Mac ターミナルの基本的な使い方・操作方法(3)シェルスクリプト
シェルの環境設定やパーミッション、シェルスクリプト(変数、引数、配列、構文、条件判定、四則演算など)などの基本的なことについての覚書です。
作成日:2019年10月08日
関連ページ
- Mac ターミナルの基本的な使い方(1)ターミナルの設定や基本的なコマンド等
- Mac ターミナルの基本的な使い方(2)エディタ: nano と vim
- Mac ターミナルの基本的な使い方・操作方法(4):プロセス、シグナル、ファイルの圧縮と展開、ソフトウェアのインストール、ネットワークの基本コマンド
- Mac ターミナル zsh の設定・カスタマイズ(シェルオプション)
- Mac ターミナル defaults コマンドの使い方
シェル
ユーザがターミナルを開くとシェルというプログラムが起動してプロンプトを表示し、コマンド入力待ちの状態になります。
プロンプトの後にユーザがコマンドを入力するとシェルによって解釈されコンピュータ(OS の中心部分:カーネル)に伝えられます。
そしてコンピュータがコマンドを実行し、応答をシェルが受け取り再びシェルがプロンプトを表示します。
言い換えると、ユーザは直接コンピュータとやり取りするのではなく、シェルを通してコンピュータにコマンドを送り、シェルを通して結果を受け取るというようにシェルを介してコンピュータを操作します。
シェルには大きく分けて、上記のコマンドインタープリタ(OS のインターフェース)としての役割とプログラム言語としての役割があります。
また、コマンドライン(ターミナル)を起動したときに立ち上がるシェル(ログインして最初に動き出すシェル)のことをログインシェル、コマンドラインで bash や zsh と入力した時に起動するシェルのことをインタラクティブシェルと呼びます。
※ 以下は基本的に bash の使用を前提としていますが、zsh でもほとんどは機能するかと思います。
macOS の標準シェル(bash → zsh)
シェルにはいろいろな種類のシェルがあり、macOS にも複数のシェルが用意されていますが、デフォルトで使われるのは bash(Bourne Again SHell) zsh です。
※ macOS Catalina からデフォルトのログインシェルおよびインタラクティブシェルが bash から zsh に変更されました。
システムにログインした際に使用されるシェルを「ログインシェル」と呼びます。
現在使用されているシェルは以下のように環境変数 $SHELL で確認することができます。
echo $SHELL return /bin/zsh //Mojave 以前のデフォルトの場合は /bin/bash
man bash
man コマンドの引数に bash を指定して実行すると bash の非常に詳しい情報(シェルの文法のようなもの:変数、特殊文字、制御構造、構文、各種展開、等々)が表示されます。
man bash return
BASH(1) BASH(1)
NAME
bash - GNU Bourne-Again SHell
SYNOPSIS
bash [options] [file]
COPYRIGHT
Bash is Copyright (C) 1989-2005 by the Free Software Foundation, Inc.
DESCRIPTION
Bash is an sh-compatible command language interpreter that executes
commands read from the standard input or from a file. Bash also incor-
porates useful features from the Korn and C shells (ksh and csh).
Bash is intended to be a conformant implementation of the Shell and
Utilities portion of the IEEE POSIX specification (IEEE Standard
1003.1). Bash can be configured to be POSIX-conformant by default.
・・・
設定可能なシェル
設定が可能なシェルは /etc/shells(ログインシェルの一覧)で確認できます。/etc/shells はログインシェルとして有効なファイルのフルパスが記述されたテキストファイルです。
$ cat /etc/shells return # List of acceptable shells for chpass(1). # Ftpd will not allow users to connect who are not using # one of these shells. /bin/bash /bin/csh /bin/dash /bin/ksh /bin/sh /bin/tcsh /bin/zsh
以下は /bin ディレクトリ内の sh を含む名前を表示する例です。
$ ls /bin | grep 'sh' return bash csh dash ksh sh tcsh zsh
以下はそれぞれのシェルの概要です。
| シェル | 説明 |
|---|---|
| sh | 最も古くからあるシェル。開発者の名前から Bourne シェルや「B シェル」と呼ばれる。 |
| bash | sh の上位互換シェル。「生まれ変わった Bourne シェル」という意味で bash(Bourne Again SHell)と名付けられる。macOS Mojave までの標準シェル。 |
| ksh | Korn Shell。David Korn が開発。sh の上位互換シェル。 |
| csh | C シェル/C Shell。C 言語の文法を元にしているのが名前の由来。sh とは互換性なし。 |
| tcsh | csh の機能拡張版。TC シェル(TENEX C shell) |
| zsh | 最も高機能なシェルの1つ。sh、bash、csh、ksh、tcsh の上位互換(相当の機能を持つ)。macOS Catalina 以降の標準シェル |
シェルの変更
ログイン・シェルを変更するには以下のような方法があります。
| 方法 | 説明 |
|---|---|
| chsh コマンド | ターミナルでユーザーのログイン・シェルを変更するコマンド chsh -s にシェルのパスを指定して実行(デフォルトシェルを変更する方法1) |
| ターミナルの環境設定 | ターミナルの「環境設定」→「一般」の「開くシェル」でシェルのパスを指定して設定(デフォルトを変更せずに別のシェルを使う方法) |
| システム環境設定 | 「システム環境設定」→「ユーザとグループ」でロックを解除し、ユーザを右クリックして詳細オプションの「ログインシェル」でシェルのパスを選択して設定(デフォルトシェルを変更する方法2) |
参考:Apple「zsh を Mac のデフォルトシェルとして使う」
以下は macOS Catalina 以降でのデフォルトのログインシェルを zsh から bash に変更する例です。
chsh コマンドで変更(デフォルトシェルを変更する方法1)
ターミナルで chsh -s /bin/bash を実行すると、ユーザのパスワードを求められるので入力して return キーを押します。
変更が反映されるにはターミナルを再起動する必要があります。
% echo $SHELL return //現在使用されているシェルを確認 /bin/zsh % chsh -s /bin/bash return //ログインシェルを bash に変更 Changing shell for xxxx. Password for xxxx: //ユーザのパスワードを求められるので入力して return % echo $SHELL return // 変更を反映するにはターミナルを再起動 /bin/zsh
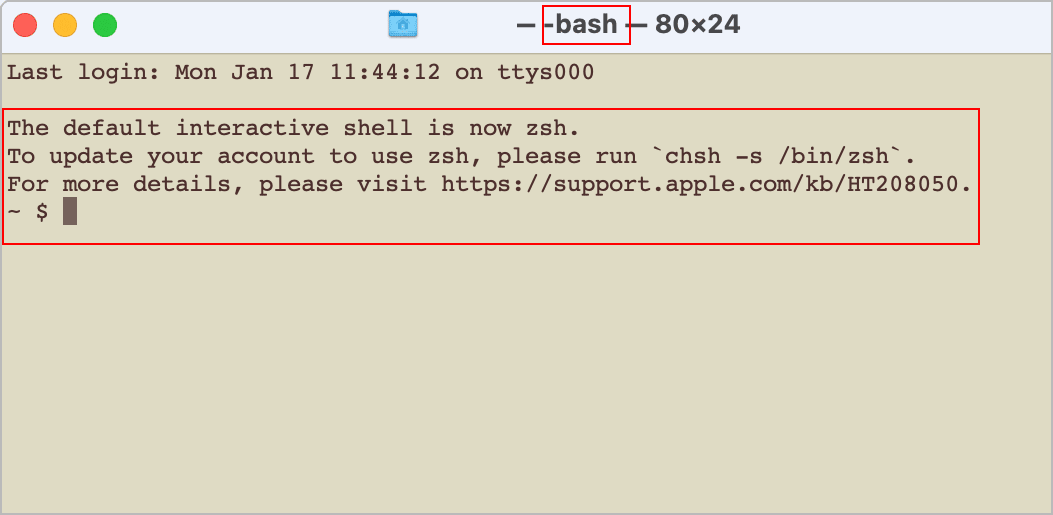
ターミナルを再起動すると変更したシェル(bash)に切り替わります。
//以下のようなメッセージが表示される The default interactive shell is now zsh. To update your account to use zsh, please run `chsh -s /bin/zsh`. For more details, please visit https://support.apple.com/kb/HT208050. $ echo $SHELL return //現在使用されているシェルを確認 /bin/bash
zsh に戻すには chsh -s /bin/zsh を実行します。
「The default interactive shell ...」のメッセージを表示しないようにすることもできます(詳細)。
ターミナルの環境設定で変更(デフォルトを変更せずに別のシェルを使う方法)
デフォルトを変更せずに別のシェルを使うには、ターミナルの「環境設定」で「一般」を選択し、「開くシェル」で「コマンド」を選択して /bin/bash を入力します。
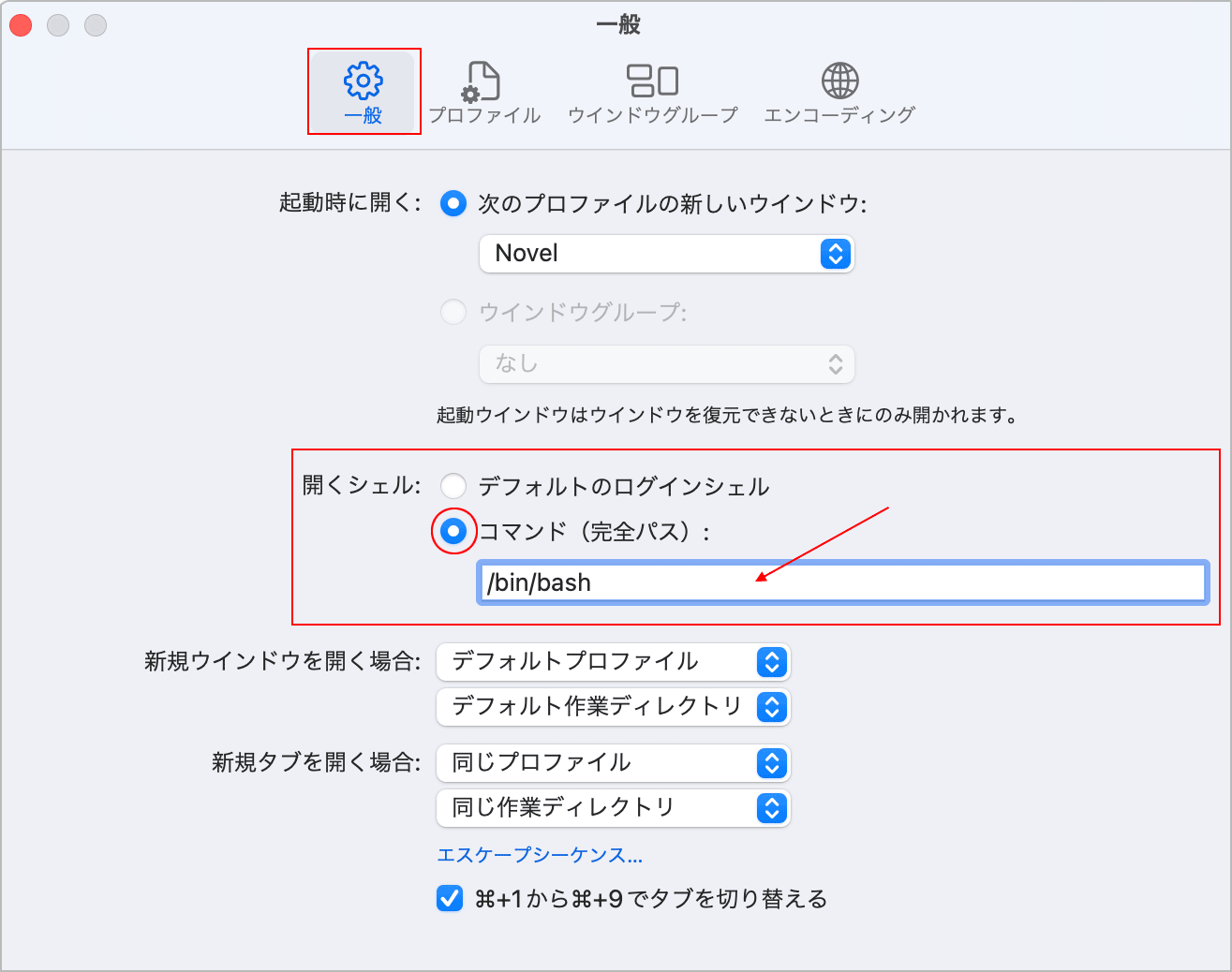
ターミナルを再起動すると変更したシェル(bash)に切り替わります。
この場合、デフォルトシェルを変更していないので、環境変数(組み込みシェル変数)の $SHELL を確認すると /bin/bash にはなっておらず、デフォルトのシェル(/bin/zsh)が表示されますが bash を使用できます。
$ echo $SHELL return /bin/zsh
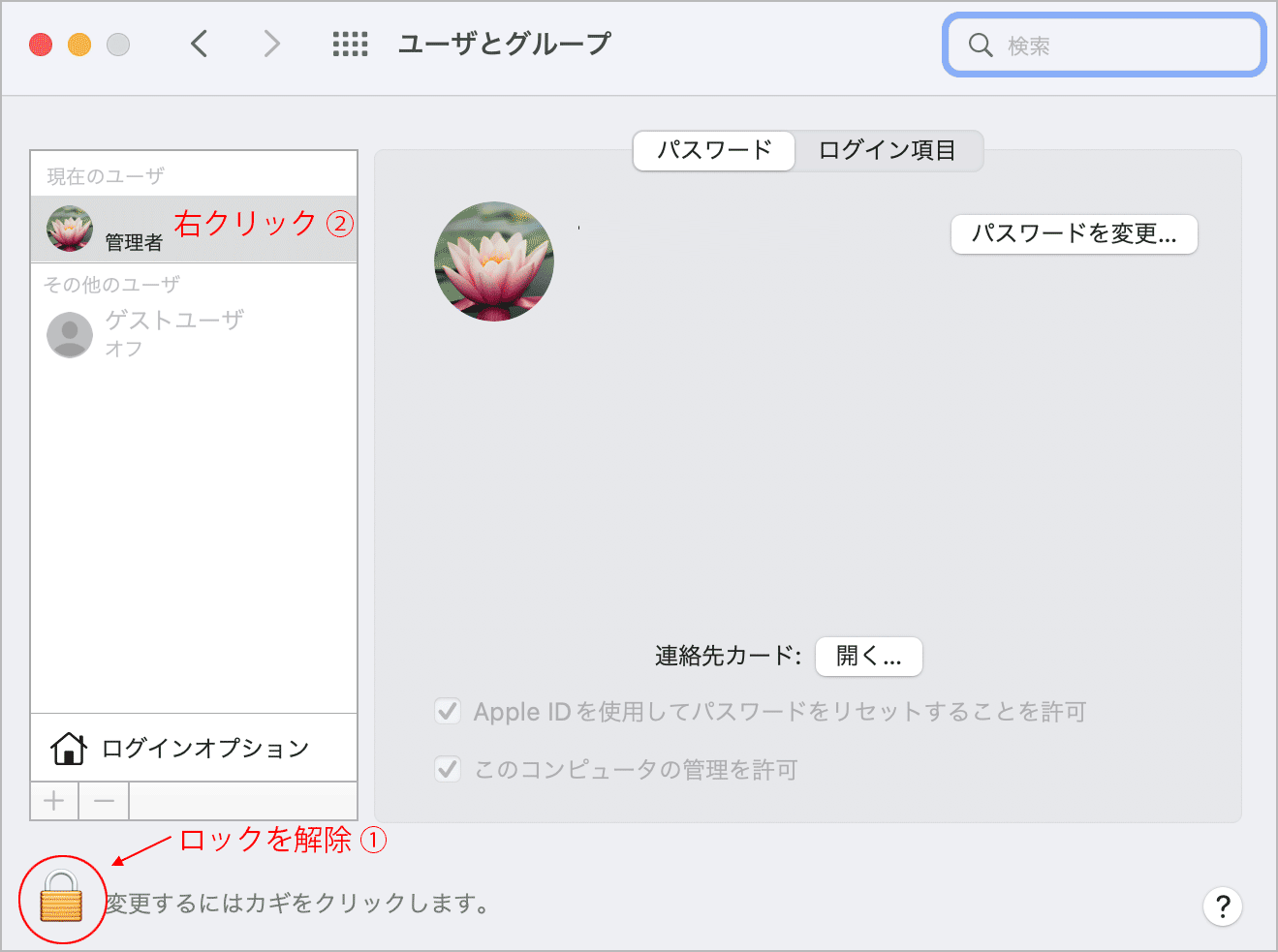
システム環境設定で変更(デフォルトシェルを変更する方法2)
「システム環境設定」→「ユーザとグループ」で鍵のアイコンをクリックするとパスワードを求められるので入力してロックを解除します。
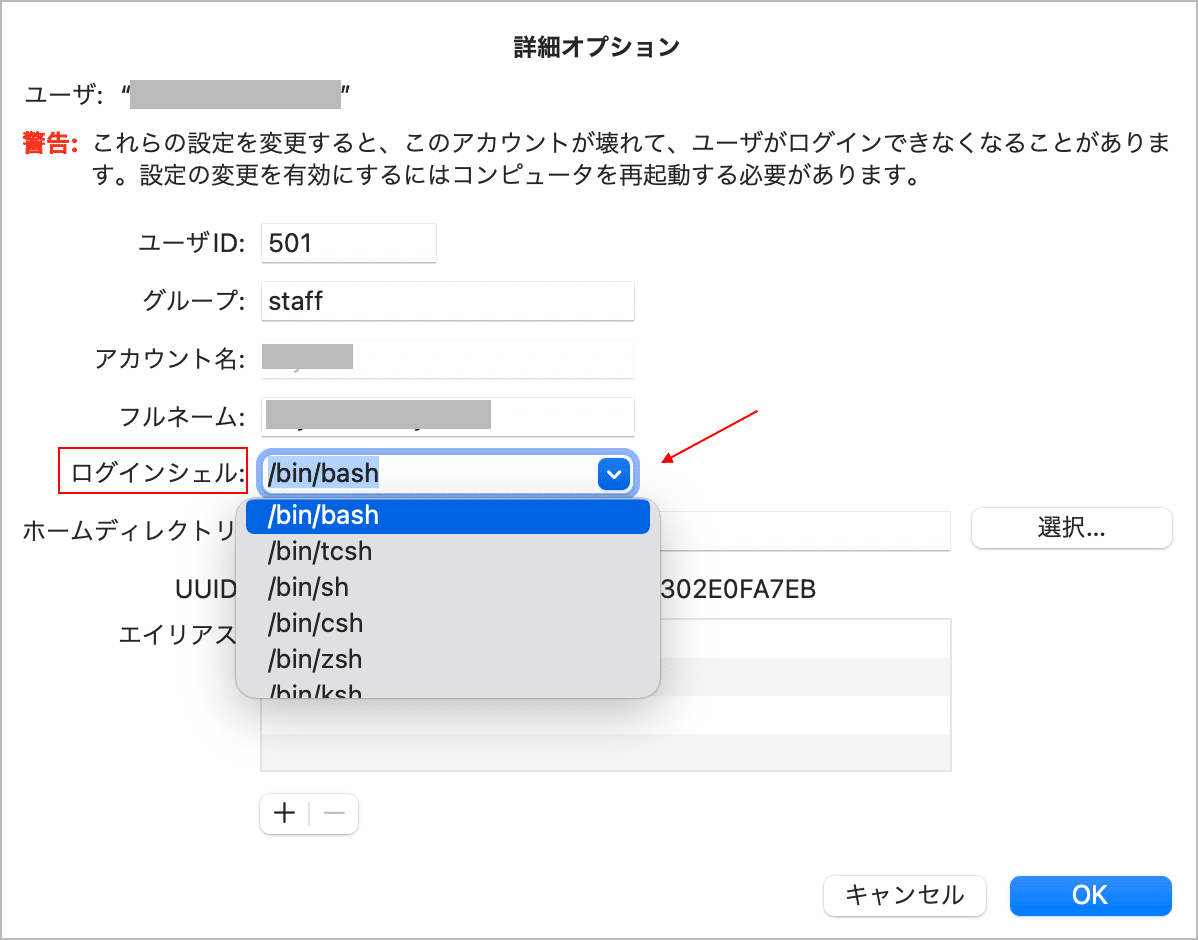
ユーザを右クリックして「詳細オプション...」を選択して表示される画面の「ログインシェル」でシェルのパス(/bin/bash)を選択してOKをクリックして変更内容を保存します。
ターミナルを再起動すると変更したシェル(bash)に切り替わります。
$ echo $SHELL return //現在使用されているシェルを確認 /bin/bash
The default interactive shell is now zsh... を表示しない
macOS Catalina 以降でデフォルトのログインシェルを zsh から bash に変更すると、毎回ターミナルを起動する際に以下のようなメッセージが表示されてしまいます。
このメッセージを非表示にするには、ログイン時に読み込まれる設定ファイル ~/.bash_profile に以下を追加します。
export BASH_SILENCE_DEPRECATION_WARNING=1
別のシェルを使用
ターミナルにログインした後に別のシェルを使用するにはシェルをコマンドとして実行すれば、ログインシェル(bash)の上でそのシェルが起動します。
exit コマンドを実行すれば元のシェルに戻ります。
$ zsh return //zsh に変更 % //プロンプトが % に変わる % echo $PS1 return //環境変数 $PS1 を表示 %n@%m %1~ %# % exit return //zsh を終了 Saving session... ...copying shared history... ...saving history...truncating history files... ...completed. $ // bash に戻り、プロンプトが $ に戻る
内部コマンドと外部コマンド
コマンドにはシェルの中に組み込まれている内部コマンド(組み込みコマンド、ビルトインコマンド、シェルコマンドとも呼びます)と、実行可能形式のファイル(executable file)として保存されている外部コマンドがあります。
コマンドラインでコマンドを実行する際、シェルは以下の順番で該当する名前のコマンドを探し、最初に見つけたものを実行します。
また、内部コマンド(組み込みコマンド)はシェル自体に実装されいるコマンドなので、シェルの振る舞いを変更したり、制御構文としてのコマンドなどが用意されています。
例えば、printenv は外部コマンドなのでシェル変数にはアクセスできませんが、echo コマンドはシェルの内部コマンドなのでシェル変数及び環境変数にアクセスできます。
bash の内部コマンドは引数なしで help と入力することで表示させることができます。
help return
GNU bash, version 3.2.57(1)-release (x86_64-apple-darwin18)
These shell commands are defined internally. Type `help' to see this list.
Type `help name' to find out more about the function `name'.
Use `info bash' to find out more about the shell in general.
Use `man -k' or `info' to find out more about commands not in this list.
A star (*) next to a name means that the command is disabled.
JOB_SPEC [&] (( expression ))
. filename [arguments] :
[ arg... ] [[ expression ]]
#内部コマンドのリスト(適当に改行しています)
alias [-p] [name[=value] ... ]
bg [job_spec ...]
bind [-lpvsPVS] [-m keymap] [-f fi
break [n]
builtin [shell-builtin [arg ...]]
caller [EXPR]
case WORD in [PATTERN [| PATTERN].
cd [-L|-P] [dir]
command [-pVv] command [arg ...]
compgen [-abcdefgjksuv] [-o option
complete [-abcdefgjksuv] [-pr] [-o continue [n]
declare [-afFirtx] [-p] [name[=val
dirs [-clpv] [+N] [-N]
disown [-h] [-ar] [jobspec ...]
echo [-neE] [arg ...]
enable [-pnds] [-a] [-f filename]
eval [arg ...]
exec [-cl] [-a name]
file [redirec exit [n]
export [-nf] [name[=value] ...] or false
fc [-e ename] [-nlr] [first] [last
fg [job_spec]
for NAME [in WORDS ... ;] do COMMA for (( exp1; exp2; exp3 )); do COM
function NAME { COMMANDS ; } or NA
getopts optstring name [arg]
hash [-lr] [-p pathname] [-dt] [na
help [-s] [pattern ...]
history [-c] [-d offset] [n] or hi if COMMANDS; then COMMANDS; [ elif
jobs [-lnprs] [jobspec ...] or job kill [-s sigspec | -n signum | -si
let arg [arg ...]
local name[=value] ...
logout
popd [+N | -N] [-n]
printf [-v var] format [arguments]
pushd [dir | +N | -N] [-n]
pwd [-LP]
read [-ers] [-u fd] [-t timeout] [
readonly [-af] [name[=value] ...]
return [n]
select NAME [in WORDS ... ;] do CO
set [--abefhkmnptuvxBCHP] [-o opti
shift [n]
shopt [-pqsu] [-o long-option] opt
source filename [arguments]
suspend [-f]
test [expr]
time [-p] PIPELINE
times
trap [-lp] [arg signal_spec ...]
true
type [-afptP] name [name ...]
typeset [-afFirtx] [-p] name[=valu
ulimit [-SHacdfilmnpqstuvx] [limit
umask [-p] [-S] [mode]
unalias [-a] name [name ...]
unset [-f] [-v] [name ...]
until COMMANDS; do COMMANDS; done
variables - Some variable names an
wait [n]
while COMMANDS; do COMMANDS; done { COMMANDS ; }
内部コマンドの場合、man コマンドで使い方を調べようとしても見つからなかったり、内部コマンド全体の説明のようなものが表示される場合があります。
man let return # let コマンドのマニュアルは見つからない
No manual entry for let
man read return # read コマンドの場合、以下のように内部コマンドの説明が表示される
BUILTIN(1) BSD General Commands Manual BUILTIN(1)
NAME
builtin, !, %, ., :, @, {, }, alias, alloc, bg, bind, bindkey, break,
breaksw, builtins, case, cd, chdir, command, complete, continue, default,
dirs, do, done, echo, echotc, elif, else, end, endif, endsw, esac, eval,
exec, exit, export, false, fc, fg, filetest, fi, for, foreach, getopts,
glob, goto, hash, hashstat, history, hup, if, jobid, jobs, kill, limit,
local, log, login, logout, ls-F, nice, nohup, notify, onintr, popd,
printenv, pushd, pwd, read, readonly, rehash, repeat, return, sched, set,
setenv, settc, setty, setvar, shift, source, stop, suspend, switch,
telltc, test, then, time, times, trap, true, type, ulimit, umask,
unalias, uncomplete, unhash, unlimit, unset, unsetenv, until, wait,
where, which, while -- shell built-in commands
SYNOPSIS
builtin [-options] [args ...]
