不要です)
SOURCE テキストファイル名
以下のようなテキストファイルを作成して保存します。この例では「sql1.txt」と言うファイル名でデスクトップに保存しています。
USE db1; SELECT * FROM tb; SELECT * FROM tb1;
以下を実行すると、上記のコマンドが実行されます。
mysql> SOURCE Desktop/sql1.txt
SQL コマンドをコマンドプロントから実行する
MySQL モニタを起動しなくても、コマンドプロントから直接 SQL 文を実行することができます。以下が書式です。
mysql データベース名 -uユーザー名 -p -e "MySQL モニタのコマンド"
「-e」のオプションを付けて、その後にコマンドを「""」で囲んで指定します。コマンドは「''」(シングルクォテーション)ではなく、「""」ダブルクォテーションで囲みます。
パスワードは上記実行後、入力することができます。
C:\Users\xxxx>mysql db1 -uroot -p -e "SOURCE Desktop/sql1.txt" Enter password: +------+-------+-------+ | id | sales | month | +------+-------+-------+ | C001 | 100 | 4 | | C003 | 198 | 6 | +------+-------+-------+ ・・・省略・・・
tee コマンドを使って SQL の結果をファイルに保存
MySQL モニタで tee コマンドを使うと、結果をファイルに書き出すことができます。
tee 出力するファイル名;
例えば、デスクトップに「log1.txt」というファイルを作成して書き出すには、MySQL モニタで以下のようにします。
パスを指定しなければ、「log1.txt」が保存されるのは実行した場所です。デフォルトでは「C:\Users\ユーザー」フォルダになります。
mysql> tee Desktop/log1.txt Logging to file 'Desktop/log1.txt' /* 空のテキストファイルが作成されます */ /* 以降の出力は、画面に表示されるだけでなく「log1.txt」にも書き込まれます。 */ mysql> USE db1; Database changed mysql> SELECT * FROM tb; +------+-------+-------+ | id | sales | month | +------+-------+-------+ | C001 | 100 | 4 | | C003 | 77 | 5 | | C007 | 312 | 4 | | C002 | 238 | 4 | | C004 | 98 | 5 | | C006 | 156 | 4 | | C001 | 210 | 5 | | C007 | 180 | 5 | | C004 | 222 | 6 | | C003 | 198 | 6 | +------+-------+-------+ 10 rows in set (0.00 sec) mysql> notee /* 出力を中止 */ Outfile disabled.
ファイルへの出力を中止するときは、notee コマンドを使います。
バックアップとリストア
データベースのすべての内容を書き出すことを、「ダンプ(dump)する」といいます。ダンプしたファイルを使えば、別のサーバーに同じ内容のデータベースを構築したり、バックアップを取ることができます。
ダンプにより書き出された情報は、SQL 文からなるテキストファイルで、データベースのすべての情報を読み取ることが可能であり、「ダンプ出力はデータベースそのもの」と言うことができます。そのため、その扱いには十分慎重に行なう必要があります。
MySQL のデータベースをダンプするには、コマンドプロントから mysqldump コマンドを実行します。以下が書式です。
mysqldump -u ユーザー名 -pパスワード データベース名 > 出力ファイル名;
mysqldump コマンドを実行した結果をリダイレクト(>)でファイルに書き込みます。
以下は、データベース db1 をダンプする例です。ダンプファイル「db1_out.txt」は、「C:\Users\xxxx」に作成されます。
C:\Users\xxxx>mysqldump -u root -p db1 > db1_out.txt Enter password: xxxxxxxxxxxx
以下は、ダンプされたファイル db1_out.txt です。行の先頭が「---」になっていたり、「/:」と「*/」で囲まれていたりする部分はコメントです。
-- MySQL dump 10.13 Distrib 5.6.16, for Win32 (x86)
-- Host: localhost Database: db1
-- ------------------------------------------------------
-- Server version 5.6.16
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
--
-- Table structure for table `tb`
--
DROP TABLE IF EXISTS `tb`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `tb` (
`id` varchar(10) DEFAULT NULL,
`sales` int(11) DEFAULT NULL,
`month` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `tb`
--
LOCK TABLES `tb` WRITE;
/*!40000 ALTER TABLE `tb` DISABLE KEYS */;
INSERT INTO `tb` VALUES ('C001',100,4),('C003',77,5),('C007',312,4),('C002',238,4),('C004',98,5),('C006',156,4),('C001',210,5),('C007',180,5),('C004',222,6),('C003',198,6);
/*!40000 ALTER TABLE `tb` ENABLE KEYS */;
UNLOCK TABLES;
・・・省略・・・
ダンプしたファイルをリストア
ダンプしたファイルをリストアするには、コマンドラインから、リダイレクトでファイルをデータベースにリストアします。
データベースをダンプした場合、これをリストアするには、流し込むデータベースが存在している必要があります。
このため、別の場所に(別名で)データベースを作成するなど、データベースが存在しない場合はあらかじめ作成しておく必要があります。
この例では、新しいデータベース db2 を作成し、そこに db1_out.txt を使ってリストアします。
以下のようにコマンドラインから新しいデータベース db2 を作成する場合は、最後にセミコロンをつけないように気をつけます。セミコロンをつけてしまうと、データベース名が「db2;」になってしまいます。
C:\Users\xxxx>mysqladmin -u root -p CREATE db2 Enter password:xxxxx C:\Users\xxxx>mysql -u root -p db2 < db1_out.txt Enter password:xxxxx
文字コードの問題
エラーが発生してうまく「ダンプ→リストア」ができない場合は、文字コードを指定してダンプ、リストアを試してみます。文字コードを指定するには次のオプションを使います。
--default-character-set=文字コード
以下は、シフトJIS を表す「sjis」を指定する例です。
mysqldump -u root -pxxxxx db1>db1_out.txt --default-character-set=sjis mysqladmin -u root -pxxxxx CREATE db2 mysql -uroot -pxxxxx db2<db1_out.txt --default-character-set=sjis
テーブルのロック
MySQL では、クライアントセッションは、ほかのセッションと連携してテーブルにアクセスするために、またはそのセッションにテーブルへの排他的アクセスが必要な期間中はほかのセッションによってそのテーブルが変更されないようにするために、明示的にテーブルロックを取得できます。
現在のセッション内でテーブルロックを取得するには、LOCK TABLES ステートメントを使用します。次のロックタイプを使用できます。
- READ [LOCAL] ロック:
- このロックを保持しているセッションは、テーブルを読み取ることができます (ただし、書き込みはできません)。
- 複数のセッションが同時にテーブルに対する READ ロックを取得できます。
- LOCAL 修飾子を使用すると、ロックが保持されている間、ほかのセッションによる競合しない INSERT ステートメント (並列挿入) を実行できます。
- WRITE ロック:
- このロックを保持しているセッションは、テーブルの読み取りおよび書き込みが可能です。
- このロックを保持しているセッションだけがテーブルにアクセスできます。ロックが解放されるまで、ほかのどのセッションもアクセスできません。
- WRITE ロックが保持されている間、テーブルに対するほかのセッションからのロック要求はブロックされます。
以下が書式です。
LOCK TABLES テーブル名 ロックの種類
テーブル tb に WRITE のロックを設定するには、以下のようにします。
LOCK TABLES tb WRITE;
ロックを解除するには、UNLOCK TABLES を使います。
UNLOCK TABLES;