・・・
help の引数に内部コマンド名を指定すると、そのコマンドの使い方が表示されます。
help let return #let コマンドの使い方を表示
let: let arg [arg ...]
Each ARG is an arithmetic expression to be evaluated. Evaluation
is done in fixed-width integers with no check for overflow, though
division by 0 is trapped and flagged as an error. The following
list of operators is grouped into levels of equal-precedence operators.
The levels are listed in order of decreasing precedence.
id++, id-- variable post-increment, post-decrement
++id, --id variable pre-increment, pre-decrement
-, + unary minus, plus
!, ~ logical and bitwise negation
・・・
help read return #read コマンドの使い方を表示
read: read [-ers] [-u fd] [-t timeout] [-p prompt] [-a array] [-n nchars] [-d delim] [name ...]
One line is read from the standard input, or from file descriptor FD if the
-u option is supplied, and the first word is assigned to the first NAME,
the second word to the second NAME, and so on, with leftover words assigned
to the last NAME. Only the characters found in $IFS are recognized as word
delimiters. If no NAMEs are supplied, the line read is stored in the REPLY
variable. If the -r option is given, this signifies 'raw' input, and
backslash escaping is disabled. The -d option causes read to continue
until the first character of DELIM is read, rather than newline. If the -p
option is supplied, the string PROMPT is output without a trailing newline
before attempting to read. If -a is supplied, the words read are assigned
・・・
type コマンド
コマンドが内部コマンドと外部コマンドのどちらのタイプかは type コマンドで調べることができます。
以下は type コマンドの書式です。
type [オプション] コマンド名
type コマンドを実行すると、シェルがどのコマンドを起動しているかを確認することができます。
内部コマンドの場合は「xxxx is a shell builtin」と表示され、外部コマンドの場合はファイルの保存先のパスが表示されます。
type echo return echo is a shell builtin #内部コマンド type find return find is /usr/bin/find #外部コマンド type ls return ls is hashed (/bin/ls) #外部コマンド(ハッシュテーブルに記憶されている)
「xxxx is hashed」と表示されるのは、シェル(bash)がこのコマンドの位置を既にハッシュテーブル(コマンドの位置を記憶しておくテーブル)に記憶していて、環境変数 PATH のディレクトリを検索せずにそのコマンドを実行するという意味です。
実行可能なコマンドを全て表示する -a
コマンドによっては内部コマンドと外部コマンドの両方が用意されていたり、エイリアスが設定されている場合があります。
-a オプションを指定することで全てを表示することができます。
以下は ls コマンドにエイリアスが設定されている場合の例です。
alias ls='ls -l' return #エイリアスを設定 type ls return #オプション無しで type コマンドを実行 ls is aliased to `ls -l' #エイリアスのみが表示される type -a ls return # -a オプションを指定して実行 ls is aliased to `ls -l' #外部コマンド ls is /bin/ls
以下は pwd コマンドの例ですが、このコマンドは両方の形式が用意されています。
type -a pwd return #全てのタイプを表示 pwd is a shell builtin #内部コマンド pwd is /bin/pwd #外部コマンド
※ 内部コマンドが優先されるので、普通に pwd コマンドを実行すると内部コマンドが実行されます。
実行可能ファイル(executable file)の外部コマンドを実行するには、「/bin/pwd」と絶対パスを指定します。
/bin/pwd return #外部コマンドの pwd を実行 /Users/foo
which コマンド
複数の同じ名前の外部コマンドがある場合、シェルは環境変数 PATH に設定されているディレクトリを調べて最初に見つかったものを実行します。
which コマンドを使うと、どの外部コマンドが実行されるかを調べることができます。
言い換えると which コマンドは、指定されたコマンドをユーザの環境変数 PATH に設定されているディレクトリを順番に調べて、最初に見つかった実行ファイルを表示します。
以下が書式です。
which [オプション] コマンド名
「which コマンド名」を実行すると指定したコマンドの実行ファイルをフルパスで表示します。
which ls return /bin/ls
-a オプションを指定すると、最初に見つかったコマンドだけでなく、もしあれば全ての実行ファイルを表示します。
以下は pwd コマンドを which と type コマンドを使って調べる例です。
type コマンドとは異なり、which コマンドではシェルの内部コマンド(組み込みコマンド)やエイリアスは検索できません。
which pwd return #which コマンド /bin/pwd type pwd return #type コマンド pwd is a shell builtin which -a pwd return #which コマンド /bin/pwd type -a pwd return #type コマンド pwd is a shell builtin pwd is /bin/pwd
シェルの環境設定
シェルはユーザーの入力をカーネルに伝えまたその逆を行うコマンドラインインタープリタですが、同時にプログラミング言語なので変数が使えます。
シェルの変数には現在実行中のシェルだけで有効なシェル変数と、新たなシェルを起動したりシェルから実行したコマンドにも引き継がれる環境変数(動作環境に関わるシェル変数)があります。
シェル変数及び環境変数には動作環境等を設定するために予め組み込まれているものとユーザーが独自に設定できるものがあります。
シェル変数
値を設定
以下はシェル変数に値を設定する書式です。
変数名=値
= の前後にスペース(空白)を入れることはできません。
スペースを入れるとコマンドと引数の区切りと解釈されてしまい、command not found というエラーになります。
以下は userName1 という変数に foo という値(文字列)を設定(代入)する例です。
userName1='foo' return userName2 = 'bar' return #= の前後にスペースを入れるとエラーになる -bash: userName2: command not found
また、文字列を引用符で囲むことは必須ではありませんが、値にスペースなどの特殊文字を含む場合は、値を引用符で囲む必要があります。
name=Billy Joe return -bash: Joe: command not found $ スペースがあるためエラーになる name='Billy Joe' return
以下の場合、変数 name1、name2、name3 の値は同じです。
name1=foo name2='foo' name3="foo" echo $name1 foo echo $name2 foo echo $name3 foo
コマンド置換を使ってコマンドの実行結果を変数に代入することもできます。
files=$(ls) return #ls コマンドの実行結果を変数 files に代入 echo $files return #files の値(ls コマンドの実行結果)を表示 01.txt process.txt sample.csv sample.txt sample2.txt ... now=`date` return #date コマンドの実行結果を変数 now に代入(バッククォートを使用) echo $now return #now の値を表示 2019年 9月 7日 土曜日 09時49分17秒 JST
値の取得(参照)
シェル変数の値を取り出す(参照する)には、変数名の先頭に $ を付けます。
以下は変数を設定して、その値を echo コマンドで表示する例です。
name="foo" return #変数 name に値 foo を代入 echo $name return #変数 name の値を表示 foo # $name で参照された値が表示される
変数はダブルクォートの中では展開されますが、シングルクォートの中ではそのままの文字列として表示されます。
echo "$name" return #ダブルクォート foo #値が展開されて表示される echo "name の値は $name です" return #ダブルクォート name の値は foo です #値が展開されて表示される echo '$name' return #シングルクォート $name #値が展開されず、文字列として表示される echo 'name の値は $name です' return #シングルクォート name の値は $name です #値が展開されず、文字列として表示される echo $name return #引用符なし foo echo name の値は $name です return #引用符なし name の値はfoo です
${ }
変数の区切りはスペースやカンマなどで判断されるため、変数の後にスペースなどがないとうまく変数が展開されません。
{ } で変数名を括って ${変数名} のようにすると確実に区別することができます。
usrName='foo' return #変数を設定
echo "$usrNameはユーザ名です" return #変数の後にスペースがない場合
??ユーザ名です
echo "${usrName}はユーザ名です" return #{ } で変数を括る
fooはユーザ名です
echo '${usrName}はユーザ名です' return #シングルクォートでは変数は展開されない
${usrName}はユーザ名です
※ 変数名にも tab キーの入力補完が機能します。
長いパスなどをシェル変数に入れておくと便利です。
webDir=/Applications/MAMP/htdocs/webdesignleaves/ return #変数にパスを代入 echo $webDir return #変数の値(パス)を出力 /Applications/MAMP/htdocs/webdesignleaves/ cd $webDir return #変数を使ってディレクトリを移動 pwd return #現在のディレクトリ /Applications/MAMP/htdocs/webdesignleaves
設定したシェル変数はエイリアス同様、ログアウトするとクリアされます。
変数を削除
変数の定義(変数自体)を削除するには unset コマンドを使います。
変数名の先頭に $ は付けません。
unset 変数名
echo $userName1 return #変数 userName1 の値を出力 foo unset userName1 return #変数 userName1 を削除(変数名の先頭に $ は付けない) echo $userName1 return #削除されたため何も表示されない
組み込みシェル変数
あらかじめ登録され利用できるシェル変数や環境変数を組み込みシェル変数と呼びます。
組み込みシェル変数はシェルの動作の設定や現在の設定の確認などに使用されます。
現在どのようなシェル変数が設定されているかを確認するには、set コマンドを引数無しで実行します。但し、長いので less で表示します。
set | less return #現在設定されているシェル変数(組み込みと独自に設定した変数)を表示 Apple_PubSub_Socket_Render=/private/tmp/com.apple.launchd.cmcdZ2CoV0/Render BASH=/bin/bash BASH_ARGC=() BASH_ARGV=() BASH_LINENO=() BASH_REMATCH=([0]="i") BASH_SOURCE=() BASH_VERSINFO=([0]="3" [1]="2" [2]="57" [3]="1" [4]="release" [5]="x86_64-apple-darwin18") BASH_VERSION='3.2.57(1)-release' COLUMNS=80 DIRSTACK=() EUID=501 GROUPS=() HISTFILE=/Users/foo/.bash_sessions/2A251072-3977-4A22-A0A9-BEA54B2F105C.historynew HISTFILESIZE=500 HISTSIZE=500 HOME=/Users/foo HOSTNAME=imac01.local HOSTTYPE=x86_64 IFS=$' \t\n' LANG=ja_JP.UTF-8 ・・・中略・・・ PS1='\W $ ' PS2='> ' PS4='+ ' PWD=/Users/foo SHELL=/bin/bash ・・・中略・・・ XPC_SERVICE_NAME=0 _=echo userName=foo #独自に設定したシェル変数 webDir=/Applications/MAMP/htdocs/webdesignleaves/ #独自に設定したシェル変数 ・・・以下省略・・・ less を終了するには q を押します
環境変数
シェル変数の中で、シェルの動作環境に関わる変数を環境変数と呼びます。
通常のシェル変数は現在実行中のシェルだけで有効ですが、環境変数は新たなシェルを起動したり、シェルから実行したコマンドにも引き継がれます。
また、環境変数は通常のシェル変数と区別するために、変数名は一般的に全て大文字になっています。
代表的な環境変数には以下のようなものがあります。
| 環境変数 | 意味 |
|---|---|
| LANG | ロケール(言語、地位域名、文字コード)の設定。日本語環境のデフォルトは ja_JP.UTF-8 |
| PATH | コマンドが存在するパス(コマンド検索パス)が設定されています。パスを省略してコマンドを実行すると、この環境変数 PATH に定義されているパスを順番に検索し、コマンドが見つかった時点でそのコマンドを実行します。 |
| PS1 | シェルのプロンプト(として表示する文字列)の定義 |
| PWD | カレントディレクトリ(cd コマンドによりセットされる現在の作業ディレクトリ) |
| HOME | ユーザのホームディレクトリ |
| SHELL | 現在のデフォルトのシェル |
| TMPDIR | 一時ファイルに使用されるディレクトリ |
| IFS | 行をどこでフィールドに分割すべきなのかを判別するための内部フィールド区切り |
上記の変数は、組み込みシェル変数でもあります。
環境変数を表示 printenv
環境変数の内容を表示するには printenv コマンドを使います。
以下が書式です。
変数名を指定せずに実行すると環境変数を変数名と内容を対にして一覧表示することができます。
printenv [オプション] [変数名]
以下は変数名を指定せずに実行して、全ての環境変数を一覧表示する例です。
printenv return #環境変数を一覧表示 TERM_PROGRAM=Apple_Terminal SHELL=/bin/bash TERM=xterm-256color TMPDIR=/var/folders/cX2/XXXXXXXXXXXXXXXXXXXXX05h0000gn/T/ Apple_PubSub_Socket_Render=/private/tmp/com.apple.launchd.cmcdZ2CoV0/Render TERM_PROGRAM_VERSION=421.2 TERM_SESSION_ID=XXXXXXXX-96XX-4XDE-958D-XXXXXX90 USER=foo SSH_AUTH_SOCK=/private/tmp/com.apple.launchd.R2bxyQjRzd/Listeners PATH=/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin PWD=/Users/foo LANG=ja_JP.UTF-8 XPC_FLAGS=0x0 XPC_SERVICE_NAME=0 SHLVL=1 HOME=/Users/foo LOGNAME=foo _=/usr/bin/printenv
printenv 変数名 で指定した変数名の内容を表示できます。
printenv LANG return #LANG の内容を表示 ja_JP.UTF-8
環境変数の参照は echo $変数名 でも可能です(変数名の先頭に $ が必要です)。
echo $LANG return #echo で表示(変数名の先頭に $ が必要) ja_JP.UTF-8 echo $SHELL return #デフォルトのシェルを表示 /bin/zsh echo $PATH return #コマンド検索パスを表示 /usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin
printenv は外部コマンドなので、シェル変数にはアクセスできませんが、echo コマンドは内部コマンドなのでシェル変数と環境変数のどちらにもアクセスすることができます。
環境変数を設定 export
独自の環境変数を設定するには export コマンドを使用します。
以下が export コマンドの書式です。
export [オプション] [変数名[=値]]
以下は export コマンドのオプションです。
| オプション | 意味 |
|---|---|
| -f | シェル関数を参照 |
| -n | 環境変数をシェル変数に変える |
| -p | 全てのエクスポートされた変数を一覧表示する |
環境変数を設定するには(シェル)変数に値を設定し、export コマンドを実行します。
以下は独自の環境変数 ENV1 を設定する例です。
ENV1="sample env1" return #独自のシェル変数 ENV1 に値を設定 export ENV1 return #export コマンドで環境変数として設定(シェル変数 ENV1 をエクスポート) printenv ENV1 return #printenv コマンドで内容を確認 sample env1 echo $ENV1 return #echo コマンドで内容を確認 sample env1
以下のように、「export 変数名=値」の形式で変数の設定と環境変数の設定を同時に行うこともできます。
export ENV1="sample env1" return #独自の環境変数 ENV1 を設定
環境変数を削除
環境変数をクリア(変数自体を削除)するには、シェル変数と同様、unset コマンドを使います。
変数名の先頭に $ は付けません。
unset ENV1 return #ENV1 を削除
エクスポートされた変数を一覧表示
エクスポートされた変数を一覧表示するには、export コマンドに何も引数を指定せずに実行するか -p オプションを指定(変数名は指定しない)して実行します
export -p return #または export のみで実行 declare -x Apple_PubSub_Socket_Render="/private/tmp/com.apple.launchd.cmcdZ2CoV0/Render" declare -x ENV1="sample env1" #独自の環境変数 declare -x HOME="/Users/foo" declare -x LANG="ja_JP.UTF-8" declare -x LOGNAME="foo" declare -x OLDPWD declare -x PATH="/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin" declare -x PWD="/Users/foo" declare -x SHELL="/bin/bash" declare -x SHLVL="1" declare -x SSH_AUTH_SOCK="/private/tmp/com.apple.launchd.R2bxyQjRzd/Listeners" declare -x TERM="xterm-256color" declare -x TERM_PROGRAM="Apple_Terminal" declare -x TERM_PROGRAM_VERSION="421.2" declare -x TERM_SESSION_ID="X1EXXXXXX-96XA9-XXDE-95X8D-5XXXDS4F990" declare -x TMPDIR="/var/folders/cX2/XXXXXXXXXXXXXXXXXXX0000gn/T/" declare -x USER="foo" declare -x XPC_FLAGS="0x0" declare -x XPC_SERVICE_NAME="0"
環境変数をシェル変数に変更
export コマンドに -n オプションを指定すると、環境変数をシェル変数に変更することができます。
printenv ENV1 return #環境変数 ENV1 の内容を表示 sample env1 export -n ENV1 return #環境変数 ENV1 をシェル変数に変更 printenv ENV1 return #何も表示されない(シェル変数に変更されたため) echo $ENV1 return #echo コマンドでは内容を確認可能 sample env1
環境変数の保存
コマンドラインで設定した環境変数はターミナルを再起動するとクリアされます。
毎回使用する場合は、必要に応じて適切な環境設定ファイルに記述して保存することができます。
シェル変数と環境変数の違い
実行中のプログラム(コマンドやシェルなど)のことを「プロセス」と呼び、あるプロセスから起動したプロセスを「子プロセス」と呼びます。
通常のシェル変数は現在実行中のシェル(プロセス)だけで有効ですが、環境変数は新たに起動したシェル(子プロセス)や、シェルから実行したコマンド(子プロセス)にも引き継がれます。
シェルはコマンドを起動する際、環境変数のコピーをそのコマンドに渡しますが、シェル変数は渡しません。そのため、コマンド側では環境変数の内容は参照できますが、シェル変数の内容を参照できません。
| 変数 | 概要 |
|---|---|
| シェル変数 | 通常のシェル変数は、現在実行中のシェルだけで有効。 |
| 環境変数 | 新たに起動したシェルやシェルから実行したコマンド(子プロセス)にも引き継がれる。 |
以下は通常のシェル変数の場合の例です。別のシェルを起動すると、シェル変数は引き継がれないため値を表示(参照)することができません。
shellVar="shell var" return #シェル変数を設定 echo $shellVar return #echo で内容を表示 shell var bash return #別のシェル(bash)を起動 echo $ENV1 return #echo で内容を表示(参照)できない exit return #別のシェルを終了して元のシェルに戻る exit echo $shellVar return #echo で内容が表示される shell var
以下は環境変数の場合の例です。別のシェルを起動しても、シェル変数は引き継がるため値を表示(参照)することができます。
export ENVX="Env var" return #環境変数を設定 echo $ENVX return #echo で内容を表示 Env var bash return #別のシェル(bash)を起動 echo $ENVX return #echo で内容を表示(参照可能) Env var exit return #別のシェルを終了して元のシェルに戻る exit echo $ENVX return #echo で内容を表示 Env var
環境変数 PATH
PATH はコマンドが置かれている(コマンドの保存先の)ディレクトリを設定する環境変数です。
以下は printenv 及び echo コマンドで PATH の内容を表示する例です。
PATH には、コマンドが保存されているディレクトリ(コマンド検索パス)がコロン(:)区切りで記述されています。
printenv PATH return /usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin echo $PATH return /usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin #この例の場合以下のコマンド検索パスが登録されています。 /usr/local/bin /usr/bin /bin /usr/sbin /sbin
例えば、現在のユーザ名を表示する whoami コマンドは /usr/bin/whoami として保存されている実行可能形式のファイル(executable file)です。
実行可能形式のファイル(コマンド)は、以下のように絶対パスで指定すると実行できます。
/usr/bin/whoami return foo
しかし、通常は絶対パスで指定せずにコマンド名を指定して実行します。
それが可能なのはシェルが指定されたコマンドを、PATH に設定されているコマンド検索パスを順番に調べて見つかった実行ファイルを実行するためです。
言い換えると、コマンド検索パスに入っているコマンドはコマンド名だけで実行することができます。
パスを通す
環境変数 PATH には独自にディレクトリ(コマンド検索パス)を追加することができます。PATH にコマンド検索パスを追加することを「パスを通す」と言います。
例えば、自作したコマンドを ~/bin というディレクトリに配置している場合、~/bin をコマンド検索パスに追加することでコマンド名だけで実行できるようになります。
以下がパスを通す書式です。
export コマンドを使って、環境変数 PATH を再設定しています。
$PATH には現在のコマンド検索パスが入っているので、コロン区切りでパスを追加します。
export PATH=$PATH:パス #コマンド検索パス($PATH)の末尾に「:パス」を追加
export PATH=パス:$PATH #コマンド検索パス($PATH)の先頭に「パス:」追加
[注意]$PATH を使わずに「PATH=パス」のように追加するパスを環境変数 PATH に直接代入すると、デフォルトのコマンド検索パスがそのパスのみで上書きされてしまいます。
以下は、PATH の末尾に独自のコマンド検索パス ~/bin を追加する例です。
export PATH=$PATH:~/bin return printenv PATH return #PATH を表示 /usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/Users/foo/bin
以下は、PATH の先頭に独自のコマンド検索パス ~/sbin を追加する例です。
export PATH=~/sbin:$PATH return printenv PATH return #PATH を表示 /Users/foo/sbin:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin
※同じ名前のコマンドがある場合は、コマンド検索パスの先頭に記述されている方のコマンドが優先されて実行されます。
※セキュリティ上の理由から、通常はカレントディレクトリ「.」をコマンド検索パスには入れません。
また、パスの設定は、ログアウトするとクリア(初期化)されます。設定を保持するには、「~/.bash_profile」などの環境設定ファイルに設定を記述しておく必要があります。
~/.bash_profile への追加
以下はリダイレクト(>>)を使って .bash_profile にコマンド検索パス ~/sbin を(PATH の先頭に)追加する例です。変更を反映させるには source コマンドを実行します。
$ echo 'export PATH=~/sbin:$PATH' >> ~/.bash_profile return $ source ~/.bash_profile return //シェルの設定を反映
vi などで直接 .bash_profile を開いて追加することもできます。
コマンド実行ファイルの配置
環境変数 PATH は初期状態で /usr/local/bin などのデフォルトのパスがすでに設定されています(但し、/bin や /usr/bin はシステムのコマンドを保存する場所になります)。
そのため、コマンドの実行ファイルをデフォルトのパス(/usr/local/bin)に配置(保存)することで PATH を通さなくてもコマンド名だけで実行することができます。
また、そのようにすれば「~/.bash_profile」などの環境設定ファイルに追記する必要もありません。
ファイルのアクセス権限の関係で(macOS の場合)、/usr/local/bin などにファイルを配置するには sudo コマンドを使う必要があります。
環境設定ファイル
環境変数やエイリアスなどの設定は、ターミナルを終了したりログアウトすると初期化(クリア)されてしまいます。
常に使用する設定は、シェルが起動時に読み込む環境設定ファイルに記述しておけば、毎回設定する必要がありません。
bash には、シェルの起動時に読み込まれるいくつかの環境設定ファイルが存在します。
また、シェルがログインシェルとして起動された場合と、コマンドラインから他の bash を直接起動した場合に読み込まれる環境設定ファイルが異なります。
ユーザー固有の環境設定は、~/.bash_profile、もしくは ~/.bashrc というファイルへ必要に応じてユーザが記述することが可能です。
但し、Mac の場合、初期状態では ~/.bashrc や ~/.bash_profile は存在しないので、必要に応じて作成する必要があります。
これらのファイルの使い分けは、以下のようにするのが一般的なようです。
| ~/.bashrc | ログインシェル以外でシェルを起動したとき(インタラクティブシェル)に読み込まれるファイル。シェル起動時に実行する設定(プロンプトやエイリアスの設定など)を記述。 |
| ~/.bash_profile | ログイン時に読み込まれる(ログインシェルだけに実行される)ファイル。環境変数などログイン時に(一回だけ)実行する設定を記述。 |
~/.bash_profile は、ログイン時に起動されるログインシェルだけに実行される環境設定ファイルです。
ログインシェルでないシェルを起動した場合、~/.bashrc は実行されますが、~/.bash_profile は実行されません。
一般的には、ログイン時に一度だけ実行したい処理は ~/.bash_profile に記述し、シェルを起動する毎に実行したい処理は ~/.bashrc に記述します。
また、ログイン時には ~/.bashrc は読み込まれないので、 ~/.bashrc にエイリアスなどの設定をした場合は、~/.bash_profile の中で ~/.bashrc を読み込むように設定するのが一般的なようです。
関連項目:
zsh の設定(.zshrc)については以下を御覧ください。
~/.bashrc
ログインシェル以外でシェルを起動したとき(インタラクティブシェル)に読み込まれるファイルで、シェルを起動する毎に実行したい処理を記述します。
以下は、環境設定ファイル ~/.bashrc の記述例です。
プロンプトやエイリアスなどの設定を記述しています。
## .bashrc PS1="\W \$ " ##プロンプトの設定 alias cp='cp -i' ##エイリアスの設定 alias rm='rm -i' ##エイリアスの設定 alias mv='mv -i' ##エイリアスの設定 alias ll='ls -l' ##エイリアスの設定 alias la='ls -aF' ##エイリアスの設定 set -o noclobber ##リダイレクトによる上書き禁止の設定(または set -C)
- 2行目:プロンプトの環境変数 PS1 でプロンプトに表示する文字列を変更
- 3行目:cp コマンドでコピー先のファイルが存在している場合に確認をするためのエイリアス
- 4行目:rm コマンドでファイルを削除する際に確認するためのエイリアス
- 5行目:mv コマンドで移動先のファイルが存在している場合に確認をするためのエイリアス
- 6行目:ls -l コマンドを実行するエイリアス
- 7行目:ls -aF コマンドを実行するエイリアス
- 8行目:リダイレクトによる上書き禁止。
関連項目
~/.bash_profile
ログイン時に読み込まれる(ログインシェルだけに実行される)ファイルで、環境変数などログイン時に実行する設定を記述します。
また、併せて ~/.bashrc を読み込む設定を記述するのが一般的です。
以下は、環境設定ファイル ~/.bash_profile の記述例です。
~/.bashrc の読み込みと環境変数の設定を記述しています。
## .bash_profile if [ -f ~/.bashrc ]; then source ~/.bashrc fi export PATH=$PATH:~/bin ##環境変数 PATH の設定(ユーザの bin ディレクトリを追加) export BASH_SILENCE_DEPRECATION_WARNING=1 ##bash 非推奨のメッセージを非表示に
- 2〜4行目:~/.bashrc が存在した場合、source コマンドで ~/.bashrc を読み込む(ログインシェルに反映させる)設定です。これにより、ログインシェルでも ~/.bashrc が実行されます。
- 5行目:環境変数 PATH の設定で、~/bin(ユーザの bin ディレクトリ)をコマンド検索パス($PATH の末尾)に追加しています。
- 6行目:macOS Catalina 以降でデフォルトのログインシェルを zsh から bash に変更した場合に表示されるメッセージを表示しないようにする記述。
設定ファイルを反映 source
~/.bashrc や ~/.bash_profile を編集したら、変更を反映させるにはログインし直す(ターミナルを再起動する)方法がありますが、誤った設定が記述されていると再ログインできなくなる可能性があります。
source コマンドまたは .(ドット)コマンドを使うとシェルの設定(変更)を反映させることができます。
.bashrc と.bash_profile の変更を反映するために、ターミナルで以下を実行します。
source ~/.bashrc return source ~/.bash_profile return
以下が source コマンドと . コマンドの書式で、オプションはありません。
source ファイル名
. ファイル名
source または . コマンドを実行すると、ファイルに記述されているコマンドを現在のシェルで実行します。
言い換えると、source または . コマンドはファイルに記述されているコマンドを一つずつ入力して実行するのと同じことになります。
また、source または . コマンドは他のスクリプトファイルを現在のカレントシェルに読み込み、変数や関数を使用できるようにします。
以下はエイリアスの設定を ~/.bashrc に追加して、source コマンドで変更を即座に反映させる例です。
alias return #現在設定されているエイリアスを確認 alias cp='cp -i' alias la='ls -aF' alias ll='ls -l' alias rm='rm -i' vim ~/.bashrc return/ # vim で編集してエイリアス mv='mv -i' を追加(編集画面は省略) source ~/.bashrc return/ #source コマンドで上記編集による変更を現在のシェルに反映 alias return #エイリアスを確認 alias cp='cp -i' alias la='ls -aF' alias ll='ls -l' alias rm='rm -i' alias mv='mv -i' #追加が確認できる
.bashrc はシェルを起動したタイミングで読み込まれるファイルです。
また、ログインした際に読み込まれるファイル .bash_profile には、(一般的には).bashrc を読み込む設定が記述されているので、ログイン時に .bashrc が読み込まれます。
- ログイン
- ~/.bash_profile の実行
- ~/.bashrc の実行
その後、エイリアスや PATH の追加を~/.bashrc に記述すると、既に開いているシェルには追加した内容が反映されていないので、source ~/.bashrc で .bashrc を実行することで設定が反映されます(このため、ログインし直さずに設定を反映できます)。
source コマンドはその時に実行しているシェルでコマンドやスクリプトを実行することができます。但し、通常、シェルスクリプトの実行には使用しません。
また、source コマンドは実行するコマンドやスクリプトに実行権限は必要ありません。
シェルの再起動
前述の 設定ファイルを反映 source のようにシェルの設定ファイルを編集後、source コマンドを実行して変更を反映させることができますが、場合によってはシェルを再起動しないと変更が反映されない場合もあります。
例えば ~/.bashrc に記述してあるエイリアスをコメントアウトした後、source ~/.bashrc を実行しても、source ~/.bashrc はもう一度 ~/.bashrc を読み込んでいるだけなので、コメントアウトしたエイリアスは解除されません(この場合、エイリアスを解除するには unalias コマンドを使う必要があります)。
シェルを再起動すれば、設定を一度まっさらな状態にしてから ~/.bashrc を読むので、コメントアウトしたエイリアスは解除されます。
シェルを再起動するには一旦ログアウトして再ログインするか、以下を実行します
exec $SHELL -l
上記のコマンドは、現在のデフォルトのシェルをログインシェルとして新しく起動するものです。このコマンドを実行すると、新しいシェルが開かれ、ログインシェルとしての動作が実行されます。通常、ログインシェルはセッションの初期化や設定を行うために使用されます。
-
execは新しいプロセスを起動する(新しいシェルを起動するための)コマンドです。 -
$SHELLは環境変数 SHELL に格納されている現在使用されているシェルを表します。 -
-lはログインシェル(login shell)としてシェルを起動するオプションです。
エイリアスを作成
以下はシェルを再起動するコマンドのエイリアスの例です。restart で上記コマンドを実行できます。
alias restart='exec $SHELL -l'
プロンプトの変更(bash)
bash のプロンプトの書式は macOS(Mojave)の初期状態では「ホスト名:現在のディレクトリ名 ユーザ名$」になっています。必要に応じてこの書式を変更することができます。
macOS Catalina 以降の zsh のプロンプトの変更は「プロンプトの変更 zsh」をご覧ください。
プロンプトの書式は、シェル変数(環境変数) PS1(The primary prompt string)で定義されています。 以下のように $PS1 を echo して現在のユーザーの PS1 の内容を出力して確認することができます。
echo $PS1 \h:\W \u\$
\h や \W は以下のような意味があります。
| エスケープ文字 | 意味 |
|---|---|
| \H | ホスト名 |
| \h | ホスト名(最初の.まで) |
| \W | 現在のディレクトリ名 |
| \w | 現在のディレクトリ(フルパス) |
| \u | 現在のユーザー名 |
| \$ | $ は変数を表すので、ダブルクォートで $ を表示させたい場合は \$ のようにエスケープします。 |
| \T | 時刻 HH:MM:SS 形式(12時間) |
| \t | 時刻 HH:MM:SS 形式(24時間) |
一時的にプロンプトを変更するには、以下のように PS1 に書式を指定します(必要に応じて適宜スペースを入れます)。
PS1="\W \$ " #現在のディレクトリ名 $
上記の場合、ターミナルを再起動すると設定が戻ってしまうので、設定を保存するには ~/.bashrc などに設定を記述します。
但し、Mac の場合、初期状態ではユーザー毎に設定できる ~/.bashrc や~/.bash_profile は作成されていないようです(/etc/bashrc や /etc/profile はシステム全体の設定用なので使いません)。
| ~/.bashrc | ログインシェル以外でシェルを起動したときに読み込まれるファイル。シェル起動時に実行する設定(プロンプトやエイリアスの設定など)を記述。 |
| ~/.bash_profile | ログイン時に読み込まれる(ログインシェルだけに実行される)ファイル。環境変数などログイン時に実行する設定を記述。 |
「~」は現在ログインしているユーザーのホームディレクトリを表します。
ドット(.)が最初に付いたファイルは隠しファイルになるので、Shift + Command + . を押して表示させることができます。
ls コマンドの場合は -a オプションを付けます。
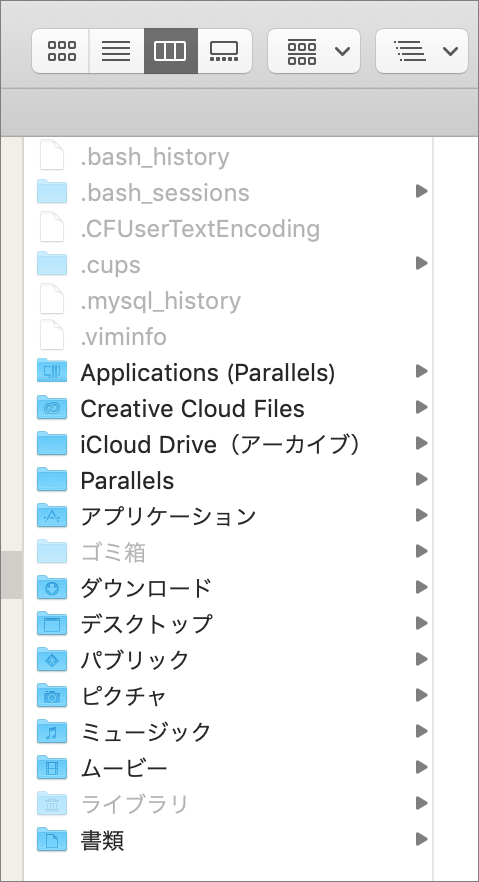
~/.bashrc と ~/.bash_profile の作成
GUI のエディタでもこれらのファイルは作成可能ですが、以下はターミナルと vim を使う場合の例です。
touch コマンドで空の ~/.bashrc と ~/.bash_profile を作成して ls コマンドで確認します。
touch ~/.bashrc return touch ~/.bash_profile return ls -a return . Applications (Parallels) .. Creative Cloud Files .CFUserTextEncoding Desktop .DS_Store Documents .Trash Downloads .bash_history Library .bash_profile Movies .bash_sessions Music .bashrc Parallels .cups Pictures .mysql_history Public .viminfo iCloud Drive(アーカイブ) Applications
.bash_profile の編集
ターミナルに以下を入力して .bash_profile を vim で編集し、ログイン時にも ~/.bashrc が読み込まれるようにします。
vim は vi または vim コマンドで起動することができます。引数には編集するファイルを指定します。
vi ~/.bash_profile return
i を押して挿入モードにして、以下を記述して esc を押して挿入モードを解除します。
続いて :wq と入力して内容を保存し vim を終了します。
if [ -f ~/.bashrc ]; then . ~/.bashrc fi
.bashrc の編集(プロンプトの書式を設定)
次にターミナルに以下を入力して .bashrc を vim で編集し、プロンプトの書式を設定します。
vi ~/.bashrc return
前述と同様、i で挿入モードにして、以下を記述して esc を押して挿入モードを解除します。
続いて :wq と入力して内容を保存し vim を終了します。
PS1="\W \$ "
上記の例の場合、プロンプトは「現在のディレクトリ名 $」のようになります。
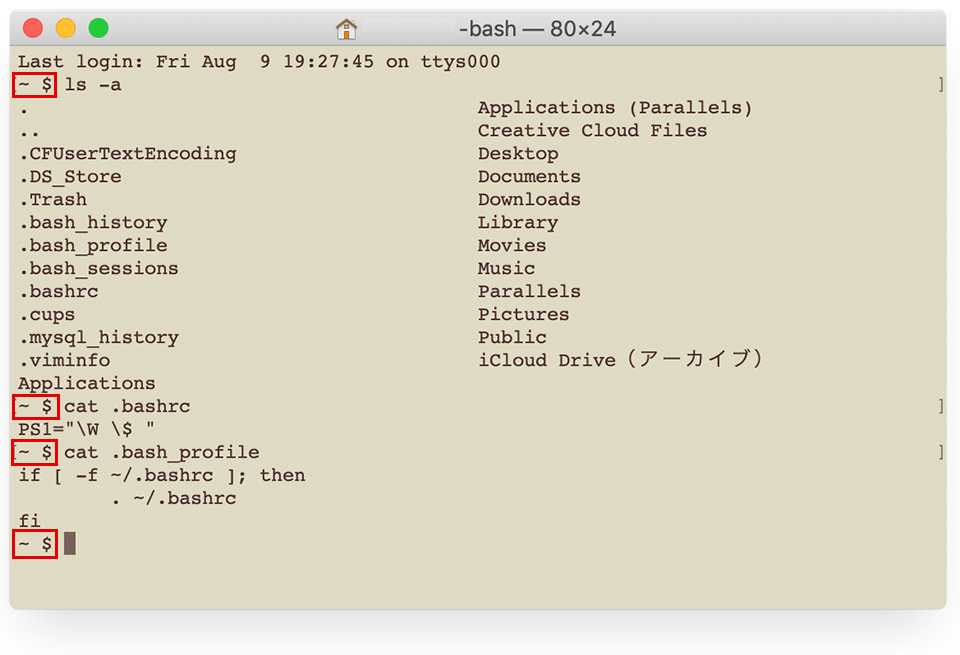
.bashrc と.bash_profile を反映
.bashrc と.bash_profile の変更を反映するために、ターミナルで以下を実行します。
source ~/.bashrc return source ~/.bash_profile return
以下はプロンプトの書式変更後のターミナルの例です。
関連項目:環境設定ファイル
ファイルのアクセス権限
Unix 系のシステムでは1台のコンピュータを複数のユーザで使用できるように設計されていて、ユーザごとにアクセスできるディレクトリやファイル(実行できるコマンド)など「どのユーザの権限で何ができるか」が決められています。
そして、ユーザの権限などを効率よく管理するために「グループ」が用意され、「ユーザ」は「グループ」に属するようになっています。
また、あらゆる権限が与えられているユーザを「スーパーユーザ」や「root ユーザ」と呼びます。
一般的な UNIX 系のシステムでは root というユーザー名でログインすると、あらゆるコマンドの実行やファイル操作ができるようになりますが、macOS では root でログインしたり、一時的に root に移行して操作を行ったりすることがデフォルトではできないようになっています。
スーパーユーザの権限が必要な操作を行うには、管理者として登録されているユーザが sudo コマンドを使用して一時的にスーパーユーザの権限を取得してコマンドを実行します。
関連項目:ユーザとグループ
sudo スーパーユーザ権限で実行
sudo コマンドを使うと、パッケージのインストールや Web サーバーの起動などスーパーユーザの権限(root 権限)が必要なコマンドを実行することができます。
以下が書式です。
sudo [オプション] [コマンド]
macOS では sudo コマンドが実行できるのは、管理者として登録されているユーザーだけになります。また、実行する際は自分のパスワードを入力する必要があります。
例えば、sudo の設定ファイル「/etc/sudoers」はスーパーユーザにしか読み書きできないため普通に less コマンドで表示しようとするとエラーになります。
less /etc/sudoers return /etc/sudoers: Permission denied #権限がないためエラー
以下は sudo コマンドを使って実行する例です。
sudo less /etc/sudoers return Password: #パスワードを求められるので入力して return を押す #less コマンドが実行され /etc/sudoers が表示される # # Sample /etc/sudoers file. # # This file MUST be edited with the 'visudo' command as root. # # See the sudoers man page for the details on how to write a sudoers file. ## # Override built-in defaults ## Defaults env_reset ・・・以下省略・・・
また、sudo コマンドに -u オプションとユーザを指定すると、指定したユーザとしてコマンドを実行することができます。
sudo -u ユーザ名 コマンド
以下はユーザ foo として ls コマンドを実行する例です。
sudo -u foo ls /Users/foo return Password: #パスワードを求められるので入力して return を押す(以下は実行結果の例) Desktop Downloads Movies Pictures fooDir Documents Library Music Public
su コマンド
su コマンドを使って、別のユーザとしてコマンドを実行することもできます。
以下は su コマンドで一時的にユーザ foo としてコマンドを実行し、exit コマンドで元のユーザに戻る例です。以下の例では現在のユーザのプロンプトは「~ $ 」です。
~ $ su foo return Password: #パスワードを入力して return bash-3.2$ #プロンプトが変わる bash-3.2$ ls ~ return #ユーザ foo としてコマンドを実行 Desktop Downloads Movies Pictures fooDir Documents Library Music Public bash-3.2$ exit return #ユーザ foo を終了 exit ~ $ #プロンプトが元に戻る
su コマンドは、ログインし直さずに他のユーザーに切り替えるコマンドです。
su は「Substitute User」の意味です。
以下が書式です。
su [オプション] ユーザー
一般的な Unix システムでは「スーパーユーザー( root ユーザー)」の権限でシェルを起動してマンドを実行する場合に使用しますが、macOS では root でログインしたり、一時的に root に移行して操作を行うことがデフォルトではできないようになっています。
そのため、ユーザを省略してスーパーユーザに移行しようとするとパスワードの入力は求められますが、管理者として登録されているユーザーのパスワードを入力してもデフォルトでは以下のように「su: Sorry」と表示され移行することができません。
su return Password: #パスワードを入力して return su: Sorry
Apple 関連ページ:Mac でルートユーザを有効にする方法やルートパスワードを変更する方法
/etc/sudoers
「/etc/sudoers」には、sudo コマンドを使ってどのユーザーがどんなコマンドを使用できるかが設定されています。
また、「/etc/sudoers」は専用の visudo コマンドを使って編集する必要があります。
sudoers の書式は以下のようになっています。
ユーザー ホスト=(権限) コマンド
例えば、「foo ALL=(bar) ls」はユーザ「foo」は全てのホスト(ALL)で「bar」として(bar の権限で)「ls」コマンドを実行できるというような意味になります。
sudoers の最後の方に以下のような記述があります。これは「root」と「%admin(admin グループ)」に対して、全ての権限(全てのホストで全てのコマンドを実行する権限)を与える設定です。
## # User specification ## # root and users in group wheel can run anything on any machine as any user root ALL = (ALL) ALL %admin ALL = (ALL) ALL
パーミッション
Unix 系のシステムでは、全てのファイルやディレクトリに対して「所有者」「所有グループ」「その他のユーザ」(パーミッションを与える対象)ごとに、「読み出し(r)」「書き込み(w)」「実行(x)」の権限(パーミッション)を設定することができます。
初期状態では「所有者」はファイルやディレクトリの作成者、「所有グループ」は所有者のデフォルトのグループ(プライマリグループ:ログイン時のグループ)になります。
パーミッションの確認 ls -l
ファイルやディレクトリに設定されているパーミッションを確認するには、ls コマンドに詳細表示をする -l オプションを指定して実行します。
以下は root ディレクトリで ls -l コマンドを実行した際のスクリーンショットです。パーミッションや所有者、所有グループなどの情報が表示されます。
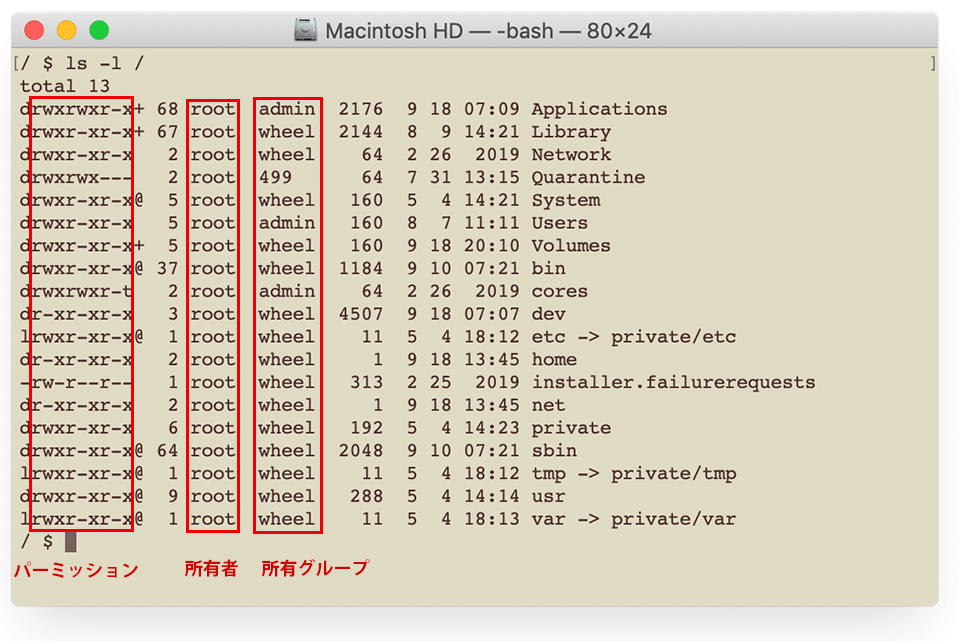
左側の「rwxrwxr-x」や「rw-r-xr-x」の9文字の部分がパーミッションを表します。
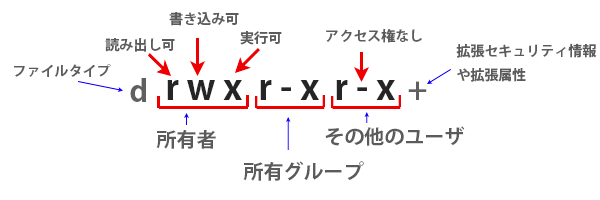
パーミッションを表す9文字は、3文字ごとに「所有者」「所有グループ」「その他のユーザ」に対するアクセス権を表しています。
左端の d や - はファイルタイプを表す文字で、d はディレクトリ、- はファイル、l はシンボリックリンクを意味します。
右端の + は拡張セキュリティ情報(ACL など)、@ は拡張属性が設定されていることを表しています。
以下はアクセス権(パーミッション)の文字(シンボル)の意味及び数値で表した場合の値です。
| 文字 | 意味 | 数値 |
|---|---|---|
| r | 読み出し可能(read) | 4 |
| w | 書き込み可能(write) | 2 |
| x | 実行可能(excute) | 1 |
| - | アクセス権なし | 0 |
同じパーミッションでもファイルとディレクトリでは実行できることが違います。
例えば、ファイルの書き込み(w)が許可されていなくても、ファイルの削除や名前の変更はできてしまいます。
ファイルの削除や名前の変更は、ファイルが保存されているディレクトリの書き込み(w)が許可されているかどうかによります。
| ファイルのパーミッション | ディレクトリのパーミッション | |
|---|---|---|
| 読み出し(r) | ファイルの内容を表示できる | ディレクトリの一覧を表示できる |
| 書き込み(w) | ファイルにデータを書き込める | ディレクトリの一覧を書き換えられる
|
| 実行(x) | ファイルをコマンドとして実行できる | 配下のディレクトリに移動できる |
以下は foo というユーザで touch コマンドで test.txt というファイルを作成して、ls -l コマンドでパーミッションを確認する例です。
所有者はファイルの作成者 foo で、所有グループはユーザ foo が作成された際に自動的に所属したプライマリグループ staff になっています。
所有者(foo)のパーミッションは「rw-」で、所有グループ(staff)及びその他のユーザのパーミッションは「r--」が設定されているのがわかります。
これは所有者は書き込みができますが、所有者以外は読み出しのみが可能であることを意味します。
新規に作成するファイルのパーミッションは、umask コマンドで設定されています。
touch test.txt return #ファイルを作成 ls -l test.txt return #パーミッションを確認 -rw-r--r-- 1 foo staff 0 9 18 19:50 test.txt
以下は foo というユーザで mkdir コマンドで test というディレクトリを作成して、ls -ld コマンド(ディレクトリなので -d を併用)でパーミッションを確認する例です。
所有者(foo)のパーミッションは「rwx」で、所有グループ(staff)及びその他のユーザのパーミッションは「r-x」が設定されているのがわかります。
これは所有者はディレクトリ内でのファイルの作成、削除、変更が可能ですが、所有者以外はディレクトリの一覧表示やディレクトリへの移動のみが可能であることを意味します。
mkdir test return #ディレクトリを作成 ls -ld test return #パーミッションを確認 drwxr-xr-x 2 foo staff 64 9 18 19:50 test
以下は ls コマンドのパーミッションを確認する例です。
所有者は root、所有グループは wheel で、「所有者」「所有グループ」「その他のユーザ」の全てに「x(実行可能)」が設定されていて全てのユーザが ls コマンドを実行できるのがわかります。
ls -l /bin/ls return -rwxr-xr-x 1 root wheel 38704 5 4 14:26 /bin/ls
Public ディレクトリ
macOS では各ユーザのホームディレクトリに Public というディレクトリ (フォルダ)があります。
以下はユーザ foo の Public ディレクトリのパーミッションを確認する例です。
Public はファイル共有用のディレクトリで、全てのユーザに「読み出し(r)」と「実行(x)」が許可されていて閲覧可能になっています。
ls -ld Public/ return drwxr-xr-x+ 4 foo staff 128 7 29 19:02 Public/
また、Public の中には Drop Box という特別なディレクトリがあり、全てのユーザに「書き込み(w)」と「実行(x)」が許可されていてファイルを保存できるようになっています。
但し、所有者以外に「読み出し(r)」は許可されていないので、所有者以外はディレクトリの中身を見ることはでないようになっています。
cd Public/ return #Public へ移動 ls -l return total 0 drwx-wx-wx+ 3 foo staff 96 7 29 19:02 Drop Box
パーミッションの変更 chmod
ファイルやディレクトリのパーミッションを変更するには chmod コマンド(change file modes)を使用します。
chmod コマンドは、そのファイルやディレクトリの所有者またはスーパーユーザ(root ユーザ)だけが実行できます。
以下が書式です。
chmod [オプション] パーミッション ファイル1 ファイル2 ...
以下は主なオプションです。
| オプション | 意味 |
|---|---|
| -R | ディレクトリ内のファイルとディレクトリを再帰的に変更する |
| -f | 変更できなかった場合にエラーメッセージを表示しない |
| -v | 処理した内容(ファイル名やディレクトリ名)を出力する |
chmod でパーミッションを変更(指定)するには「数値」を使用する方法と、「文字(シンボル)」を使用する2つの方法があります。
数値でパーミッションを指定
「所有者」「所有グループ」「その他のユーザ」に対して、それぞれ8進数の数値(通常は3桁の数値)でパーミッションを指定します。
suid(set-user-ID)、sgid(set-group-ID)、sticky bit などの特殊なパーミッションを設定する場合は4桁の数値で指定します。
各パーミッションの値は以下のようになっていて、実際に指定する場合は許可するパーミッションの数値を合計した値を指定します。
| パーミッション | 数値 |
|---|---|
| 読み出し可能(r) | 4 |
| 書き込み可能(w) | 2 |
| 実行可能(x) | 1 |
| アクセス権なし(-) | 0 |
3文字のパーミッションのそれぞれをアクセス権がある部分を1、ない部分を0とする2進数にすると、例えば「rwx」は「111」、「rw-」は「110」、「r-x」は「101」のようになります。
そしてそれらの3桁の2進数を8進数に変換して、パーミッションの数値としています。
| パーミッション | 2進数 | 8進数 |
|---|---|---|
| rwx | 111 | 7 |
| rw- | 110 | 6 |
| r-x | 101 | 5 |
| r-- | 100 | 4 |
| -wx | 011 | 3 |
| -w- | 010 | 2 |
| --x | 001 | 1 |
| --- | 000 | 0 |
「所有者」「所有グループ」「その他のユーザ」のそれぞれに対して指定するパーミッションの組み合わせは下記の8通りになります。
| パーミッション | 数値 | 意味 |
|---|---|---|
| 「読み出し」と「書き込み」と「実行」(全て)を許可(rwx) | 7 | 4 + 2 + 1 |
| 「読み出し」と「書き込み」を許可(rw-) | 6 | 4 + 2 + 0 |
| 「読み出し」と「実行」を許可(r-x) | 5 | 4 + 0 + 1 |
| 「読み出し」のみを許可(r--) | 4 | 4 + 0 + 0 |
| 「書き込み」「実行」を許可(-wx) | 3 | 0 + 2 + 1 |
| 「書き込み」のみを許可(-w-) | 2 | 0 + 2 + 0 |
| 「実行」のみを許可(--x) | 1 | 0 + 0 + 1 |
| 全て許可しない(---) | 0 | 0 + 0 + 0 |
パーミッションは左から「所有者」「所有グループ」「その他のユーザ」なので、それぞれに上記のパーミッションを数値で指定します。
例えば、「所有者」に全てを許可(7)し、「所有グループ」と「その他のユーザ」には「読み出しと実行」を許可(5)する場合は「755」と指定します。
以下はカレントディレクトリに test というディレクトリを作成し、パーミッションを「700(所有者以外はアクセスを許可しない)」に変更する例です。
mkdir test return #ディレクトリを作成 ls -ld test return #パーミッションを確認 drwxr-xr-x 2 foo staff 64 9 19 17:04 test #755 chmod 700 test return #パーミッションを 700 に変更 ls -ld test return #パーミッションを確認 drwx------ 2 foo staff 64 9 19 17:04 test #700
文字でパーミッションを指定
以下は、文字(シンボル)でパーミッションを指定する場合の書式です。
chmod [対象ユーザ] オペレータ パーミッション ファイル名
| 意味 | 文字(シンボル) |
|---|---|
| 所有者(user) | u |
| 所有グループ(group) | g |
| その他のユーザ(othres) | o |
| 全て(all) | a |
対象を指定しなかった場合も全てのユーザーが対象となりますが、その場合はマスク値(umask)の影響を受けます。
| 意味 | 文字(シンボル) |
|---|---|
| 権限を追加 | + |
| 権限を削除 | - |
| 権限を設定(元の設定をクリアして権限を指定) | = |
| 意味 | 文字(シンボル) |
|---|---|
| 読み出し(read) | r |
| 書き込み(write) | w |
| 実行(execute) | x |
以下はファイル test.txt のその他のユーザ(o)の「読み出し(r)」の許可を削除(-)する例です。
ls -l test.txt return #パーミッションを確認 -rw-r--r-- 1 foo staff 0 9 18 19:50 test.txt #644 chmod o-r test.txt return #その他のユーザの読み出しのパーミッションを削除 ls -l test.txt return #パーミッションを確認 -rw-r----- 1 foo staff 0 9 18 19:50 test.txt #640
以下はファイル test.txt の所有グループ(g)の「書き込み(w)」の許可を追加(+)する例です。
ls -l test.txt return #パーミッションを確認 -rw-r----- 1 foo staff 0 9 18 19:50 test.txt #640 chmod g+w test.txt return #所有グループに書き込みのパーミッションを追加 ls -l test.txt return #パーミッションを確認 -rw-rw---- 1 foo staff 0 9 18 19:50 test.txt #660
以下はファイル test.txt のその他のユーザ(o)の「読み出し(r)」の許可を設定(=)する例です。
ls -l test.txt return #パーミッションを確認 -rw-rw---- 1 foo staff 0 9 18 19:50 test.txt #660 chmod o=r test.txt return #その他のユーザの読み出しのパーミッションを設定 ls -l test.txt return #パーミッションを確認 -rw-rw-r-- 1 foo staff 0 9 18 19:50 test.txt #664
以下はファイル test.txt の全てのユーザ(a)の「実行(x)」の許可を追加(+)する例です。
ls -l test.txt return #パーミッションを確認 -rw-r--r-- 1 foo staff 0 9 25 10:02 test.txt chmod a+x test.txt return #全てのユーザに実行のパーミッションを追加 ls -l test.txt return #パーミッションを確認 -rwxr-xr-x 1 foo staff 0 9 25 10:02 test.txt
対象を指定しなかった場合も全てのユーザーが対象となりますが、全てのユーザ(a)を対象に指定する場合と異なり、マスク値(umask)の影響を受けます。
ls -l test2.txt return #パーミッションを確認 -rw-r--r-- 1 foo staff 0 9 25 10:03 test2.txt umask return #マスク値を確認 0022 #所有グループとその他のユーザの書き込み(w)の権限を制限する設定(デフォルト) chmod +w test2.txt return #対象を指定せずに書き込み(w)のパーミッションを追加 ls -l test2.txt return #パーミッションを確認 -rw-r--r-- 1 foo staff 0 9 25 16:00 test2.txt #umask の影響を受け、所有グループとその他のユーザには書き込みのパーミッションは追加されない chmod a+w test2.txt return #全てのユーザ(a)に書き込みのパーミッションを追加 ls -l test2.txt return #パーミッションを確認 -rw-rw-rw- 1 foo staff 0 9 25 16:00 test2.txt #全てのユーザに書き込みのパーミッションが追加される touch test3.txt return #test3.txt を新規作成 ls -l test3.txt return #パーミッションを確認 -rw-r--r-- 1 foo staff 0 9 25 16:10 test3.txt chmod +x test3.txt return #対象を指定せずに実行(x)のパーミッションを追加 ls -l test3.txt return #パーミッションを確認 -rwxr-xr-x 1 foo staff 0 9 25 16:10 test3.txt #umask で実行は制限されていないので、全てのユーザに実行のパーミッションが追加される
対象ユーザは複数指定することができます。
以下はファイル test.txt の所有者(u)と所有グループ(g)に「実行(x)」の許可を追加(+)する例です。
ls -l test.txt return #パーミッションを確認 -rw-rw-r-- 1 foo staff 0 9 18 19:50 test.txt #664 chmod ug+x test.txt #所有者と所有グループに実行のパーミッションを追加 ls -l test.txt return #パーミッションを確認 -rwxrwxr-- 1 foo staff 0 9 18 19:50 test.txt #774
以下の3つのコマンドは、いずれも同じことになります。
カンマの後にスペースを入れるとエラーになります。
chmod 755 test.txt chmod u=rwx,go=rx test.txt chmod u=rwx,go=u-w test.txt
-R オプションを指定して chmod コマンドを実行するとディレクトリ以下のファイルやディレクトリをまとめてパーミッションを変更することができます。
ls -ld test return #現在の test ディレクトリのパーミッションを確認 drwxr-xr-x 5 foo staff 160 9 20 08:15 test #755 ls -l test/ return #現在の test ディレクトリ配下のパーミッションを確認 total 0 -rw-r--r-- 1 foo staff 0 9 20 08:15 abc.txt #644 drwxr-xr-x 2 foo staff 64 9 20 08:15 testDir #755 -rw-r--r-- 1 foo staff 0 9 20 08:15 xyz.txt #644 chmod -R o-r test/ return #test ディレクトリ及び配下の「その他のユーザ」の読み出し権限を削除 ls -ld test return # test ディレクトリのパーミッションを確認パーミッションを確認 drwxr-x--x 5 foo staff 160 9 20 08:15 test #751 ls -l test/ return # test ディレクトリ配下のパーミッションを確認 total 0 -rw-r----- 1 foo staff 0 9 20 08:15 abc.txt #640 drwxr-x--x 2 foo staff 64 9 20 08:15 testDir #751 -rw-r----- 1 foo staff 0 9 20 08:15 xyz.txt #640
デフォルトのパーミッション設定 umask
ファイルやディレクトリを作成する際にデフォルトで適用されるパーミッションは、umask コマンドで設定(または確認)することができます。
umask はシステムの管理ポリシーによりデフォルトの値が設定されています。
macOS の場合、umask の設定値は「022」となっています。実際には4桁で「0022」と表示されます。
umask return #現在の umask の値を確認 0022
umask コマンドは bash の内部コマンドなので、help コマンド(help umask)でも概要を表示できます。
以下が umask コマンドの書式です。
umask [オプション] [値(mode)]
以下が主なオプションです。
| オプション | 意味 |
|---|---|
| -p | 値を指定しない場合、現在の設定値を「umask 値」の形式で表示 |
| -S | 値を指定しない場合、現在の設定値をシンボルモード(rwx 等)で表示 |
umask -p return # -p オプションを指定して現在の umask の値を確認 umask 0022 umask -S return # -S オプションを指定してシンボルモードで表示 u=rwx,g=rx,o=rx
Unix 系のシステムではファイルやディレクトリを作成する際のパーミッションは制限が最も少ない状態(ファイル:666、ディレクトリ:777)になっています。
しかし、この状態では全てのユーザーから書き込みや削除が可能になってしまうため、umask を使ってパーミッションを制御(制限)するようになっています。
umask で指定(設定)するのはパーミッションそのものではなく,許可しないビットを指定ます。
chmod コマンドと同じように8進数を利用しますが、umask の場合は許可を削除(アクセスを禁止)するビットを「1」として指定します。
例えば、全てを許可する(何も禁止しない)場合は、000 000 000 で umask は「000」、その他のユーザの全てのアクセスを禁止するには 000 000 111 となり umask は「007」を指定することになります。
初期状態の umask の値 022 は 000 010 010 なので所有グループとその他のユーザから書き込み(w)の権限を削除しています。
umask の値からパーミッションを算出するには、以下のようにします。以下は umask の値が 022 の場合の例です。
- ファイルの場合: 666 - 022 = 644
- ディレクトリの場合: 777 - 022 = 755
以下は、ファイルやディレクトリを新規作成する場合、umask コマンドを使ってその他のユーザには全てのアクセスを許可しないようにする例です。
umask 007 return # umask を設定 umask return # umask の値を確認 0007 umask -S return #umask の値を -S を指定して確認 u=rwx,g=rwx,o= #その他のユーザの権限なし touch umask_test.txt return # ファイルを作成 mkdir umask_testDir return # ディレクトリを作成 ls -l return # パーミションを確認 total 304 -rw-r--r-- 1 foo staff 753 8 26 10:50 01.txt #既存のファイルは変更されない drwxr-xr-x 5 foo staff 160 8 22 09:52 barDir #既存のディレクトリは変更されない ・・・中略・・・ -rw-rw---- 1 foo staff 0 9 20 11:04 umask_test.txt #その他のユーザの権限なし drwxrwx--- 2 foo staff 64 9 20 11:04 umask_testDir #その他のユーザの権限なし
なお、umask コマンドは新規に作成するファイルやディレクトリのパーミッションに適用されるので、既存のファイルやディレクトリのパーミッションを変更するには chmod コマンドを使用します。
また、ログアウトすると umask コマンドで設定した値は初期化されます(もとに戻ります)。
アクセスコントロールリスト ACL
ACL を使うと、通常のパーミッションではできない細かなアクセス制御が可能になります。
ACL(Access Control Lists)はアクセスを制御するリストというような意味で、アクセスを制御する設定の登録(ACE:Access Control Entry)の集まり(リスト)です。
ACL が設定されているディレクトリやファイルは ls -l コマンドで確認すると表示される一覧のパーミッションの右端に「+」が付いています。但し、同時に拡張属性が設定されている場合は、「+」は表示されず拡張属性を表す「@」が表示されます。
以下はユーザ foo のホームディレクトリで ls -l コマンドを実行した例です。
Desktop や Documents、Downloads などのデフォルトで用意されているディレクトリのパーミッションの右端に「+」が表示されていて、ACL が設定されているのが確認できます。
ls -l return total 0 drwx------+ 3 foo staff 96 9 20 15:46 Desktop drwx------+ 3 foo staff 96 9 20 15:46 Documents drwx------+ 3 foo staff 96 9 20 15:46 Downloads drwx------+ 27 foo staff 864 9 20 15:46 Library drwx------+ 3 foo staff 96 9 20 15:46 Movies drwx------+ 3 foo staff 96 9 20 15:46 Music drwx------+ 3 foo staff 96 9 20 15:46 Pictures drwxr-xr-x+ 4 foo staff 128 9 20 15:46 Public drwxr-xr-x 2 foo staff 64 9 20 15:51 fooDir
ACL の内容を確認するには、ls コマンドに -le オプションを指定して実行します。
ls -le /Users/foo return total 0 drwx------+ 3 foo staff 96 9 20 15:46 Desktop 0: group:everyone deny delete drwx------+ 3 foo staff 96 9 20 15:46 Documents 0: group:everyone deny delete drwx------+ 3 foo staff 96 9 20 15:46 Downloads 0: group:everyone deny delete ・・・以下省略・・・
例えば、上記の Desktop などの ACL には「0: group:everyone deny delete」という ACE が1つ登録されていて、これは「所有者を含む全てのユーザ(group:everyone)にディレクトリの削除(delete)を禁止(deny)する」という内容です。
macOS では Desktop や Applications などの重要なディレクトリが削除されないように OS によって ACL が設定されています。
ACL の設定は、Finder でフォルダを選択して右クリックで「情報を見る」を選択して確認することもできます。
「共有とアクセス権」で「カスタムアクセス権が割り当てられています」と表示されている場合は ACL のアクセス権が設定されています。
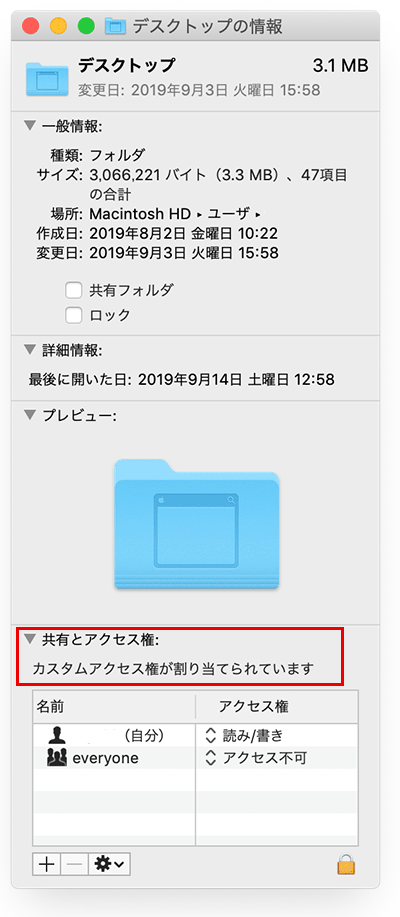
ACE の設定
ACL の個々のアクセス権(の登録)を ACE(Access Control Entry:アクセスコントロールエントリ)と呼びます。
ACL(Access Control Lists)は ACE のリストのことで、各 ACE に特定のユーザーやグループのアクセス権の定義が設定(登録)されています。
macOS では、ACE を設定するのに chmod コマンドを使用します。
ACE の設定(chmod コマンド)は、そのファイルやディレクトリの所有者またはスーパーユーザ(root ユーザ)だけが実行できます。
ACE を設定する場合は +a オプションを、解除する場合は -a オプションを使用します。
以下が書式です。
ACE を設定する場合: chmod +a "ACE の内容" ファイル(またはディレクトリ)
ACE を解除する場合: chmod -a "ACE の内容" ファイル(またはディレクトリ)
"ACE の内容" は、アクセス権限を許可するには allow を使い、禁止するには deny を使って以下のように指定します。
許可する場合: ユーザ(またはグループ) allow 権限
禁止する場合: ユーザ(またはグループ) deny 権限
以下は、カレントディレクトリのファイル sample.txt に、ユーザ「bar」に書き込み(write)許可(allow)の、ユーザ「foo」に削除(delete)禁止(deny)の ACE を設定(+a)する例です。
chmod +a "bar allow write" sample.txt return #ACL(ACE)を設定 ls -le sample.txt return #ACL(ACE のリスト)を確認 -rw-r--r--+ 1 xxxx staff 519 9 9 08:47 sample.txt 0: user:bar allow write #ACE chmod +a "foo deny delete" sample.txt return #ACL(ACE)を設定 ls -le sample.txt return #ACL を確認 -rw-r--r--+ 1 xxxx staff 519 9 9 08:47 sample.txt 0: user:foo deny delete #ACE(新たに追加されたエントリ) 1: user:bar allow write #ACE
以下は前述の例で設定した ACL(ACE)を解除(-a)する例です。
chmod -a "bar allow write" sample.txt return #ACL(ACE)を解除 chmod -a "foo deny delete" sample.txt return #ACL(ACE)を解除 ls -le sample.txt return #ACL を確認(ACE は全て解除され、リストは表示されない) -rw-r--r-- 1 xxxx staff 519 9 9 08:47 sample.txt
ACL を全て解除するには -N オプリョンを指定します。
以下はディレクトリ test に ACL を設定して、その後、全て解除する例です。
chmod +a "foo allow write" test return #ACL(ACE)を設定 chmod +a "bar allow write" test return chmod +a "everyone deny delete" test return s -lde test return #ACL を確認(ディレクトリなので d オプションも指定) drwxr-x--x+ 5 xxxx staff 160 9 20 08:15 test 0: group:everyone deny delete 1: user:bar allow add_file 2: user:foo allow add_file chmod -N test return #ACL(ACE)を全て解除 ls -lde test return #ACL を確認(削除されているので表示されない) drwxr-x--x 5 xxxx staff 160 9 20 08:15 test
シェルスクリプト
シェルに実行させたい操作(コマンドやオプション、制御構文など)をテキストファイルにまとめて記述したものを「シェルスクリプト」と呼びます。
よく使う処理や定期的に実行する処理などをシェルスクリプトとして保存しておけば、簡単に呼び出して実行することができます。
シェルスクリプト自体は単なるテキストファイルで、「vim」や「nano」などのテキストエディタを使って作成・編集することができます。GUI のテキストエディタを使うこともできます。
以下は、macOS の標準シェルである bash によるシェルスクリプトの基本的なことについてになります。
シェルスクリプトの実行
シェルスクリプトは「bash ファイル名(パス)」のように、スクリプトを処理する実行コマンド(bash や zsh コマンド)と、スクリプトが記述されたファイルのパスを指定することで実行することができます。
シェルスクリプトが実行される際は、別のシェルが新たに起動してそのシェルで実行され、シェルスクリプトが終了するとそれを起動した元のシェルに戻ります。
最もシンプルなシェルスクリプトはコマンドを記述しただけのテキストファイルで、例えば以下のようにコマンドを記述したファイルを作成して実行することができます。
以下は「hello」というファイルを作成し、「echo "Hello, $(whoami)"」というコマンドを記述して、bash コマンドで記述したスクリプトを実行する例です。
複数行に渡るコマンドや制御構文を記述する場合は、vim や nano、または GUI のテキストエディタを使いますが、以下の例の場合はcat コマンドとリダイレクトで作成しています。
cat > hello return #hello というファイルに以下を記述 echo "Hello, $(whoami)" control + d #cat を終了して記述した内容を保存 cat hello return #hello というファイルの内容を確認(念の為) echo "Hello, $(whoami)" bash hello return #bash コマンドでシェルスクリプト hello を実行 Hello, foo #コマンドが実行されて出力される(カレントユーザが foo の場合)
ファイルの拡張子
シェルスクリプトのファイルには「.sh」のような拡張子を付けることができますが、拡張子は付けない方が(拡張子を指定する必要がないので)コマンドとして実行しやすいです。
スクリプト名だけで実行
bash コマンドを使わずに、スクリプト名だけで処理を実行できるようにするには以下のようにします。
- スクリプトの1行目に実行コマンド(#!/bin/bash)を指定
- chmod コマンドを使ってファイルに実行の権限を設定(実行可能属性を追加)
- コマンド検索パスに登録されている場所に配置(またはパス付きで実行)
※ zsh で実行する場合は !/bin/bash の代わりに #!/bin/zsh と記述します。
以下は、「hellotime」というファイルを作成し、コマンドを記述して bash コマンドを使わずにスクリプト名だけで処理を実行できるようにする例です。
テキストエディタで以下の内容のファイルを作成しという名前でカレントディレクトリ(ホームディレクトリ)に保存します。
#!/bin/bash echo "Hello, `whoami` !" #または echo "Hello, $(whoami) !" date "+It's %H:%M, now."
1行目は実行コマンド bash の指定(#!/bin/bash)です。
※スクリプト名だけで実行できるようにするには、スクリプトの先頭行で「#!」に続けてスクリプトを実行するコマンドのフルパスを指定します。
この記述により新たに別の bash が起動して処理を実行します。
「#!」とコマンドのパスの間にスペースはあってもなくても大丈夫です。
#! スクリプトを実行するコマンドのフルパス(1行目に記述)
スクリプトを実行するコマンド bash のフルパスは「/bin/bash」になります(コマンドのパスは type や which コマンドで確認できます)。
2行目と3行目はこのシェルスクリプトの内容です。
2行目は echo コマンドを使って「Hello カレントユーザ名!」と出力する記述です。コマンド置換 $() または `` を使ってコマンド名「whoami」をコマンドの出力に置き換えています。
※シェルスクリプトの場合は、互換性を考慮して `` を使うのが一般的なようです。
3行目は date コマンドで + を指定して現在の時刻をフォーマット文字列で出力しています。
念の為ターミナルで以下を実行してスクリプトが正しく機能することを確認します。
bash hellotime return #bash コマンドでシェルスクリプト hellotime を実行 Hello, xxxx ! #xxxx はカレントユーザ名 It's 19:01, now.
コマンドとして実行できるように chmod コマンドでファイル hellotime に実行権限を設定します。
以下の例では全てのユーザ(a)に実行(x)を許可するように「a+x」を指定しています(自分だけに許可する場合は u+x)。
chmod a+x hellotime return #ファイルに実行権限を設定 ls -l hellotime return #パーミッションを確認 -rwxr-xr-x 1 xxxx staff 63 9 21 16:55 hellotime
実行権限を設定したので、シェルスクリプトのパスを指定すれば実行することができます。
hellotime がカレントディレクトリにある場合は、カレントディレクトリ「.」からパスを指定します。
./hellotime /return #パスを指定してシェルスクリプトを実行
Hello, xxxx !
It's 19:12, now.
パスを指定せず、スクリプト名だけで実行するにはファイルをコマンド検索パスに登録されている(パスの通っている)ディレクトリに配置します。
自分専用の場合はホームディレクトリ下に「bin」ディレクトリ(~/bin)を作成して、パスを通して、.bash_profile などに記述しておきます。
以下は mkdir コマンドでホームディレクトリに「bin」ディレクトリを作成し、mv コマンドでスクリプト hellotime を移動する例です。
~/bin にパスが通って入れば、以下のようにスクリプト名だけで実行することができます。
mkdir ~/bin /return #ホームディレクトリに bin ディレクトリを作成
mv hellotime ~/bin/ return #作成した ~/bin へファイルを移動
hellotime return #スクリプト名だけで実行
Hello, xxxx !
It's 19:59, now
他のユーザーも実行する場合は「/usr/local/bin」に配置するのが一般的です。
「/bin」や「/usr/bin」はシステムのコマンドを保存する場所になります。
以下は sudo と mv コマンドを使ってファイルをに移動する例です(ディレクトリに書き込みができるのは root のみ)。
sudo mv hellotime /usr/local/bin/ return #ファイルを移動 Password: #パスワードを入力して return #書き込み権限があるのは root のみ ls -ld /usr/local/bin drwxr-xr-x 10 root wheel 320 9 22 08:39 /usr/local/bin
改行・空白文字・引用符・コメント
シェルスクリプトでは「読みやすく」するため、適宜空白や空行を入れたりすることができます。
改行
シェルスクリプトは、「行単位」で処理されます。
基本的には、コマンドラインで return を押すところで改行します。
また、処理のまとまりごとに改行(空行)を入れて読みやすくすることができます。
挿入された空行は実行結果に影響はありません。
空白文字(半角スペースやタブ)
空白文字はコマンドラインの入力方法と同様、コマンドや引数の区切りとして扱われます(タブはコマンドラインでは別の意味を持ちますが)。
空白文字は1つでも複数でも動作は同じで、行頭や行末に入れても問題ありません。
空白文字を入れて文字の位置を揃えたりすることができます。
引用符
シェルスクリプトの中のダブルクオート(")やシングルクオート(')、エスケープ文字(\)は、コマンドラインと同じように機能します。
シェルにとって特別な意味を持つ記号(ワイルドカードの * など)は、引用符(" ')やバックスラッシュ(\)を使って必要に応じてエスケープします。
ダブルクォートの中では $ を使った変数やコマンド置換(バッククォート ` も)は展開されます。
コメント
シェルスクリプトの中では「#」以降がコメントとなります。
コメントは行頭からでも行の途中からで記述することができます。
#!/bin/bash ###1行目には実行コマンドを記述 echo "Hello, `whoami` !" #カレントユーザを出力 date "+It's %H:%M, now." #時刻を出力 #コメント ###コメント ###########コメント##########
変数
シェルスクリプトの中で変数を使う場合は、「変数名=値」の形式で定義します(= の前後に空白を入れることはできません)。
定義した変数の値は「$変数名」または「${変数名}」で参照することができます。
既存のシェル変数や環境変数もシェルスクリプトの中で参照することができます。
例えば、以下のようなシェルスクリプト(myscript)をカレントディレクトリに作成します。
#!/bin/bash myvar="my variable" #変数の定義(空白を含むのでダブルクォートまたはシングルクォートで括る) echo "myvar: $myvar" #定義した変数を出力(myvar: 変数の値) echo "PATH: $PATH" #環境変数(PATH)の出力(PATH: 環境変数 PATH の値) echo "LANG: $LANG" #環境変数(LANG)の出力 (LANG: 環境変数 LANG の値)
この例の場合、上記スクリプトは以下のように記述しても同じ結果になります。
空白を含む文字列を変数に代入するには引用符で囲む必要がありますが、echo コマンドの引数には複数の引数を(空白区切りで)指定できるので引用符で括らなくても問題ありません。
但し、引用符で括る場合はダブルクォートを使う必要があります(シングルクォートで括るとその中の変数は展開されません)。
#! /bin/bash myvar='my variable' #空白を含む文字列を変数に代入するには引用符で囲む echo myvar: $myvar #echo コマンドには複数の引数を指定できる echo PATH: $PATH echo LANG: $LANG
作成したシェルスクリプト(myscript )に実行権を付与して、パス付きで実行すると以下のように変数の値が表示されます。
chmod u+x ./myscript return # 実行権を付与 ./myscript return #パス付きで実行 #以下のように変数の値が表示される myvar: my variable #定義した変数 PATH: /usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/Users/foo/bin #環境変数(PATH) LANG: ja_JP.UTF-8 #環境変数(LANG)
スクリプトの外での変数の使用
シェルスクリプトが実行される際は新たに別のシェルが起動してそこで実行され、シェルスクリプトが終了するとそれを起動した元のシェルに戻ります。
そのため、シェルスクリプトの中で定義した変数は、シェルスクリプトの中だけで使用できます。
言い換えると、シェルスクリプトの中で定義したり変更した変数は、シェルスクリプトが終了すると(スクリプトの外では)使用できませんし、変更は反映されません。
シェルスクリプトの実行後もスクリプトの中で定義した変数を参照するには、source コマンドを使って、シェルスクリプトを現在動作しているシェル(bash)に読み込ませる必要があります。
bash コマンド(bash ファイル名)の場合は、現在のシェルとは別のシェルが起動してファイルを実行しますが、source コマンドはファイルを現在のシェルで実行します。
例えば、以下のような変数を定義しただけのシェルスクリプト(myscript2)をカレントディレクトリに作成して、実行権を付与しておきます。
#!/bin/bash foo="Foo!" echo $foo
以下のようにシェルスクリプト(myscript2)を実行して、スクリプト内で定義した変数(foo)を参照しようとしても何も表示されません。
./myscript2 /return #myscript2 をパス付きで実行
Foo! #echo $foo により変数の値が表示される
echo $foo return #スクリプトの外で変数を確認
#何も表示されない
以下のように source コマンドでスクリプトを実行すると、スクリプト内で定義した変数(foo)を参照することができます。
source myscript2 #myscript2 を source コマンドで実行 Foo! #echo $foo により変数の値が表示される echo $foo return #スクリプトの外で変数を確認 Foo! #現在動作しているシェルに読み込まれているので、変数を参照できる
以下はコマンドラインでシェル変数を定義して、その後 myscript2 を実行する例です。
source コマンドでスクリプトを実行すると、スクリプト内で定義した変数によりコマンドラインで定義したシェル変数が上書きされます。
別の言い方をすると、source コマンドで実行した場合は変数の設定が現在のシェルに反映されます。
foo="bar" return #コマンドラインでシェル変数を定義 echo $foo return #シェル変数 $foo の値を確認 bar $ ./myscript2 return #シェルスクリプト(bash コマンド)を実行 Foo! #シェルスクリプトで定義した $foo が表示される $ echo $foo return #シェル変数 $foo の値を確認 bar #コマンドラインで定義した値が表示される $ source myscript2 return #myscript2 を source コマンドで実行 Foo! #シェルスクリプトで定義した $foo が表示される echo $foo return #シェル変数 $foo の値を確認 Foo! #シェルスクリプトで定義した $foo によりシェル変数が上書きされている
パラメータ展開
シェルの拡張機能の変数のパラメータ展開(Parameter Expansion)を使うと、変数の値(格納されている文字列)の一部分を取り出したり置換するなどの文字列の操作ができます。
変数の値を取り出すには、変数名の先頭に $ を付けて $変数名 とします。
{} で変数名を括って ${変数名} のように記述することもでき、他の文字列や変数と明確に区別することができます(操作を指定せずに ${変数名} とした場合は、$変数名 と同じことです)。
以下はパラメータ展開を使った変数を定義して出力するだけのスクリプト(myscript3)の例です。
#!/bin/bash
encoding=${LANG#*.} #環境変数 LANG からエンコーディング部分を取得
echo $encoding
command_path=${PATH##*:} #環境変数 PATH からユーザのパス部分を取得
echo $command_path
path="/Users/foo/Documents/sample.txt"
file=${path##*/} #変数 path からファイル部分を取得
echo $file
directory=${path%/*}*/ #変数 path からディレクトリ部分を取得
echo $directory
csvfile=${file/txt/csv} #変数 file の拡張子部分を txt から csv に置換
echo $csvfile
myVal=${val:-7} #変数 val が定義されてなければ値を 7 に設定
echo $myVal
上記スクリプトを実行すると変数の値が展開(操作)されて以下のように出力されます。
bash myscript3 return #bash コマンドで実行 UTF-8 /Users/foo/bin sample.txt /Users/foo/Documents sample.csv 7
パラメータ展開はシェルスクリプトやコマンドラインで利用することができます。
| 書式 | 操作 |
|---|---|
${変数名} |
操作を指定せず ${変数名} とした場合は、$変数名 と同じ意味 |
${変数名:開始位置} |
開始位置(先頭は0)から最後までの部分文字列を取得 |
${変数名:開始位置:長さ} |
開始位置(先頭は0)から長さで指定した部分文字列を取得 |
${変数名#パターン} |
前方からの最短マッチを削除 |
${変数名##パターン} |
前方からの最長マッチを削除 |
${変数名%パターン} |
後方からの最短マッチを削除 |
${変数名%%パターン} |
後方からの最長マッチを削除 |
${変数名/パターン/置換文字列} |
最初にマッチしたパターンを置換 |
{変数名//パターン/置換文字列} |
マッチした全てのパターンを置換 |
${#変数} |
変数に設定されている値の文字数(文字列の長さ)を取得 |
${変数名:-文字列} |
変数が設定されている場合は変数の値を返し、変数が設定されていない場合は指定した文字列を返す |
${変数名:=文字列} |
変数が設定されている場合は変数の値を返し、変数が設定されていない場合は変数に指定した文字列を設定(代入)してその文字列を返す |
${!接頭辞*} |
接頭辞で指定した文字列から始まる変数名一覧を返す |
${!接頭辞@} |
接頭辞で指定した文字列から始まる変数名の一覧を返す(上記と同じ) |
変数や文字列を連結
「$変数$変数」のように変数を続けて記述することで、変数の内容を連結することができます。
以下の例の echo での出力は10行目以外は全て同じ結果になります。
val1="abc" return #変数を設定
val2="123" return #変数を設定
echo $val1$val2 return
abc123
echo "$val1$val2" return
abc123
echo '$val1$val2' return #シングルクォートでは変数は展開されない
$val1$val2
echo ${val1}${val2} return
abc123
echo "${val1}${val2}" return
abc123
echo "${val1}""${val2}" return
abc123
val12=${val1}${val2} return #変数を連結して新たに変数 val12 を設定
echo $val12 return
abc123
以下のように変数と文字列も連結することができます。
echo $val1 return
abc
echo ${val1}def return
abcdef
val3=${val1}def${val2} return #変数と文字列を連結して新たに変数 val3 を設定
echo $val3 return
abcdef123
部分文字列(位置の指定)
位置を指定して、変数に格納されている文字列から部分文字列を取り出すことができます。
変数に対して開始位置(と長さ)を指定します。開始位置の先頭は 0 です。
${変数名:開始位置} # 開始位置から最後までの部分文字列を取り出す
${変数名:開始位置:長さ} # 開始位置から長さで指定した部分文字列を取り出す
以下は環境変数 LANG の値から部分文字列を取得する例です。
echo $LANG return #環境変数 LANG の値を表示
ja_JP.UTF-8
echo ${LANG:6} return #LANG の7文字目(6)から最後まで(先頭は 0)
UTF-8
echo ${LANG:0:5} return #LANG の1文字目(0)から5文字分(先頭は 0)
ja_JP
削除するパターンを指定(前方一致)
変数に格納されている文字列を先頭から検索して、指定したパターンと最短(または最長)でマッチした文字列までを削除することができます。
パターンには文字列だけではなく「*」や「?」などのシェルのワイルドカードが使えます。
最短マッチの場合は「#」、最長マッチの場合は「##」と指定します。
${変数名#パターン} # 前方からの最短マッチを削除
${変数名##パターン} # 前方からの最長マッチを削除
以下は環境変数 PATH の値から指定したパターンまでの文字列を削除する例です。
echo $PATH return #環境変数 PATH の値を表示
/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/Users/foo/bin
echo ${PATH#:} return #「:」だけを指定してもこの場合はパターンとしてマッチしない
/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/Users/foo/bin
echo ${PATH#*:} return #「*:」を指定して最短のマッチ「/usr/local/bin:」が削除される
/usr/bin:/bin:/usr/sbin:/sbin:/Users/foo/bin
echo ${PATH##*:} return #「*:」を指定して最長のマッチ「/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:」が削除される
/Users/foo/bin
以下は独自に設定した変数 path を使った例です。最後の最長マッチの削除は basename コマンドを使っても同じ結果になります。
path="/Users/foo/Documents/sample.txt" return #変数を設定
echo $path return #変数を表示
/Users/foo/Documents/sample.txt
echo ${path#*/} return #「*/」を指定して最短のマッチである先頭の「/」が削除される
Users/foo/Documents/sample.txt
echo ${path#/} return #「/」を指定(上記と同じ結果)
Users/foo/Documents/sample.txt
echo ${path##*/} return #「*/」を指定して最長のマッチ「Users/foo/Documents/」が削除される
sample.txt
basename $path return #basename コマンドを実行(上記と同じ結果)
sample.txt
シェルスクリプトでは、実行するスクリプト名が $0 という名前の変数(位置パラメータ)に格納されます。(関連:引数)
スクリプト名にはパスも含まれるため、ファイル名のみを取得するには、${0##*/} と記述することができます(basename コマンド `basename $0` でも取得できます)。
以下は sciptName というスクリプトを作成して確認する例です。
#! /bin/bash
echo "\$0: $0"
script_name=${0##*/} # ${変数名##パターン}でファイル名のみを取得
echo "Script Name \${0##*/}: $script_name "
basename=`basename $0`
echo "Basename (basename \$0): $basename"
sciptName に実行権を付与して、実行すると以下のようになります。
./sciptName return #スクリプトを実行
$0: ./sciptName #実行するスクリプト名
Script Name ${0##*/}: sciptName #ファイル名のみ表示
Basename (basename $0): sciptName #ファイル名のみ表示
削除するパターンを指定(後方一致)
変数に格納されている文字列を後方から検索して、指定したパターンと最短(または最長)でマッチした文字列までを削除することができます。
最短マッチの場合は「%」、最長マッチの場合は「%%」と指定します。
${変数名%パターン} 後方からの最短マッチを削除
${変数名%%パターン} 後方からの最長マッチを削除
path="/Users/foo/Documents/sample.txt" return #変数を設定
echo $path return #定義した変数を表示
/Users/foo/Documents/sample.txt
echo ${path%*/} return/ #「*/」を指定(マッチしない)
/Users/foo/Documents/sample.txt
echo ${path%/*} return #「/*」を指定して最短のマッチである「/sample.txt」が削除される*/
/Users/foo/Documents
dirname $path return #dirname コマンドを実行(上記と同じ結果)
/Users/foo/Documents
echo ${path%%/*} return #「/*」を指定して最長のマッチである全てが削除される*/
echo ${path%%foo/*} return #「foo/*」を指定して最長のマッチである「foo/Documents/sample.txt」が削除される*/
/Users/
文字列置換
検索パターンと置換後の文字列を指定して変数に格納されている文字列の置換を行うことができます。
見つかったパターンのうち最初のものだけ置換する場合は「/」を指定し、見つかったパターン全てを置換する場合は「//」を指定します。
${変数名/パターン/置換文字列} 最初にマッチしたパターンを置換文字列で置換
${変数名//パターン/置換文字列} マッチした全てのパターンを置換文字列で置換
val="jazz-pop-rock-blues" return #変数を設定
echo $val return #定義した変数を表示
jazz-pop-rock-blues
echo ${val/pop/classic} return #pop を classic に置換
jazz-classic-rock-blues
echo ${val/*-*/foo-bar} return #*-* を foo-bar に置換(*-* は jazz-pop-rock-blues にマッチ)
foo-bar
echo ${val/*-/foo-} return #*- を foo- に置換(*- は jazz-pop-rock- にマッチ)*/
foo-blues
echo ${val//-/=} return #- を全て = に置換
jazz=pop=rock=blues
変数の文字数の取得
変数に設定されている値の文字数(文字列の長さ)は、${#変数}で取得できます。
${#変数} # 変数の文字数(文字列の長さ)を取得
val="abc 123" return #変数を設定
echo ${#val} return #変数の長さ(文字数)を表示
7 #空白を含めて7文字
デフォルト値の設定
変数が設定されていない場合は指定した文字列(デフォルト値)を返したり、デフォルト値を代入することができます。
${変数名:-文字列} # 変数がセットされていない場合は値を返す
${変数名:=文字列} # 変数がセットされていない場合は値を代入する
valx="XXXX" return #変数 valx を設定
echo $valx return #変数 valx を出力
XXXX
#値が設定されている場合はその値が返される
echo ${valx:-Default Value} return
XXXX
echo ${valx:=Default Value} return
XXXX
unset valx return #変数 valx を削除
echo ${valx:-Default Value} return #指定した値が返される
Default Value
echo $valx return #${valx:- }の場合は代入はされないので何も表示されない
echo ${valx:=Default Value} return #指定した値が代入されて返される
Default Value
echo $valx return #指定した値が代入されている
Default Value
以下は、変数 myvar に変数 val7 の値が設定されていればその値を、空の場合は 777 を代入する例です。
myvar=${val7:-777} return #変数 myvar を設定
echo $myvar return #val7 が空の場合は myvar に 777 が代入される
777
変数名の一覧
接頭辞で指定した文字列から始まる変数名一覧を取得することができます。
${!接頭辞*} または ${!接頭辞@}
以下は SHELL_ や から始まる変数名の一覧を表示する例です。
echo ${!SHELL_*} return #SHELL_ から始まる変数名の一覧
SHELL_SESSION_DID_HISTORY_CHECK SHELL_SESSION_DID_INIT SHELL_SESSION_DIR SHELL_SESSION_FILE SHELL_SESSION_HISTFILE SHELL_SESSION_HISTFILE_NEW SHELL_SESSION_HISTFILE_SHARED SHELL_SESSION_HISTORY SHELL_SESSION_TIMESTAMP_FILE
echo ${!TERM@} return #TERM から始まる変数名の一覧
TERM TERM_PROGRAM TERM_PROGRAM_VERSION TERM_SESSION_ID
man bash
パラメータ展開(Parameter Expansion)の使い方(英語)は man コマンドを使って man bash で調べることができます。
どのようなものがあるかは、以下のようにパイプを使って grep コマンドで「 ${ 」から始まり「 } 」で終わる行を行番号付き(-n)で表示すると調べやすいかも知れません。
以下では見やすいように tr コマンドでスペースを削除しています。
man bash | grep -n "\${.*}$" | tr -d " "
1281:${parameter}
1303:${parameter:-word}
1307:${parameter:=word}
1312:${parameter:?word}
1318:${parameter:+word}
1321:${parameter:offset}
1322:${parameter:offset:length}
1341:${!prefix*}
1342:${!prefix@}
1346:${!name[@]}
1347:${!name[*]}
1354:${#parameter}
1361:${parameter#word}
1362:${parameter##word}
1375:${parameter%word}
1376:${parameter%%word}
1389:${parameter/pattern/string}
配列
配列を生成するにはいくつかの方法がありますが、配列は代入によって自動的に生成されます。
個別に値を代入
以下のように各要素に個別に値を代入して配列を生成(定義)することができます。
この場合、インデックス(添字)を指定する必要がありインデックス(添字)は0から始まります。
配列名[インデックス]=値
変数名(配列名)と [ の間や = の前後には空白を入れることはできません。
また、生成した配列の要素は ${配列名[添字]} で参照することができます。
fruits[0]="Apple" return #1番目の要素に値を設定
fruits[1]="Melon" return #2番目の要素に値を設定
fruits[2]="Papaya" return #3番目の要素に値を設定
echo ${fruits[0]} return #1番目の要素の値を参照
Apple
echo ${fruits[1]} return #2番目の要素の値を参照
Melon
echo ${fruits[2]} return #3番目の要素の値を参照
Papaya
echo "I love ${fruits[0]} ?" return
I love Apple ?
値をまとめて代入
以下のように括弧 ( ) の中に値のリストを指定してまとめて要素を生成することができます。
配列名=(値1 値2 値3)
変数名(配列名)と ( の間や = の前後には空白を入れることはできません。
各要素はスペースで区切ります。
括弧を使用して配列を設定した場合、各要素には宣言(記述)した順に配列のインデックス 0、1、2、... n が振り当てられます。
veges=("Onion" "Potato" "Tomato") return #3つの要素をまとめて設定
echo ${veges[0]} return #1番目の要素の値を参照
Onion
echo ${veges[1]} return #2番目の要素の値を参照
Potato
echo ${veges[2]} return #3番目の要素の値を参照
Tomato
echo "I love ${veges[1]} ?" return
I love Potato ?
値の指定は文字列や数値を直接指定する以外にも、変数の値やコマンド置換を使用してコマンドの実行結果を指定することもできます。
以下は値に変数を指定して配列を生成する例です。
val="1 7 15 23" return #変数を設定
values=($val) return #変数を指定して配列を生成
echo ${values[0]} return #1番目の要素の値を参照
1
echo ${values[2]} return #3番目の要素の値を参照
15
以下はコマンド置換 ` `を使って ls /Users/ の実行結果を配列として生成する例です。
users=(`ls /Users/`) return # ls /Users/ の実行結果を配列として生成
echo ${users[0]} return #1番目の要素の値を参照
Shared
echo ${users[2]} return #3番目の要素の値を参照
foo
ls /Users/ return # ls /Users/ の実行結果の例
Shared bar foo boo
インデックスを指定してまとめて代入
括弧 ( ) の中でインデックスを指定してまとめて要素を生成することができます。
配列名=([インデックス]=値1 [インデックス]=値2 [インデックス]=値3)
インデックスは連番である必要はありません。
flowers=([3]="Rose" [5]="Tulip" [20]="Violet") return #3つの要素をインデックスを指定してまとめて設定
echo ${flowers[3]} return #インデックス 3 の要素の値を参照
Rose
echo ${flowers[5]} return #ンデックス 5 の要素の値を参照
Tulip
echo ${flowers[20]} return #ンデックス 20 の要素の値を参照
Violet
echo "I love ${flowers[3]} ?"
I love Rose ?
括弧 ( ) の中でインデックスを指定した要素と値だけの要素を混在させることもできます。
インデックスを指定した要素の次に、インデックスを指定していない要素を入れるとその前の要素のインデックスの値+1のインデックスが割り当てられています。
trees=("Maple" [5]="Cedar" "Pine") return #3つの要素をまとめて設定
echo ${!trees[@]} return #要素のインデックスを確認
0 5 6
echo ${trees[0]} return #1番目の要素の値を参照
Maple
echo ${trees[5]} return #ンデックス 5 の要素の値を参照
Cedar
echo ${trees[6]} return #ンデックス 6 の要素の値を参照
Pine
declare -a
以下のように declare -a を使って配列を生成することもできます。
declare -a 配列名=(値1 値2 値3)
declare -a pets=("Cat" "Dog" "Fish") return #3つの要素をまとめて設定
echo ${pets[0]} return #1番目の要素の値を参照
Cat
echo ${pets[1]} return #2番目の要素の値を参照
Dog
echo ${pets[2]} return #3番目の要素の値を参照
Fish
echo "I love ${pets[2]} ?" return
I love Fish ?
全ての値を出力 / ${配列名[@]}
${配列名[@]} で全ての値を出力することができます。以下のように記述すると全ての値をまとめて表示することがきます。
echo ${fruits[@]} return #配列 fruits の全ての要素を表示
Apple Melon Papaya
echo ${veges[@]} return #配列 veges の全ての要素を表示
Onion Potato Tomato
echo ${flowers[@]} return #配列 flowers の全ての要素を表示
Rose Tulip Violet
配列の複製(再設定)
全ての値を出力する ${配列名[@]} を使って配列を複製(のようなことを)することができます。
以下は配列 fruits の全要素を新しい配列 copy_fruits の要素として設定しています。この例の場合は、元の配列 fruits の要素のインデックスが0から始まる連番になってるので複製と同じ結果になります。
echo ${fruits[@]} return #配列 fruits の全要素を出力
Apple Melon Papaya
copy_fruits=(${fruits[@]}) return #新しい配列 copy_fruits に配列 fruits の全要素を設定
echo ${copy_fruits[@]} return #配列 copy_fruits の全要素を出力
Apple Melon Papaya
echo ${copy_fruits[0]}
Apple
echo ${copy_fruits[1]}
Melon
echo ${copy_fruits[2]}
Papaya
以下はインデックスが不連続な配列 arrayX を前述と同じ方法で複製(のようなことを)する例です。
arrayY には同じ値の要素が作成されますが、インデックスは振り直され0からの連番になります。
arrayX=([3]="NY" [7]="LA" [8]="SF") return #配列 arrayX を設定
echo ${arrayX[3]} return #インデックス3の要素を出力
NY
echo ${arrayX[7]} return #インデックス7の要素を出力
LA
echo ${arrayX[8]} return #インデックス8の要素を出力
SF
arrayY=(${arrayX[@]} ) return #新しい配列 arrayY に配列 arrayX の全要素を設定
echo ${arrayY[0]} return #インデックス0の要素を出力
NY
echo ${arrayY[1]} return #インデックス1の要素を出力
LA
echo ${arrayY[2]} return #インデックス2の要素を出力
SF
echo ${arrayY[3]} return #インデックス3の要素を出力
# 存在しない
要素の数 / {#変数名[@]}
${#変数名[@]} で配列の要素数(配列に要素が幾つあるか)を調べることができます。
echo ${#fruits[@]} return #配列 fruits の要素数を表示
3
echo ${#veges[@]} return #配列 veges の要素数を表示
3
echo ${#flowers[@]} return #配列 flowers の要素数を表示
3
要素の格納場所 / ${!変数名[@]}
${!変数名[@]} で配列の要素の格納場所(各要素のインデックス)を調べることができます。
echo ${!fruits[@]} return #配列 fruits の各要素のインデックス
0 1 2
echo ${!veges[@]} return #配列 veges の各要素のインデックス
0 1 2
echo ${!flowers[@]} return #配列 flowers の各要素のインデックス
3 5 20
echo ${!trees[@]} return #配列 trees の各要素のインデックス
0 5 6
空の配列
以下のように括弧 ( ) の中に何も指定せずに記述すると空の配列を生成することができます。
empty=() return #空の配列 empty を生成
echo ${empty[0]} return #1番目の要素を表示させても空なので何も表示されない
echo ${empty[@]} return #全ての要素を表示させても空なので何も表示されない
echo ${#empty[@]} return #要素数を表示 → 0
0
echo ${!empty[@]} return #各要素のインデックスを表示させても空なので何も表示されない
以下は空の文字列を要素に持つ配列 not_empty の例です(空の配列ではありません)。
not_empty=("") return #空の文字列を要素に持つ配列 not_empty を生成
echo ${not_empty[0]} return #1番目の要素を表示(空文字列が表示されている)
echo ${not_empty[@]} return #全ての要素を表示(空文字列が表示されている)
echo ${#not_empty[@]} return #要素数を表示 → 1
1
$ echo ${!not_empty[@]} return #各要素のインデックスを表示 → [0]
0
パラメータ展開
配列も変数なので、パラメータ展開が使えます。
以下は ${#変数} で設定されている文字数を、${変数名:開始位置} や ${変数名:開始位置:長さ} で設定されいる値の部分文字列を取得する例です。
sweets=("Cake" "Apple Pie" "Chocolate" "Ice Cream") return #配列を生成
echo ${#sweets[0]} return #1番目の要素(Cake)の文字数を表示
4
echo ${#sweets[1]} return #2番目の要素(Apple Pie)の文字数を表示
9
echo ${sweets[2]:3} return #3番目の要素(Chocolate)の4文字目からの部分文字列を表示
colate
echo ${sweets[3]:0:3} return #4番目の要素(Ice Cream)の0文字目から3文字を表示
Ice
値を変更
設定されている要素の値を変更するには、定義したときと同様 配列名[インデックス]=値 で新しい値に変更することができます。
配列名[インデックス]=値
echo ${sweets[0]} return #sweets[0] の値を表示
Cake
sweets[0]="Milk Shake" return #sweets[0] の値を変更
echo ${sweets[0]} return #sweets[0] の値を表示
Milk Shake
要素の追加
配列に値(要素)を追加するには、定義したときと同様 配列名[インデックス]=値 で新たなインデックスを指定して値を設定します。
または、以下の書式で要素を追加することができます。こちらの場合は、インデックスは自動で次の値が振り当てられるます。
配列名+=(値)
echo ${fruits[@]} return #既存の配列 fruits の全要素を出力(確認)
Apple Melon Papaya
fruits[3]="Banana" return #要素を追加: 配列名[インデックス]=値
echo ${fruits[@]} return #配列 fruits の全要素を出力(追加を確認)
Apple Melon Papaya Banana
echo ${fruits[3]}
Banana
fruits+=("Orange") return #要素を追加: 配列名+=(値)
echo ${fruits[@]} return #配列 fruits の全要素を出力(追加を確認)
Apple Melon Papaya Banana Orange
echo ${fruits[4]} return #自動でインデックス4が振り当てられる
Orange
複数の要素を追加
複数の要素をまとめて追加するには、追加する要素をスペース区切りで並べて指定します。
配列名+=(値1 値2 値3)
numbers=(111 222 333) return #配列 numbers を定義(生成)
echo ${numbers[@]} return #配列 numbers の全要素を出力
111 222 333
numbers+=(444 555 666) return #配列 numbers に要素を3つ追加
echo ${#numbers[@]} return #配列 numbers の要素数を確認
6
echo ${numbers[@]} return #配列 numbers の全要素を出力
111 222 333 444 555 666
変数の値を要素として追加することもできます。
echo ${numbers[@]} return #配列 numbers の全要素を出力
111 222 333 444 555 666
new_num="777" return #変数 new_num を定義
numbers+=($new_num) return #変数の値を要素として追加
echo ${numbers[@]} return #配列 numbers の全要素を出力
111 222 333 444 555 666 777
echo ${#numbers[@]} return #配列 numbers の要素数を確認
7
変数の値がスペース区切りの文字列の場合は複数の要素として設定されます。一つの要素として配列に追加するには、変数をダブルクォート("") で囲む必要があります。
echo ${numbers[@]} return #配列 numbers の全要素を出力
111 222 333 444 555 666 777
echo ${#numbers[@]} return #配列 numbers の要素数を確認
7
new_nums="888 999" return #変数 new_num(スペース区切りの文字列)を定義
numbers+=($new_nums) return #変数の値を要素として追加(ダブルクォートなし)
echo ${#numbers[@]} return #配列 numbers の要素数を確認
9 #2つの要素が追加されている
echo ${numbers[@]} return #配列 numbers の全要素を出力
111 222 333 444 555 666 777 888 999
str_num="000 123" return #変数 new_num(スペース区切りの文字列)を定義
numbers+=("$str_num") return #変数の値を要素として追加(ダブルクォートあり)
echo ${#numbers[@]} return #配列 numbers の要素数を確認
10 #1つの要素として追加されている
配列の削除
配列の削除には、変数の削除と同じ unset コマンドを使います。
配列そのものを削除するには、unset 配列名 とし、配列の要素を削除するにはインデックスを指定して unset 配列[インデックス] とします。
unset 配列名 # 配列全体を削除
unset 配列[インデックス] # 配列の要素を削除
配列の要素を削除した場合、配列の要素数は1つ減りますが、それぞれのインデックスは変わりません。
echo ${fruits[@]} return #配列 fruits の全要素を出力
Apple Melon Papaya Banana Orange
echo ${!fruits[@]} return #配列 fruits のインデックスを確認
0 1 2 3 4
unset fruits[3] return #配列 fruits のインデックス3の要素を削除
echo ${fruits[@]} return #配列 fruits の全要素を出力
Apple Melon Papaya Orange #インデックス3の Banana が削除されている
echo ${!fruits[@]} return #配列 fruits のインデックスを確認
0 1 2 4 #インデックス3が削除されている
unset fruits return #配列 fruits を削除
echo ${fruits[@]} return #配列 fruits の全要素を出力
# 削除されているので何も表示されない
要素のインデックスに [@] を指定して全ての要素を削除する(配列を空にする)こともできます。
echo ${stones[@]} return #配列 stones の全要素を出力
Ruby Gold Diamond Saphire Topaz
unset stones[@] return #全ての要素を削除
echo ${stones[@]} return #配列 stones の全要素を出力
# 空なので何も表示されない
echo ${#stones[@]} return #配列 stones の要素数を確認
0
引数
コマンドラインで引数を指定して、シェルスクリプトに渡すことができます。
引数は指定した順番に $1、 $2、...、$n($数値)という名前の変数(位置パラメータ Positional Parameters)に格納されます。他の変数同様、${1} のように書くこともできます。$0 にはコマンド名(実行するスクリプト名)が格納されます。
また、$@ には全ての引数のリスト、$# には引数の数、$? には最後に実行したコマンドの終了ステータス、$_ には最後に実行したコマンドの最後の引数が格納されます。
| 変数 | 値(内容) |
|---|---|
| $0 | コマンド名(実行するスクリプト名) |
| $1 | 1番目の引数 |
| $2 | 2番目の引数 |
| $n | n番目の引数 |
| $@ | 全ての引数のリスト。個々に展開される($* と $@ の違い 参照) |
| $* | 全ての引数のリスト。まとめて1つの文字列として展開される |
| $# | 引数の個数 |
| $? | 最後に実行したコマンドの終了ステータス(結果)。成功時は 0 、失敗時は 1 や 0 以外。 |
| $_ | 最後に実行したコマンドの最後の引数 |
以下は引数を確認するスクリプトの例(argsTest)です。
#!/bin/bash
echo '$0: ' $0 #実行するスクリプト名
echo '${0##*/}:' ${0\#\#*/} #実行するスクリプト名(パスを除外)
echo '$1: ' $1 #1番目の引数
echo '$2: ' $2 #2番目の引数
echo '$3: ' $3 #3番目の引数
echo '$@: ' $@ #全ての引数のリスト
echo '$*: ' $* #全ての引数のリスト
echo '$#: ' $\# #引数の個数
スクリプトに実行権を付与して、引数(foo bar boo)を指定して実行すると以下のようになります。
chmod u+x argsTest return #実行権を付与
./argsTest foo bar boo return #引数(foo bar boo)を指定してスクリプトを実行
$0: ./argsTest #実行するスクリプト名
${0\#\#*/}: argsTest #実行するスクリプト名(パスを除外)
$1: foo #1番目の引数
$2: bar #2番目の引数
$3: boo #3番目の引数
$@: foo bar boo #全ての引数のリスト
$*: foo bar boo #全ての引数のリスト
$\#: 3 #引数の個数
実行するスクリプト名($0)にはパスが付いていますが、ファイル名のみを取得するにはパラメータ展開を使って ${0##*/} と記述することができます。
$* と $@ の違い
$@ と $* はどちらも全ての引数のリストを表す($1から始まる全ての位置パラメータに展開される)特殊変数ですが、ダブルクォート("")で囲んだ場合の動作が異なります。
| 変数 | ダブルクォートで囲んだ場合の動作 |
|---|---|
| $@ | 格納されている個々の値をそれぞれダブルクォート("")で囲んだ状態で展開されます 例えば引数が foo bar baz なら "foo" "bar" "baz" のように個々に展開されます |
| $* | 格納されている全ての値をまとめてダブルクォート("")で囲んだ状態で展開されます 例えば引数が foo bar baz なら "foo bar baz" のようにまとめて展開されます |
以下は $@ と $* を for 文で出力するスクリプトの例です。
#!/bin/bash echo "\$@ の場合" for i in "$@" do echo $i done echo "------------" echo "\$* の場合" for i in "$*" do echo $i done
上記のスクリプトを実行すると、$@ の場合は引数の各値が個別に変数 i に格納されて個々に出力されますが、$* の場合は全ての値がまとめて変数 i に格納され出力されます。
※ 各引数に対して個別に処理を行う場合は $@ を使用します。
bash argsTest2 foo bar baz return //上記のスクリプトに引数を指定して実行 #以下が出力 $@ の場合 foo bar baz --------- $* の場合 foo bar baz
条件判定 test
test は条件を判定するコマンドで、条件(式)を評価して真の場合は 0 (true) を、偽 の場合は 1 (false) を終了ステータスとして返すコマンドで、画面上への出力はありません。
UNIX では終了ステータスが正常終了の場合は 0、異常終了の場合は 1 を返すため、他のプログラミング言語などの真と偽の判定と 0 と 1 が逆ですが、この場合 0 は true、1 は false になります。
test コマンドは文字列や数値の比較をしたり、ファイルの有無や属性などをチェックすることができ、コマンドラインやシェルスクリプトで使うことができます。
以下が書式です。
test 条件式
test コマンドと同等の [ コマンドを使って以下のように記述することもできます。
シェルスクリプトの if 文などの制御構文では、以下の書式で記述するのが一般的です。コマンドと引数を区切る必要があるため、条件式の前後と [ ] の間にはスペースが必要です。
[ 条件式 ]
test コマンド及び [ コマンド は内部コマンドです。以下は type コマンドで調べる例です。
type test return test is a shell builtin type [ return [ is a shell builtin type [[ return [[ is a shell keyword # 外部コマンドも用意されています。 type -a test return test is a shell builtin test is /bin/test type -a [ return [ is a shell builtin [ is /bin/[
test コマンドの判定結果を出力で確認するには、実行した test コマンドの終了ステータス($?)を echo コマンドで出力します。
※コマンドの終了ステータスは $? という特別な変数に格納されています。
以下は test コマンドの終了ステータス($?)を echo コマンドで確認する例です。
「-eq」は数値が等しいかどうかを判定する場合に使用する演算子です。
test コマンドと echo コマンドを続けて記述していますが、test コマンドは「;」で終了しています。
通常、コマンドは1行につき1つ記述しますが、コマンドを1行に複数個記述して実行する場合は「;」で区切って記述します。
test 1 -eq 1; echo $? return # 1と1が等しいかを判定し終了ステータスを表示 0 # true(真) [ 3 -eq 7 ]; echo $? return # 3と7が等しいかを判定し終了ステータスを表示 1 # false(偽) [3 -eq 3 ]; echo $? return #[ と 3 の間にスペースがない -bash: [3: command not found #エラー 127 # 終了ステータス(0 以外のエラーコード) # 変数 $? には最後に実行したコマンドの終了ステータスが格納されています。
以下は演算子「-d」を使って、ファイルかどうかを判定する例です。
以下の例では test コマンドと echo コマンドを別々に実行しています。
test -f /bin/bash return #/bin/bash がファイルかどうかを判定 echo $? return #上記 test コマンドの終了ステータスを表示 0 # true(真)→ファイルである test -f /bin return #/bin がファイルかどうかを判定 echo $? return #上記 test コマンドの終了ステータスを表示 1 # false(偽)→ファイルではない echo $? return #この場合は上記 echo $? コマンドの終了ステータス 0 # true(真)→echo $? は問題なく実行された
変数はダブルクォートで囲んでおくと安全
例えば、文字列が等しくない場合は true になる演算子 != を使って判定をする際に、変数を使い、その変数が未定義であったり空であった場合エラーになります。
foo="foo" return #変数 foo を設定 test $foo != $bar; echo $? return #変数 foo と bar を比較 -bash: test: foo: unary operator expected # bar が未定義なのでエラー 2 bar="bar" return #変数 bar を設定 test $foo != $bar; echo $? return #変数 foo と bar を比較 0 #問題なく判定される(等しくないので 0 つまり true ) test $x != $foo; echo $? return #未定義の変数 x と foo を比較 -bash: test: !=: unary operator expected #変数 x が未定義なのでエラー 2 test "$x" != $foo return #変数 x をダブルクォートで囲むとエラーにならない echo $? 0 x="" return #変数 bx に "" を設定(空) test $x == ""; echo $? #変数 foo と空文字列を比較 -bash: test: ==: unary operator expected #変数 x が空なのでエラー 2 test "$x" == ""; echo $? return #変数 x をダブルクォートで囲むとエラーにならない 0
関連項目:変数と引用符
演算子
test コマンドでは、様々な演算子を使って数値や文字列、ファイルなどを判定することができます。
ファイル属性
以下はファイルの種類や属性を判定する際に使用できる演算子です。
| 演算子 | 真になる条件 |
|---|---|
| -d file | file が存在し且つそれがディレクトリの場合 |
| -e file | file が存在する場合(種類に関係なく) |
| -f file | file が存在し且つそれが通常のファイルの場合 |
| -L file | file が存在し且つそれがシンボリックリンクの場合 |
| -s file | file が存在し且つ file のサイズが0ではない(file が空ではない)場合 |
| -r file | file が存在し且つ読み取り可能な場合 |
| -w file | file が存在し且つ書き込み可能な場合。true は書き込みフラグがオンになっていることのみを示します。このテストで true の場合でも、読み取り専用ファイルシステムでは書き込み可能ではありません。 |
| -x file | file が存在し且つ実行可能な場合。file がディレクトリの場合、true はそのディレクトリを検索できることを示します。 |
| file1 -nt file2 | file1 の更新時刻が file2 のより新しい場合(newer than) |
| file1 -ot file2 | file1 の更新時刻が file2 のより古い場合(older than) |
| file1 -ef file2 | file1 と file2 の実体が同じ(シンボリックリンク先が同じまたはハードリンク先が同じ)場合 |
touch first.txt return #空のファイルを作成 touch second.txt return #空のファイルを作成 test -s first.txt; echo $? return #ファイルが空でないかを確認 1 #false ファイルは空 [ -w first.txt ]; echo $? return #ファイルが書き込み可能どうかを確認 0 #true 書き込み可能 test first.txt -nt second.txt; echo $? return #first.txt は second.txt より新しいか? 1 #false 新しくない test first.txt -ot second.txt; echo $? return #first.txt は second.txt より古いか? 0 #true 古い
文字列
以下は文字列を比較したり判定する際に使用できる演算子です。
※演算子と文字列の間にはスペースが必要です。
| 演算子 | 真になる条件 |
|---|---|
| 文字列 | 文字列が null でない(定義されている)場合 |
| -n 文字列 | 文字列の長さが 0 でない場合 |
| -z 文字列 | 文字列の長さが 0 の場合 |
| 文字列1 = 文字列2 | 文字列1と文字列2が等しい場合 |
| 文字列1 != 文字列2 | 文字列1と文字列2が等しくない場合 |
| 文字列 =~ パターン(※) | 文字列が指定したパターンにマッチする場合 |
| 文字列1 < 文字列2(※※) | ASCIIコード順に比較して文字列1が文字列2より前になる場合 |
| 文字列1 > 文字列2(※※) | ASCIIコード順に比較して文字列1が文字列2より後になる場合 |
以下は変数 $val1 に文字列「abc」を設定した場合の例です。変数 $val2 は定義されていません。
val1="abc" return #変数 val1 に文字 abc を代入 test $val1; echo $? return #文字列 $val1 を評価 0 #true test $val2; echo $? return #文字列 $val2(定義されていない)を評価 1 #false test -n $val1; echo $? return #文字列 $val1 の長さが 0 でないか? 0 #true(0でない) test -z $val1; echo $? return #文字列 $val1 の長さが 0 か? 1 #false(0でない) #変数が定義されていないと、-n や -z は正常に動作しないようです。 #以下は定義されていない変数 $val2 の例ですが、正しく判定されていません。 test -n $val2; echo $? return 0 #true(0でない) test -z $val2; echo $? return 0 #true(0である) $ val2="123" return #変数 val2 に文字 123 を代入 test $val1 = $val2; echo $? return #$val1 と $val2 が等しいか? 1 #false(等しくない) test $val1 != $val2; echo $? return #$val1 と $val2 が等しくないか? 0 #true(等しくない) test $val1=$val2; echo $? return #$val1 と $val2 が等しいか?(= の前後にスペースがない) 0 # 演算子 = の前後にスペースがないため正しく評価されない(23行目の結果と異なる)
(※)「=~」の演算子は [[ の書式(複合コマンド)でのみ使用可能です。
以下はパターンマッチを使って特定の文字列が含まれるかを判定する例です。
echo $SHELL return #変数の値を確認 /bin/bash [[ $SHELL =~ bash ]]; echo $? return #bash が含まれるか? 0 #true(含まれる) echo $LANG return #変数の値を確認 ja_JP.UTF-8 [[ $LANG =~ UTF ]]; echo $? return #UTF が含まれるか? 0 #true(含まれる) [[ $LANG =~ .*_JP.* ]]; echo $? return #_JP が含まれるか? 0 #true(含まれる) [[ $LANG =~ JA ]]; echo $? return #JA が含まれるか? 11 #false (含まれない) [ $LANG =~ JA ]; echo $? return #使用できない -bash: [: =~: binary operator expected #エラー 2 test $LANG =~ JA ; echo $? return #使用できない -bash: test: =~: binary operator expected #エラー 2
(※※)「<」と「>」の演算子は [[ の書式(複合コマンド)でのみ使用可能です。
char1="a" return #変数 char1 に文字 a を代入 char2="b" return #変数 char2 に文字 b を代入 [[ $char1 < $char2 ]]; echo $? return #a と b を比較 0 #true a は b よりも前 [[ $char2 < $char1 ]]; echo $? return #b と a を比較 1 #false b は a よりも前ではない [[ xyz > xzy ]]; echo $? return #xyz と xzy を比較 1 #false xyz は xzy よりも後ではない [[ xyz > xab ]]; echo $? return #xyz と xab を比較 0 #true xyz は xab よりも後 test $char1 < $char2; echo $? return #使用できない -bash: b: No such file or directory #エラー 1 [ $char1 < $char2 ]; echo $? return #使用できない -bash: b: No such file or directory #エラー 1
以下は数値(整数)を比較する際に使用できる演算子です。
| 演算子 | 真になる条件 |
|---|---|
| 数値1 -eq 数値2 | 数値1と数値2が等しい場合(equal) |
| 数値1 -ne 数値2 | 数値1と数値2が等しくない場合(not equal) |
| 数値1 -gt 数値2 | 数値1が数値2より大きい場合(greater than) |
| 数値1 -ge 数値2 | 数値1が数値2より大きいか等しい場合(greater than or equal) |
| 数値1 -lt 数値2 | 数値1が数値2より小さい場合(less than) |
| 数値1 -le 数値2 | 数値1が数値2より小さいか等しい場合(less than or equal) |
論理演算
| 演算子 | 真になる条件 |
|---|---|
| 条件式1 -a 条件式2 | 条件式1と条件式2がどちらも真の場合(and) |
| 条件式1 -o 条件式2 | 条件式1と条件式2のどちらかが真の場合(or) |
| ! 条件式 | 条件式が偽の場合(not) |
test 3 -eq 3 -a 5 -gt 3; echo $? return 0 #true 「3は3と等しい」且つ「5は3より大きい」→ 真 test 3 -eq 3 -a 5 -lt 3; echo $? return 1 #false 「3は3と等しい」且つ「5は3より小さい」→ 偽 test 3 -eq 3 -o 5 -lt 3; echo $? return 0 #true 「3は3と等しい」または「5は3より小さい」→ 真 test 3 -ne 3 -o 5 -lt 3; echo $? return 1 #false 「3は3と等しくない」または「5は3より小さい」→ 偽
-a の代わりに && を使って以下のように記述することもできます。
test 3 -eq 3 && test 5 -gt 3; echo $? return 0 #true 「3は3と等しい」且つ「5は3より大きい」→ 真 [ 3 -eq 3 ] && [ 5 -gt 3 ]; echo $? return 0 #true 「3は3と等しい」且つ「5は3より大きい」→ 真
-o の代わりに || を使って以下のように記述することもできます。
test 3 -ne 3 || test 5 -lt 3; echo $? return 1 #false 「3は3と等しくない」または「5は3より小さい」→ 偽 [ 3 -ne 3 ] || [ 5 -lt 3 ]; echo $? return 1 #false 「3は3と等しくない」または「5は3より小さい」→ 偽
以下は ! を使って条件判定を反転させる例です。
test ! 3 -eq 3; echo $? return 1 #false test ! "abc" = "abc"; echo $? return 1 #false [ ! "abc" = "abc" ]; echo $? 1 #false
キーボードからの入力を受け取る read
read コマンドはユーザからの入力(標準入力)を1行読み取り,変数に代入します。
read コマンドは以下のように内部コマンドと外部コマンドが用意されています。
type -a read return read is a shell builtin # 内部コマンド read is /usr/bin/read
内部コマンド read のマニュアルは help read で見ることができます。
help read return
read: read [-ers] [-u fd] [-t timeout] [-p prompt] [-a array] [-n nchars] [-d delim] [name ...]
One line is read from the standard input,
or from file descriptor FD if the -u option is supplied,
and the first word is assigned to the first NAME,
the second word to the second NAME, and so on,
with leftover words assigned to the last NAME.
Only the characters found in $IFS are recognized as word delimiters.
If no NAMEs are supplied, the line read is stored in the REPLY variable.
If the -r option is given, this signifies 'raw' input, and
backslash escaping is disabled.
The -d option causes read to continue
until the first character of DELIM is read, rather than newline.
If the -p option is supplied, the string PROMPT is output
without a trailing newline before attempting to read.
If -a is supplied, the words read are assigned to
sequential indices of ARRAY, starting at zero.
If -e is supplied and the shell is interactive,
readline is used to obtain the line.
If -n is supplied with a non-zero NCHARS argument,
read returns after NCHARS characters have been read.
The -s option causes input coming from a terminal to not be echoed.
The -t option causes read to time out and return failure if a complete line
of input is not read within TIMEOUT seconds. If the TMOUT variable is set,
its value is the default timeout. The return code is zero, unless end-of-file
is encountered, read times out, or an invalid file descriptor is supplied as
the argument to -u.
以下がおおまかな書式です。
read [オプション] [変数名 ...]
以下のようなオプションがあります。
| オプション | 意味 |
|---|---|
| -a array(配列名) | 読み込んだ単語(空白区切りの文字列)を配列に格納する |
| -d delim(区切り文字) | 読み込みを終了する区切り文字を指定(デフォルトは改行) |
| -n ncharsz(文字数) | 指定した文字数の入力を受け取ったら読み取りを終了 |
| -p prompt(プロンプト文字列) | 読み込み前にプロンプト文字列を表示する |
| -r | 読み込む文字のバックスラッシュによるエスケープを無効にする(バックスラッシュを単なる文字として扱う) |
| -t timeout(秒数) | 入力待ちの時間を秒で指定 |
| -u fd(ファイルディスクリプタ) | 標準入力ではなく指定したファイルディスクリプタから読み込む |
read コマンドはユーザからの入力を1行読み取り(指定した)変数に代入します。
以下はコマンドラインで実行する例で、変数名に input を指定しています。
2行目はキーボードからの入力です。
3行目は変数 $input に代入された値(キーボードから入力した値)を出力しています。
read input return #入力待ちの状態になる Here we go! return #キーボードから「Here we go!」と入力して return を押す echo $input return #変数 $input を出力 Here we go! #変数 $input の値が表示される
変数名を指定しない場合は、ユーザからの入力をデフォルトの変数 REPLY に格納します。
read return #入力待ちの状態になる OK return #キーボードから「OK」と入力して return を押す echo $REPLY return #変数 $REPLY を出力 OK
複数の文字列(単語)を受け取る
read コマンドで引数に複数の変数を指定した場合は、入力した行は区切り文字で区切った複数の文字列(単語)に区切られ、それぞれ変数に代入されます。
区切り文字の初期値は空白またはタブで、環境変数 IFS で設定(変更)できます。
以下は read コマンドの引数に3つの変数を指定して、入力されたスペース区切りの文字列を受け取り変数に代入する例です。
read str1 str2 str3 return #引数に3つの変数を指定 abc 123 #$% return #空白区切りで3つの文字列を入力 echo $str1 return #変数 $str1 に代入された値を出力 abc echo $str2 return #変数 $str2 に代入された値を出力 123 echo $str3 return #変数 $str3 に代入された値を出力 #$%
指定した変数の数より多い入力がある場合は、最後の変数にまとめて代入されます。
read str1 str2 str3 return #引数に3つの変数を指定 111 222 333 444 return #空白区切りで4つの文字列を入力 echo $str1 return 111 echo $str2 return 222 echo $str3 return #多い分は最後の変数に代入される 333 444
指定した変数の数より入力が少ない場合は、残りの変数は空白になります。
read str1 str2 str3 return #引数に3つの変数を指定 aaa return #1つの文字列のみを入力 echo $str1 return aaa echo $str2 return #入力が少ないので空白 echo $str3 return #入力が少ないので空白
区切り文字を設定 IFS
以下はデフォルトの区切り文字を : に変更する例です(少し面倒な方法です)。
まず、現在の環境変数 IFS の値をバックアップしてから変更し、後で元に戻します(シェルを再起動すれば元に戻ります)。
ORG_IFS=$IFS return #デフォルトの設定を変数 ORG_IFS にバックアップ IFS=: return #IFS の値(区切り文字)を : に変更 read s1 s2 s3 return #引数に3つの変数を指定 New York:Los Angels:Houston return # : 区切りで文字列を入力 echo $s1 return New York echo $s2 return Los Angels echo $s3 return Houston IFS=$ORG_IFS return #デフォルトの設定に戻す
以下は、前述の方法のより簡単です。
read コマンドの前に IFS=x と区切り文字(x)を指定して、IFS を一時的に変更して read コマンドを実行します。
注意しなければならないのは、IFS=x の後にはセミコロンを記述しないようにします。(セミコロンを付けて実行すると、IFS の値が変更されてしまいます)
以下は前述と同じことを、もう少し簡単に行う方法です。
IFS=: read s1 s2 s3 return #IFS の値を : に変更して read コマンドを実行 New York: Los Angels : Houston return # : 区切りで文字列を入力 echo $s1 return New York echo $s2 return Los Angels echo $s3 return Houston echo $IFS return #IFS の値は変更されていない
IFS
IFS(Internal Field Separator)は bash の環境変数(組み込み変数)でデフォルトは ' \t\n'(空白、タブ、改行)で、read コマンドの展開後の単語や行の区切りなどに使われています。以下は man bash からの抜粋です。
IFS The Internal Field Separator that is used for word splitting after expansion and to split lines into words with the read builtin command. The default value is ``<space><tab><new-line>''.
※ IFS の値は空白文字なので echo してもわからない(分かりづらい)です。
echo "環境変数IFS ここから→${IFS}←ここまで" return #デフォルトの IFS を出力
環境変数IFS ここから→
←ここまで
読み込みを終了する文字を変更 -d
読み込み(入力)を終了する区切り文字はデフォルトでは改行ですが、-d を指定して別の文字に変更することができます。
以下は、読み込み(入力)を終了する区切り文字を「%」に指定した例です。
以下の例では、わかりやすいようにターミナルのプロンプト「$」を表示しています。
入力を開始して、「%」を入力した時点で read コマンドの入力が終了し、「$」というターミナルのプロンプト文が表示されています。
$ read -d % str return #-d オプションで「%」を指定 abcde% $ return #「%」が入力された時点で入力が終了し、ターミナルのプロンプトが表示される $ echo $str return #変数 $str を出力 abcde
入力を配列に代入 -a
-a オプションを指定すると指定した変数を配列変数として扱い、入力した行を空白(区切り文字)で区切り配列変数(配列)に代入します。
区切られる文字列(単語)の数がわからない場合などで便利です。
配列変数のインデックスは0から順に代入されていきます。
read -a input_array return #-a オプションを指定して引数に(配列)変数を指定
Sun River Sea return #空白区切りで3つの文字列を入力
echo ${input_array[0]} return #1番目の要素を出力
Sun
echo ${input_array[1]} return #2番目の要素を出力
River
echo ${input_array[2]} return #3番目の要素を出力
Sea
echo ${input_array[@]} return #全ての要素をまとめて出力
Sun River Sea
echo ${#input_array[@]} return #要素数を出力
3
echo ${!input_array[@]} return #要素のインデックスを出力
0 1 2
入力文字数を制限 -n
-n オプションを使うと指定した文字数が入力された時点で読み込みが終了し次の処理に進みます。
以下は7文字入力したら、読み込みを終了する例です。
以下の例では、わかりやすいようにターミナルのプロンプト「$」を表示しています。
$ read -n 7 str return #-n オプションで「7」を指定 ABCDEFG $ return #7文字が入力された時点で入力が終了し、ターミナルのプロンプトが表示される $ echo $str return #変数 $str を出力 ABCDEFG
プロンプトを表示 -p
-p オプションを指定すると、入力行の先頭に表示するプロンプト(文字)を設定することができます。
入力してもらう内容などを表示でき、入力待ちの状態であることを示すことができます。
read -p "Enter 2 words: >" str1 str2 return #-p オプションを指定 Enter 2 words: >Star Dust return #プロンプトが入力行の先頭に表示される echo $str1 Star echo $str2 Dust
入力時間を制限 -t
-t オプションを指定すると、入力できる時間を制限することができます。時間は秒数で指定します。
何も入力せずに指定した時間(秒数)が経過すると、入力待ち状態が終了しプロンプトが戻ります。
以下は入力時間を5秒と設定する例です。
read -t 5 -p "timeout in 5sec:> " str return # -t 5(5秒と指定) timeout in 5sec:> $ #5秒間入力がないとプロンプトが表示される
read コマンド(IFS)参考サイト:read - 標準入力から行を読み取る
連番・数列を生成 seq
seq コマンドは連続した番号や一定間隔の数字の列(sequence of numbers)を出力するコマンドです。
以下が書式です。
seq [オプション] [開始値 [増分]] 終了値
「開始値」「増分」「終了値」には整数の他に小数や負の値(マイナス)を指定することができます。
以下のようなオプションがあります。
| オプション | 意味 |
|---|---|
| -f format(フォーマット文字列) | フォーマット文字列を使って数字の書式を設定 |
| -s string(文字列) | 数字の区切り文字列を指定(デフォルトは改行) |
| -t string(文字列) | 出力の最後に指定した文字を出力 |
| -w | 数字の幅を等しくするように先頭を0追加 |
seq 終了値
終了値のみ(必須の引数)を指定すると、1から指定した数値までの連続した数値を出力します。
seq 5 return #終了値のみを指定 1 2 3 4 5
seq 開始値 終了値
開始値と終了値を指定すると、開始値から終了値までの連続した数値を出力します。
seq 5 10 return #開始値と終了値を指定 5 6 7 8 9 10
seq 開始値 増分 終了値
増分は開始値と終了値の間に指定します。
seq 0 5 20 return #開始値 増分 終了値を指定 0 5 10 15 20 seq 5 0.5 8.5 return # 0.5 間隔で増加 5 5.5 6 6.5 7 7.5 8 8.5
減少(逆順で出力)
終了値を開始値より小さい値に指定すると減少させて連番を出力することができます。
seq 10 5 return #10〜5まで連番で(減少) 10 9 8 7 6 5 seq 10 -1 5 return #前述と同じこと 10 9 8 7 6 5 seq 10 -2 5 return #2ずつ減少させる 10 8 6 seq 0.5 -0.25 -2 return #0.25ずつ減少させる 0.5 0.25 0 -0.25 -0.5 -0.75 -1 -1.25 -1.5 -1.75 -2
先頭を0で埋める -w
-w オプションを指定すると、先頭(や末尾)を0で埋めて数字の幅を等しくすることができます。
seq -w 5 10 return #-w オプションを指定して先頭を0で埋める 05 06 07 08 09 10 seq -w 0 50 1000 return # 50間隔で1000まで 0000 0050 0100 0150 0200 ・・・ 0850 0900 0950 1000 seq -w 0.5 -0.25 -2 return #0.25ずつ減少(先頭と末尾を0で埋める) 00.50 00.25 00.00 -0.25 -0.50 -0.75 -1.00 -1.25 -1.50 -1.75 -2.00
区切り文字を変更 -s
デフォルトの区切り文字は改行(\n)ですが、-s オプションを指定すると変更することができます。
seq -s , 5 return # 区切り文字をカンマに変更 1,2,3,4,5, #改行されないのでプロンプトがこの位置にきます seq -s ", " 5 return # 区切り文字を「カンマ+スペース」に変更 1, 2, 3, 4, 5, #改行されないのでプロンプトがこの位置にきます $ seq -s ",\n" 5 return # 区切り文字を「カンマ+改行」に変更 1, 2, 3, 4, 5, seq -w -s ".txt\n" 10 return # 区切り文字を「.txt+改行」に変更 01.txt 02.txt 03.txt 04.txt 05.txt 06.txt 07.txt 08.txt 09.txt 10.txt # このような場合は -f オプション使う方が自由度が高いです。
最後に指定した文字を出力 -t
-w オプションを指定すると、出力の最後に指定した文字を出力することができます。
-s オプションで改行を使わない場合に、最後に改行文字を出力する際に便利です。
seq -s , -t "\n" 5 return #区切り文字をカンマに変更し最後に改行を出力 1,2,3,4,5, seq -t "End\n" 5 return #最後に「End+改行」を出力 1 2 3 4 5 End
書式を指定 -f
-f オプションを指定してフォーマット文字列を使って数字の書式を指定することができます。
以下のフォーマット指定子を使用できます。
| フォーマット指定子 | 意味 |
|---|---|
| %f | 通常表記の浮動小数点数 |
| %e | 指数表記の浮動小数点数(小文字) |
| %E | 指数表記の浮動小数点数(大文字) |
| %g | 数値の値(大きさ)に応じた浮動小数点数(小文字) |
| %G | 数値の値(大きさ)に応じた浮動小数点数(大文字) |
例えば、小数点以下2桁で出力するには "%0.2f" と指定します。
また、フォーマット指定子の前後に任意の文字列を指定することもできます。引用符は省略可能です。
seq -f "%0.2f" 0.5 0.1 1 return #小数点以下2桁で出力 0.50 0.60 0.70 0.80 0.90 1.00 seq -f "%0.3fppm" 0.05 0.01 0.1 return #文字列を付加して出力 0.050ppm 0.060ppm 0.070ppm 0.080ppm 0.090ppm 0.100ppm seq -f "%e" 1000 100 2000 return #指数表記(小文字) 1.000000e+03 1.100000e+03 1.200000e+03 1.300000e+03 ・・・ 1.800000e+03 1.900000e+03 2.000000e+03 seq -f "%0.1E" 1000 100 2000 return #指数表記(大文字桁数指定) 1.0E+03 1.1E+03 1.2E+03 1.3E+03 ・・・ 1.8E+03 1.9E+03 2.0E+03
整数で出力する際に桁数を指定するには %g を使って、例えば3桁であれば %3g、先頭を0で埋める場合は %03g のように指定します。
seq -f "%3g" 1 5 return #3桁で整数を出力 1 2 3 4 5 test $ seq -f "%03g" 1 5 return #先頭を0で埋めて3桁で出力 001 002 003 004 005 test $ seq -f "sample_%03g.txt" 1 5 return #先頭を0で埋めて3桁で前後に文字列を付けて出力 sample_001.txt sample_002.txt sample_003.txt sample_004.txt sample_005.txt
四則演算(算術)
シェルで四則演算を行うにはいくつかの方法があります。
例えば、1+2 という足し算を以下のように記述しても計算することはできません。
foo=1+2 return #変数 foo に 1+2 の結果を代入したつもり echo $foo return #変数 foo を出力 1+2 #文字列として出力される
シェルで足し算をするには、以下のような方法があります。
let foo=1+2 return # let コマンド echo $foo return 3 ((foo=1+2)) return # let コマンドの別の書き方 echo $foo return 3 echo $((1+2)) return # 算術式展開 3 foo=$((1+2)) return # 算術式展開(変数に代入) echo $foo 3 expr 1 + 2 return # expr コマンド(結果の出力先は標準出力) 3 foo=$(expr 1 + 2) return # expr コマンドの結果をコマンド置換で変数に代入 echo $foo return 3 # let コマンドや算術式展開では式に空白を含めないが、expr コマンドでは演算子の前後に空白が必要
let コマンドは、四則演算や論理演算などの算術式を評価(計算)するシェルの内部コマンドです。
let コマンドの代わりに,((算術式)) と記述することで let コマンドと同様に算術式を評価できます。
式の結果をすぐに表示(展開)するには、echo $((算術式)) のように記述でき、算術式展開(arithmetic expansion)と呼びます。
シェルスクリプトの中では、算術式を評価(計算)するには ((算術式)) と記述し、評価した値を取り出すには $ を付けて $((算術式)) とするのが一般的です。
let 変数=算術式 # let コマンド ((変数=算術式)) # let コマンドの別の書き方 echo $((算術式)) # 算術式展開(結果を展開) 変数=$((算術式)) # 算術式展開(結果を展開)
expr コマンドは、式を評価して標準出力に結果を書き込む外部コマンドで、整数の四則演算や正規表現を使ったパターン判定が可能です。
expr 式 # 結果は出力される→結果の出力先は標準出力 変数=`expr 式` # 結果をコマンド置換で変数に代入 または 変数=$(expr 式)
処理速度
数式の算出をするだけであれば、let コマンドの方が expr コマンドよりはるかに速いので、ループ内の繰り返しなどでは let コマンドを使ったほうが良いようです。
let コマンド (( ))
let コマンドは、四則演算や論理演算を含む算術式による計算を行って評価する bash の内部(組み込み)コマンドです。
- 四則演算では整数だけを扱えます(小数の計算は bc コマンドを使います)
- 算術式の中ではパス名展開をしないので * をエスケープする必要はありません
- 算術式の中で変数を使う場合、$ は不要です
- 算術式の中では空白を含めることができません
- 変数が null や未設定の場合は値は0として扱われます
- 演算を括弧でまとめると演算の優先順位を変更できます
- ((算術式)) と記述することができます
以下が書式です。
let 変数=算術式
以下のように記述することができます。
((変数=算術式))
算術式の結果を展開するには $ を付けて以下のように記述し、算術式展開と呼ばれます。
$((算術式))
算術式展開は、bash が算術式を解釈及び計算して計算結果に置き換えます。
以下は四則演算の使用例です。
let foo=1+2 return # let 変数=算術式 echo $foo return 3 ((bar=3*4)) return # ((変数=算術式)) echo $bar return 12 ((foo2=(foo+bar)*6)) return # ((変数=算術式)) 括弧でまとめて優先順位を変更 echo $foo2 return 90 echo $((3>1)) return # echo $((算術式)) 算術式展開 1 # 1は true echo 5-3=$((5-3)) return # $((算術式)) 算術式展開 5-3=2 x=$((12/3)) return # 変数= $((算術式)) 算術式展開 echo $((x*3)) return # echo $((算術式)) 算術式展開 12 #算術式の中では空白を含めることができない #算術式の中で変数を使う場合 $ は不要 #算術式の中では * のエスケープは不要
以下のような演算子が使えます。
| 演算子 | 意味 |
|---|---|
| + | 加算 |
| - | 減算 |
| * | 乗算 |
| / | 除算 |
| % | 剰余(余り) |
| ** | 累乗 |
| 変数++ | 変数を評価した後で1増やす(後置インクリメント) |
| 変数-- | 変数を評価した後で1減らす(後置デクリメント) |
| ++変数 | 変数を1増やしてから評価する(前置インクリメント) |
| --変数 | 変数を1減らしてから評価する(前置デクリメント) |
| <=、 >=、 <、 > | 大小の比較(true は 1、false は 0) |
| == | 等しい(true は 1、false は 0) |
| != | 等しくない(true は 1、false は 0) |
| = | 代入演算子 |
| +=、-=、*=、/=、%= など | 複合代入演算子 |
| ! | 論理否定 |
| && | 論理AND |
| || | 論理OR |
| 式1 ? 式2 : 式3 | 三項演算(式1が true ならば式2、式1が false なら式3を評価) |
以下は演算子の使用例です。
((x=3<5)) return # 変数 x に 3 と 5 の大小を比較した結果を代入 echo $x return # 変数 x を出力 1 # 3 は 5 より小さいので true(1) echo $((8!=8)) return # 8と8が「等しくない」かを判定して結果を出力(算術式展開) 0 # 8 と 8 は等しいので false(0) y=123 return # 変数 y に 123 を代入 ((y+=10)) return # 変数 y の値を 10 増加 echo $y return # 変数 y を出力 133 # 123+10 echo $((y*=5)) return # 変数yの値(133)に 5 をかけた結果を出力(算術式展開) 665 # 133x5 w=0 return # 変数wに0を代入 ((z=w?w:y)) return # w の値が true なら w を、そうでなければ y の値を z に代入(三項演算) echo $z return # 変数zを出力 665 # w は 0 なので false になり、y の値(665)が代入される w=1 return # 変数 w に 1 を代入 echo $((z=w?w:y)) return # (三項演算と算術式展開) # w の値が true なら w を、そうでなければ y の値を z に代入した結果を出力 1 # w に 1 が代入されて true になり、w の値(1)が代入される
以下はインクリメント演算子の使用例です。演算子の位置により動作が異なります。
foo=0 return # foo に0を代入 ((foo++)) return #後置インクリメントで値を1増やす echo $foo return #foo は1に 1 echo $((foo++)) return #評価した時点では1で、その後1増加される 1 echo $foo return #foo は2になっている 2 echo $((++foo)) return #評価する前に1増やしている 3 echo $foo return #評価前に1増えているのでそのまま 3
以下は注意が必要なインクリメント演算子を使った例です。
以下のような誤った書き方をすると、変数 foo の値は 0 のままです。
foo=0 return # foo に 0 を代入 foo=$((foo++)) return # 評価した時点で foo は0なので foo には 0 が代入される echo $foo 0 foo=$((foo++)) return # foo は 0 のまま echo $foo 0
もし上記のような書き方をする場合は、前置インクリメントを使います。
foo=0 return # foo に 0 を代入 foo=$((++foo)) return # 評価した時点で foo は 1 なので foo には 1 が代入される echo $foo 1 foo=$((++foo)) return # 評価した時点で foo は 2 なので foo には 2 が代入される echo $foo 2 foo=$((foo+1)) return # インクリメント演算子を使わない場合 echo $foo 3
n 進数リテラル
8進数や16進数など n 進数を記述することができます。
| 進数 | 表記 |
|---|---|
| 10進数 | 1〜9 の数字で始まる数値 |
| 8進数 | 0 から始まる整数 |
| 16進数 | 0x または 0X で始まる整数 |
| n 進数 | n# で始まる整数(n は 2 以上 64 以下) |
echo $((07654)) return # 8 進表記 4012 echo $((0xC14F)) return # 16 進表記 49487 echo $((2#11111110)) return # 2 進表記 254 ((foo=2#11111100+2#00000011)) return # 2 進表記 echo $foo return 255 echo $((2#11111100+2#00000011)) return # 2 進表記 255
expr コマンド
expr コマンドは、式を評価して結果を標準出力に表示(出力)します。
四則演算や比較演算子を使った判定などが可能です。
以下が書式です。
expr 式
式の要素はすべて別々の引数として指定する必要があるので、演算子の前後には空白が必要です。
また、* や (、) 、<、> のようなシェルで特別な意味を持つ記号(メタ文字)を使う場合は、バックスペースでエスケープするか引用符で括る必要があります。
四則演算
整数の四則演算が可能です。(小数の計算は bc コマンドを使います)
| 式 | 出力 |
|---|---|
| 引数1 + 引数2 | 引数1と引数2を足した結果(加算) |
| 引数1 - 引数2 | 引数1から引数2を引いた結果(減算) |
| 引数1 * 引数2 | 数1と引数2を掛けた結果(乗算) |
| 引数1 / 引数2 | 引数1を引数2で割った結果の整数部分(除算) |
| 引数1 % 引数2 | 引数1を引数2で割った余り(剰余算) |
以下は四則演算の例です。括弧を使って優先度を変更することもできます。
expr 1 + 2 return 3 expr 3 - 2 return 1 expr 3 \* 4 return # * をバックスラッシュでエスケープ 12 expr 3 "*" 4 return # * を引用符でエスケープ 12 expr 7 / 2 return 3 expr 7 % 2 return 1 expr 3 + 2 \* 4 return 11 expr \( 3 + 2 \) \* 4 return # 括弧を使って優先度を変更(括弧はエスケープします) 20
計算結果を変数に入れるにはコマンド置換 `` または $() を使います。
x=`expr 3 + 7` return # コマンド置換 `` echo $x return 10 y=$(expr $x - 8) return # コマンド置換 $() echo $y return 2
値の比較(判定)
両方の引数が整数の場合は,整数を比較した結果を返します。
それ以外の場合は,辞書並び順で文字列を比較した結果を返します。
結果は true の場合は 1,false の場合は 0 になります。
| 式 | true(1)になる条件 |
|---|---|
| = | 左辺の値と右辺の値が等しい |
| != | 左辺の値と右辺の値が等しくない |
| > | 左辺の値が大きい |
| >= | 左辺の値が大きいか右辺の値と等しい |
| < | 左辺の値が小さい |
| <= | 左辺の値が小さいか右辺の値と等しい |
expr 3 != 5 return 1 # 等しくないので true expr 8 \< 7 return # < はエスケープ 0 # 8 は 7 より小さくないので false x=10 y=20 return # 変数を設定 expr $x \>= $y return # > はエスケープ 0 # $x は $y より大きくないので false expr 123 \< abc return #文字列として辞書順で比較 1 # 123 の方が辞書順で前なので true expr abc \> xyz return #文字列として辞書順で比較 0 # abc の方が辞書順で前なので false
小数の計算 bc コマンド
bc コマンドは四則演算や複雑な計算をすることができ、必要に応じて小数点以下の桁数を指定することができます。
以下が書式です。
bc [オプション] [ファイル]
標準入力やファイルから計算式を入力して(読み込んで)実行することもできます。
以下はパイプを使ってコマンドラインから計算式を入力する書式です。
echo 計算式 | bc
以下のようなオプションがあります。
| オプション | 意味 |
|---|---|
| -h | ヘルプを表示 |
| -i | 対話モードを強制 |
| -l | 標準数学ライブラリを読み込んで起動 |
| -q | 起動時のメッセージを表示しない |
| -v | バージョンを表示 |
bc を起動するとバージョンや著作権情報などの後に、カーソルが表示されます。
カーソルの位置に計算を入力し、return を押すと結果が表示されます。
終了するには quit とタイプして return を押します。
左右の矢印キーで移動でき delete キーで文字を削除できます。
上下の矢印キーで実行した計算式を呼び出すことができます。
小数点以下を表示するには、特別な変数 scale に scale=桁数 のように指定します(初期値は0)。
bc return #bc を起動
bc 1.06
Copyright 1991-1994, 1997, 1998, 2000 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'`.
432*3.14 return #乗算 432 x 3.14
1356.48
100/7 return #除算(小数の桁数を指定していないので小数点以下が表示されない)
14
scale=8 return #小数点以下の桁を変数 scale に指定(初期値は0)
100/7 return #同じ除算を再度実行(↑キーが使える)
14.28571428
(4+3)*3/7 return #括弧で優先度を変更可能
3
pi=3.14 return #変数に代入
r=4 return #変数に代入
r^2*pi return #円周を計算(^ はべき乗)
50.24
sqrt(2) return #2の平方根
1.41421356
length(12345.6789) return #指定した数値の有効桁数
9
scale(12345.6789) return #指定した数値の小数点以下の有効桁数
4
quit return #終了するには quit とタイプ
特別な変数
以下の変数を設定することで、小数点以下の有効桁数や入出力の基数を指定することができます。
| 変数 | 意味 | 例 |
|---|---|---|
| scale | 小数点以下の有効桁数(初期値は0) | scale=5 (小数点以下5桁を表示する) |
| obase | 出力の基数(初期値は10) | obase=16(入力する値を16進数に) |
| ibase | 入力の基数(初期値は10) | ibase=2(入力する値を2進数に) |
ibase を指定すると、入力する際は(ibase の指定も)その基数で入力する必要があります。
以下は入出力の基数を指定する例です。
bc return #bc を起動 obase=2 return #出力の基数を2進数に 255 return #10進数の255を2進数に変換 11111111 10 return #10進数の10を2進数に変換 1010 obase=16 return #出力の基数を16進数に 255 return #10進数の255を16進数に変換 FF 10 return #10進数の10を16進数に変換 A obase=10 return #出力の基数を10進数に ibase=2 return #入力の基数を2進数に 111 return #2進数の111を10進数に変換 7 101110+101 return #2進数の計算結果を10進数に変換 51 ibase=1010 return #入力の基数を10進数に 3+2 return #10進数での計算 5 quit return #終了
コマンドラインから入力
以下は、コマンドラインから計算式を入力する書式です。
echo "計算式" | bc
小数点以下の桁数(scale)や基数(ibase obase)は必要に応じて毎回指定します。
複数の式を指定する場合は、セミコロン(;)で区切ります。
echo "3+4" | bc return #3+4 を計算 7 echo "scale=7;7/11"|bc return #小数点以下の桁数を7桁にして 7/11 を計算 .6363636 echo "sqrt(5)"|bc return #5の平方根(小数点以下の桁数を指定していない) 2 echo "scale=5;sqrt(5)"|bc return #小数点以下の桁数を5桁にして5の平方根 2.23606 echo "obase=16;254"|bc return #10進数の254を16進数に変換 FE echo "ibase=2;1011001"|bc return #2進数を10進数に変換 89 echo "x=10;y=2;(x+y)*3"|bc return #変数と括弧を使った計算 36
スクリプトでの使用例
以下は、キーボードから2つの値を受け取って、割り算をして出力するスクリプトの例です。
キーボードからの入力は read コマンドで受け取り、変数 $x、$y に代入しています。
小数点以下5桁まで表示するように scale=5 を指定し、bc コマンドの実行結果はコマンド置換 ` ` を使って変数 $ans に代入しています。
#! /bin/bash read -p "Enter 2 numbers for division :> " x y ans=`echo "scale=5; $x/$y" |bc` echo $x / $y = $ans
以下は実行例です。
./bcTest return Enter 2 numbers for division :> 33 77 return #33 と 77 を入力 33 / 77 = .42857
制御構造
条件によって処理内容を変えたり、繰り返しなどの処理の記述を「制御構造」や「制御構文」と呼びます。
制御構造には、if 文や case 文、for 文、while 文などがあります。
if 文
if 文を使うと条件によって処理を切り分ける(分岐する)ことができます。
条件は「条件式」で表し、条件の判定には、test コマンドを使うことが多いです。
以下が基本的な書式です。if で始まり、if を逆さまにした fi で終わります。
# 条件が成立した場合にだけ実行する場合if条件式then条件が成立する場合の処理fi
# 条件が成立した場合と成立しなかった場合で処理を変える場合if条件式then条件が成立する場合の処理else条件が成立しない場合の処理fi
# 複数の条件で処理を帰る場合if条件式1then条件式1が成立する場合の処理elif条件式2then条件式2が成立する場合の処理else全ての条件が成立しない場合の処理fi
if 文の改行
if 文では、if や then、else などのブロックの後は改行する必要があります。
改行しないで記述するにはセミコロン(;)を使用します。
また、空白を入れて読みやすいようにインデントすることができます。
前述の書式の例は以下のように書き換えることができます。
# 条件が成立した場合にだけ実行する場合if条件式 ;then条件が成立する場合の処理fi# 以下のように記述することもできます。if条件式 ;then条件が成立する場合の処理;fi
# 条件が成立した場合と成立しなかった場合で処理を変える場合if条件式 ;then条件が成立する場合の処理else条件が成立しない場合の処理fi
# 複数の条件で処理を帰る場合if条件式1 ;then条件式1が成立する場合の処理elif条件式2 ;then条件式2が成立する場合の処理else全ての条件が成立しない場合の処理fi
コマンドラインで使用
if 文は主にシェルスクリプトで使用されますが、if などもコマンドなのでコマンドラインでも使用することができます。
コマンドを複数実行するにはセミコロンで区切って記述します。
# コマンドラインで1行に記述する場合の書式の例(処理の部分にコマンドを記述)if条件式 ;then条件が成立する場合の処理;fiif条件式 ;then条件が成立する場合の処理;else条件が成立しない場合の処理;fi
コマンドラインで改行して入力することもできます。
その場合は、上記書式のセミコロン(;)の位置(スクリプトで改行している位置)で return を押して改行します(セミコロンは入力しません→セミコロンは改行の代わり)。
改行すると、2行目以降に > というプロンプトが表示されるので、その後に続きを入力し、fi の行の入力後、return を押すと処理が実行ます。
以下は if 文を使って「引数の数が 0の場合」は「引数がありません」、そうでなければ指定した引数の数を表示するスクリプト argsCount の例です。
引数の数は変数 $# に格納されています。
#! /bin/bash
if [ $\# = 0 ]; then
echo "引数がありません"
else
echo "引数の数は${#}個です"
fi
以下はスクリプト argsCount に実行権を付与して、実行する例です。
chmod +x argsCount return #実行権を付与 ./argsCount return #引数無しで実行 引数がありません ./argsCount foo return #引数1つで実行 引数の数は1個です ./argsCount foo bar return #引数2つで実行 引数の数は2個です
条件式
if 文は条件式に指定されたコマンドの終了ステータスを判定し、終了ステータスが 0 の場合は true(真)、0 以外の場合は false(偽)となり、一般的に条件式には test コマンドが使われます。
但し、test コマンドを使わなくても、条件式の部分が true(真)になれば(条件式に指定したコマンドが正常終了し終了ステータスが 0 になれば)then のブロックが実行されます。
以下は条件式に ls コマンドを使って引数で指定されたファイルやディレクトリを表示し、ls コマンドが成功(終了ステータスが 0)すれば「コマンド成功」と、失敗すれば「コマンド失敗」と表示するスクリプト(exprTest1)です。
8行目は、条件式と同じコマンドを実行して結果は全て /dev/null にリダイレクトして(出力は必要ないので)、9行目で ls -l コマンドの終了ステータスを出力しています。
#! /bin/bash if ls -l "$1"; then echo "コマンド成功" else echo "コマンド失敗" fi ls -l "$1" >/dev/null 2>&1 echo "終了ステータス: $?"
以下は実行例です。
bash exprTest1 sample.txt return #存在するファイルを指定して実行 -rw-r--r--@ 1 foo staff 519 9 9 08:47 sample.txt コマンド成功 終了ステータス: 0 bash exprTest1 testX return #存在しないファイルを指定して実行 ls: testX: No such file or directory コマンド失敗 終了ステータス: 1
以下は前述のスクリプト exprTest1 の if 文の部分とほぼ同様のことをコマンドラインで実行する例です。
var="sample.txt" return #変数に存在するファイルを格納 if ls -l $var; then echo "コマンド成功"; else echo "コマンド失敗" ; fi return #以下は上記 if 文を実行した結果の出力 -rw-r--r--@ 1 foo staff 519 9 9 08:47 sample.txt コマンド成功 #以下はコマンドラインで改行して実行する例です。 if ls -l $var return #改行(2行目からプロンプト > が表示される) > then echo "コマンド成功" return #改行 > else echo "コマンド失敗" return #改行 > fi return #実行
test コマンドの演算子
条件式に test コマンドの演算子を使えば、様々な条件を設定することができます。
以下は引数に指定されたファイルが存在しなければ「指定したファイルが存在しません」と表示し、存在すれば、その内容を cat コマンドで表示するスクリプト ifTest1 です。
ファイルが存在するかどうかは、ファイルが存在する場合に真(0)を返す -f 演算子と条件を反転させる ! 演算子と使って、「ファイルが存在しない場合」という条件を設定しています。
また、変数($1 と $file)はダブルクォートで囲んでいます(変数と引用符)。
#! /bin/bash
file="$1" #引数を変数に代入
if [ ! -f "$file" ] ; then #引数に指定したファイルが存在しない場合
echo "指定したファイルが存在しません"
else
echo "ファイル「${1}」が見つかりました。以下が内容です"
cat "$file"
fi
以下は実行例です。
bash ifTest1 myscript return #存在するファイルを指定して実行 ファイル「myscript」が見つかりました。以下が内容です #!/bin/bash myvar="my variable" echo "myvar: $myvar" echo "PATH: $PATH" echo "LANG: $LANG" bash ifTest1 myscriptX return #存在しないファイルを指定して実行 指定したファイルが存在しません
以下は指定された引数が2つの場合は、引数に指定された文字列を比較して値が同じ場合は「2つの引数は等しいです」、異なる場合は「2つの引数は等しくありません」と表示するスクリプト ifTest2 です。
もし指定された引数の数が2でない場合は「引数は2つ指定してください」と表示します。
以下の例の場合、「引数が2つの場合」に更に条件を分岐するので、if 文の中に if 文を記述(ネスト)しています。
#! /bin/bash
if [ $\# = 2 ]; then
if [ $1 = $2 ]; then
echo "2つの引数は等しいです"
else
echo "2つの引数は等しくありません"
fi
else
echo "引数は2つ指定してください"
fi
以下はスクリプト ifTest2 の実行例です。
bash ifTest2 abc efg return 2つの引数は等しくありません bash ifTest2 abc abc return 2つの引数は等しいです bash ifTest2 abc return 引数は2つ指定してください bash ifTest2 abc 123 xyz return 引数は2つ指定してください
変数と引用符
シェルスクリプトやコマンドラインでは、文字列を引用符で囲むことは必須ではありません。
また、変数を参照する際にもダブルクォート("")で囲むことは必須ではありません。
一般的には、変数が空であったり任意の空白(スペース等)や特殊文字(ワイルドカード)を含む(可能性がある)場合はダブルクォートで囲みます。
変数がダブルクォートで囲まれていないと、エラーになって実行できなくなる場合もあるので、原則として変数はダブルクォートで囲んでおくと安全です。
関連項目:シェルの展開順序
以下は変数($1 と $file)をダブルクォートで囲んでいないスクリプトの例です。
#! /bin/bash
file=$1
if [ ! -f $file ] ; then
echo "指定したファイルが存在しません"
else
echo "ファイル「${1}」が見つかりました。以下が内容です"
cat $file
fi
このスクリプトを引数なしで実行すると、以下のように表示され入力待ちの状態になってしまいます。
引数の指定がないので、[ ! -f ] の部分は偽(1)となり、else ブロックに移り、cat コマンドが引数なしで実行されて入力待ちになっている状態です。この場合、control + d で終了しなければなりません。
bash ifTest1_ng return #引数を指定せずに実行 ファイル「」が見つかりました。以下が内容です
また、引数に空白を含む文字列を指定してもエラーになってしまい、期待した結果にはなりません。
bash ifTest1_ng "sample test.txt" return #引数に空白を含む文字を指定して実行 ifTest1_ng: line 3: [: sample: binary operator expected #エラー ファイル「sample test.txt」が見つかりました。以下が内容です cat: sample: No such file or directory
スクリプトの中の変数をダブルクォートで囲んでおくと、上記のようなエラーを防ぐことができます。
以下は変数($1 と $file)をダブルクォートで囲んであるスクリプトです。
#! /bin/bash
file="$1" #変数ダブルクォートで囲む
if [ ! -f "$file" ] ; then #変数ダブルクォートで囲む
echo "指定したファイルが存在しません"
else
echo "ファイル「${1}」が見つかりました。以下が内容です"
cat "$file" #変数ダブルクォートで囲む
fi
変数をダブルクォートで囲んでおくと、前述の例と同じ引数で実行してもエラーにはなりません。
bash ifTest1 return #引数を指定せずに実行 指定したファイルが存在しません bash ifTest1 "sample test.txt" return #引数に空白を含む文字を指定して実行 指定したファイルが存在しません
エラー test: ==: unary operator expected
以下は [ ] コマンドで変数の値を比較する際に、変数の値が未定義であったり、空の場合にエラーになる例です。
foo="foo" return #変数 foo に値を代入(設定) [ $foo != $bar ]; echo $? return #変数 foo と未定義の bar を [ ] コマンドで比較判定 -bash: [: foo: unary operator expected #変数 bar が未定義なのでエラー 2 [ $foo != "$bar" ]; echo $? return #変数 bar をダブルクォートで括るとエラーにならない 0 bar="" return #変数 bar に空文字を代入 [ $foo != $bar ]; echo $? return #変数 bar をダブルクォートなしで比較判定 -bash: [: foo: unary operator expected #変数 bar が空文字の場合もエラー 2 [ $foo != "$bar" ]; echo $? return #再度変数 bar をダブルクォートで括るとエラーにならない 0 foo="" return #変数 foo に空文字を代入 [ $foo != "$bar" ]; echo $? return #変数 foo をダブルクォートなしで比較判定 -bash: [: !=: unary operator expected #変数 foo が空文字の場合なのでエラー 2 [ "$foo" != "$bar" ]; echo $? return #両方ともダブルクォートで括るとエラーにならないで済む 1
case 文
case 文は、文字列のパターンで処理を分岐させる制御構造です。
指定した値とパターン(または文字列)を照合してそれらがマッチした場合に処理を実行します。
以下が基本的な書式です。case で始まり、case を逆さまにした esac で終わります。
パターンは必要なだけ指定することができ、パターンと処理は「)」で区切り、それぞれの処理の最後に「;;」を記述します(最後の「;;」は省略可能)。
case値inパターン1) 値がパターン1にマッチした場合の処理 ;; パターン2) 値がパターン2にマッチした場合の処理 ;; ・・・ パターンn) 値がパターンnにマッチした場合の処理 ;;esac
また、処理で複数のコマンドを実行する場合は、改行または「;」で区切ります。
case値inパターン1) 値がパターン1にマッチした場合のコマンド1 値がパターン1にマッチした場合のコマンド2 値がパターン1にマッチした場合のコマンド3 ;; パターン2) 値がパターン2にマッチした場合のコマンド1 値がパターン2にマッチした場合のコマンド2 値がパターン2にマッチした場合のコマンド3 ;; ・・・esac
case 文は上から順に値とパターンの照合を行ってパターンとマッチした場合にそのパターンと共に指定されている処理を実行します。
最初にマッチしたパターンで指定されている処理を実行したら終了します。
もし、いずれのパターンにもマッチしない場合は、何も実行されません。
どの文字にもマッチするワイルドカード「*」を使ったパターンを最後に指定して、いずれのパターンにもマッチしなかった場合のための処理を指定することもできます。
# どのパターンにもマッチしなかった場合の処理を指定する場合case値inパターン1) 値がパターン1にマッチした場合の処理 ;; パターン2) 値がパターン2にマッチした場合の処理;; ・・・ パターンn) 値がパターンnにマッチした場合の処理 ;; *) 値がどのパターンにもマッチしなかった場合の処理 ;;esac
以下は、case の値に $1(一番目の引数)を指定して、スクリプトの引数に「y」を指定したら「Yes」、「n」を指定したら「No」、それ以外を指定したら「Something else」と表示するスクリプトです。
#! /bin/bash case "$1" in "y") echo "Yes";; "n") echo "No" ;; *) echo "Something else" ;; esac
上記のスクリプトの場合、パターン部分に指定した文字列 "y" と "n" の引用符は省略することができます。
ワイルドカードの * は引用符で囲むと文字としての "*" にしかマッチしないので引用符で囲みません。
以下は実行例です。
chmod +x caseTest1 return #スクリプトに実行権を付与
$ ./caseTest1 y return #引数に y を指定して実行
Yes
$ ./caseTest1 n return #引数に n を指定して実行
No
$ ./caseTest1 s return #引数に s を指定して実行
Something \else
パターンの指定
パターンの指定にはワイルドカードや OR 条件(|)を使用することができます。
以下は前述のスクリプトをワイルドカードの [ ] を使って、y と n の大文字・小文字のどちらでも指定された場合にマッチするように変更した例です。
#! /bin/bash case "$1" in [yY]) echo "Yes";; #ワイルドカードを使って y と Y どちらでもマッチ [nN]) echo "No" ;; #ワイルドカードを使って n と N どちらでもマッチ *) echo "Something else" ;; esac
以下は「または」を意味する OR 条件の | を使って、前述の例と同様、y と n の大文字・小文字のどちらでも指定された場合にマッチするようにした例です。
#! /bin/bash case "$1" in "y"|"Y") echo "Yes";; "n"|"N") echo "No" ;; *) echo "Something else" ;; esac
以下はワイルドカードの [ ] と OR 条件の | を組み合わせて、パターンを y や Y または yes Yes YEs YES yEs yES のような文字列にマッチするように変更した例です。
[yY][eE][sS] は以下のような意味になります。
- 1文字目: y または Y
- 2文字目: e または E
- 3文字目: s または S
#! /bin/bash case "$1" in [yY]|[yY][eE][sS]) echo "Yes";; [nN]|[nN][oO]) echo "No" ;; *) echo "Something else" ;; esac
以下は実行例です。
./caseTest4 Y return Yes ./caseTest4 yeS return Yes ./caseTest4 YES return Yes ./caseTest4 nO return No ./caseTest4 NO return No
条件の値を予め大文字または小文字に変換
前述のように大文字や小文字の組み合わせのパターンを増やすのではなく、条件の値を予め大文字または小文字に変換した上で比較する方法があります。
その1つは tr コマンドを使って case に指定した値を大文字または小文字に変換する方法です。
tr a-z A-Z を実行すると小文字を大文字に変換し、tr A-Z a-z を実行すると大文字を小文字に変換します。
tr コマンドは標準入力が使われるので、この例の場合は echo コマンドの出力をパイプ | で tr コマンドに読み込ませます。
また、変換した文字列を case 文の値に指定するには、コマンド置換 ` ` を使ってコマンドをコマンドの出力で置き換えます。
#! /bin/bash case `echo "$1" | tr A-Z a-z` in ##引数 $1 を小文字に変換 "y"|"yes") echo "Yes";; "n"|"no") echo "No" ;; *) echo "Something else" ;; esac
キーボードからの入力を判定
以下は read コマンドを使って、スクリプトの引数を判定(照合)する代わりにキーボードからの入力を照合するように書き換えた例です。
前述の例と同様、条件の値(キーボードからの入力)は予め tr コマンドを使って小文字に変換しています。
#! /bin/bash read -p "yes or no: > " input # キーボードからの入力を変数 input に格納 case `echo "$input" | tr A-Z a-z` in # $input を小文字に変換してから照合 "y"|"yes") echo "Yes";; "n"|"no") echo "No" ;; *) echo "Something else" ;; esac
以下は実行例です。
read コマンドの -p オプションで「yes or no: >」というプロンプトを表示しています。
./caseTest6 return yes or no: > y return # y と入力 Yes ./caseTest6 return yes or no: > YES return # YES と入力 Yes ./caseTest6 return yes or no: > NO return # NO と入力 No ./caseTest6 return yes or no: > nO return # nO と入力 No ./caseTest6 return yes or no: > yesno return # yesno と入力 Something else
for 文
for 文は一定回数の繰り返し処理を行わせる制御構造です。
以下が基本的な書式です。値のリストの数だけ処理が実行されます。
for変数in値のリストdo処理done
for 文は変数に値のリストで指定した値を順番に代入し、それぞれに対して do 〜 done の間の処理を繰り返し、全てを実行したら終了します。
- 値のリストに指定された1つ目の値を変数に代入し、do 〜 done 間の処理を実行
- 値のリストに指定された2つ目の値を変数に代入し、do 〜 done 間の処理を実行
- 値のリストに指定された3つ目の値を変数に代入し、do 〜 done 間の処理を実行
以降同様に処理を実行し、リストの全ての値を処理したら終了。
変数
for 文に指定する変数は、任意の変数を使用することができます。
値のリスト
値のリストには文字列や数値のリストを直接指定することも、変数やコマンド置換を使ったコマンドの実行結果、ブレース展開、配列、ファイルなどを指定することができます。
また、for はコマンドなので、コマンドラインでも使用することができます。
以下は1行で入力する場合の書式です。
for変数in値のリスト;doコマンド;done
コマンドラインでもセミコロンの代わりに、return を押して改行して実行することもできます。
改行すると、2行目以降にプロンプト(>)がされるので、プロンプトの後に続きを入力して最後に done を入力し return を押すと処理が実行されます。
以下は、値のリストに記述されている数値を変数 i に読み込んでそれらを出力するスクリプトです。
#! /bin/bash for i in 1 2 3 4 5 # 変数:i 値のリスト: 1 2 3 4 5 do echo $i # 変数 $i に読み込まれた値を出力 done
以下はスクリプトに実行権を付与してからスクリプトを実行した結果の例です。
変数 i には繰り返し処理ごとに1から5までの値が代入されて、 do 〜 done の間の echo により順番に合計5回出力されます。
chmod +x forTest1 return # 実行権を付与 ./forTest1 return # スクリプトを実行 1 2 3 4 5
以下は上記のスクリプトと同じことをコマンドラインで実行した例です。
1行目はセミコロンを使って1行で記述して実行した例で、8〜10行目はコマンドラインで改行して実行した例です。
for i in 1 2 3 4 5; do echo $i; done return # 実行 1 2 3 4 5 $ for i in 1 2 3 4 5 return # 改行 > do echo $i return # 改行 > done return # 実行 1 2 3 4 5
また、bash では他のプログラム言語と同じような以下の書式も使うことができます。
但し、条件式などを囲む括弧は2つ (( )) で囲みます。
for((初期化式; 繰り返し条件式; 増減式))do処理done
以下は前述のスクリプト forTest1 を上記の書式で書き換えた例です。
for と (、( と i、+ と ) の間やセミコロンの後にはスペースがあっても問題ありませんが、括弧 (( や )) の間にスペースがあるとエラーになります。
#! /bin/bash for ((i=1; i<=5; i++)) do echo $i done
以下は上記と同じことをコマンドラインで実行した例です。
for((i=1;i<=5;i++)); do echo $i; done return 1 2 3 4 5
変数を値のリストに指定
以下は引数の値をリストに指定して、順番に出力するスクリプトです。
引数のリストは変数(位置パラメータ)$@ に格納されています。
#! /bin/bash for param in "$@" #値のリストに引数のリストを指定 do echo $param done
以下は実行例です。
./forTest1 "apple pie" "orange juice" "grape soda" return apple pie orange juice grape soda
スクリプト forTest3 では値のリストに変数を指定する際にダブルクォートで囲んでいます。
もし、以下のようにダブルクォートで囲んでいない場合は、実行結果が異なります。
#! /bin/bash for param in $@ #変数をダブルクォートで囲んでいない do echo $param done
変数の値が空白を含む文字列の場合、以下のように空白により分割されて個別の引数として扱われてしまいます。
./forTest3_2 "apple pie" "orange juice" "grape soda" apple pie orange juice grape soda
コマンドの実行結果を値のリストに指定
値のリストには、コマンドの実行結果を指定することができます。
コマンドの実行結果を指定するには、コマンド置換 ` ` を使ってコマンドをコマンドの出力で置き換えます。
以下はカレントディレクトリにある全てのテキストファイルのサイズを大きい順に表示するスクリプトです。
#! /bin/bash for file in `ls -S *.txt` do echo "Size(byte): `wc -c $file`" done
ls -S *.txt はカレントディレクトリの全テキストファイルのファイル名をサイズの大きい順に出力します。
ls -S *.txt return # ls -S コマンドの実行例 cs_sample.txt sample.txt test.txt system_log.txt info.txt sample2.txt sample_x.txt process.txt
それぞれのファイル名は変数 $file に格納されて、do 〜 done 間で処理されます。
wc コマンドは -c オプションを指定するとファイルのバイト数を表示します。echo コマンドの中で展開したいので、`wc -c $file`のようにコマンド置換を使っています。
以下は実行例です。
./forTest4 return # スクリプトを実行 Size(byte): 62297 cs_sample.txt Size(byte): 59199 system_log.txt Size(byte): 913 sample2.txt Size(byte): 519 sample.txt Size(byte): 417 info.txt Size(byte): 111 sample_x.txt Size(byte): 91 process.txt Size(byte): 22 test.txt
※カレントディレクトリのファイルを順に処理するような場合などでは、ls コマンドではなくパス名展開(*)を利用することができます。
以下はコマンドラインでの実行例です。
for var in * > do > echo "$var" # ダブルクォートで囲む > done for var in *.txt > do > echo "$var" # ダブルクォートで囲む > done #以下でも同じ結果になりますが、ある意味冗長 for var in "`ls`" # ダブルクォートで囲む(空白で分割されないように) > do > echo "$var" # ダブルクォートで囲む > done for var in "`ls *.txt`" # ダブルクォートで囲む(空白で分割されないように) > do > echo "$var" # ダブルクォートで囲む > done
seq コマンドの利用
seq コマンドは、連続する番号を出力するコマンドです。
seq コマンドで連番を作成して値のリストに指定し、ループ(繰り返し)処理を実行することができます。
この場合も、コマンドの実行結果を値のリストに指定するのでコマンド置換を使います。
以下は seq コマンドで1〜5の連番を生成して、echo を5回繰り返し実行するスクリプトです。
#! /bin/bash for n in `seq 5` do echo "$n 回目の処理" done
以下は実行例です。
./forTest5 return 1 回目の処理 2 回目の処理 3 回目の処理 4 回目の処理 5 回目の処理
以下は、seq コマンドで連続した2桁の番号を含むファイル名(sample_01.txt〜sample_05.txt)を生成し、touch コマンドでカレントディレクトリに空のテキストファイルを作成するスクリプトです。
変数 $fn には seq コマンドで生成したファイル名が入ります。
#! /bin/bash for fn in `seq -f "sample_%02g.txt" 5` do touch $fn done
以下は read コマンドでユーザからの入力を読み取り、変数に代入してその値を元に空のテキストファイルを作成するスクリプトです。
read コマンドでは -p オプションでプロンプトを表示し作成するファイルの数(Number)とファイルの名前の先頭部分の文字列(Prefix)を入力するように促します。
作成するファイルの数は変数 $num に代入し、seq コマンドの引数に指定します。
seq コマンドで作成されるファイル名(01.txt など)は変数 $fn に代入されます。
ファイルの名前の先頭部分の文字列は変数 $pre に代入し、touch コマンドでファイルを作成する際にファイル名の先頭に追加します。
#! /bin/bash read -p "Enter Number and Prefix > " num pre for fn in `seq -f "%02g.txt" $num` do touch $pre$fn done
以下は実行例です。
ls return #ディレクトリが空なのを確認 ./forTest7 return #スクリプトを実行(以下のプロンプトが表示される) Enter Number and Prefix > 3 sample- return #ファイル数と文字列を入力 ls -l return #以下のファイルが作成されている total 0 -rw-r--r-- 1 foo staff 0 10 3 10:56 sample-01.txt -rw-r--r-- 1 foo staff 0 10 3 10:56 sample-02.txt -rw-r--r-- 1 foo staff 0 10 3 10:56 sample-03.txt
ブレース展開を値のリストに指定
ブレース展開を値のリストに指定することもできます。
以下はコマンドラインでの実行例です。
for fname in sample{1..5}.jpg return #コマンドラインで実行
> do return
> echo $fname return
> done return
sample1.jpg
sample2.jpg
sample3.jpg
sample4.jpg
sample5.jpg
配列を値のリストに指定
配列を値のリストに指定することもできます。
${配列名[@]} で全ての値を出力することができるので、これを値のリストに指定します。
以下はコマンドラインでの実行例です。
array=("apple" "banana" "mango") return #配列を生成
for elm in ${array[@]} return #コマンドラインで実行 ${配列名[@]} を値のリストに指定
> do
> echo $elm
> done
apple
banana
mango
ファイルから読み込む
cat コマンドなどを使ってファイルの内容を読み込ませて、値のリストに指定することもできます。
この例では以下のようなテキストファイル(sample.txt )を読み込ませます。
cat sample.txt return First Line Second Line Third Line Fifth Line (Fourth Line is empty)
コマンドの実行結果を値のリストに指定するのでコマンド置換を使います。
但し、cat コマンドはファイルを1行ずつ読み出すのではないので、ファイルの内容や「値のリストに指定するコマンドの実行結果」や「変数をダブルクォートで囲むかそうでないか」で実行結果が変わってきます。
ファイルの内容を1行ずつ読み込んで処理をする場合は、while 文を使います。
以下は、コマンドの実行結果 `cat sample.txt` と変数 $line をダブルクォートで括る例です。
#! /bin/bash for line in "`cat sample.txt`" do echo "$line" done
以下が実行結果です。
./forTest8 return First Line Second Line Third Line Fifth Line (Fourth Line is empty)
以下は、変数 $line のみをダブルクォートで括る例です。
#! /bin/bash for line in `cat sample.txt` #コマンドの実行結果のダブルクォートを外す do echo "$line" done
以下が実行結果です。for に渡される際にファイルの内容が空白や改行で分割され、それぞれ処理されます。
./forTest8-2 return # First Line Second Line Third Line Fifth Line (Fourth Line is empty)
以下のように繰り返しをカウントして確認するとわかるのですが、最初の例(forTest8)では for は1回しか繰り返しを行っていません。
変数($line)をダブルクォートで括ってあるので、読み込んだテキストファイルの改行が反映されて各行が改行されて表示されています(変数 $line をダブルクォートで括らないと全て1行で出力されます)。
((count++)) は let コマンドを使ってカウント(count 変数)の値を処理のたびに1増加させています。
#! /bin/bash count=0 #繰り返しをカウントする変数 for line in "`cat sample.txt`" do ((count++)) #繰り返しごとに1増加 echo "$line" echo "$count" done
コマンドの実行結果 `cat sample.txt` をダブルクォートで括った上記の場合の実行結果は以下のようになり、変数 $line にはファイルの内容が丸ごと一回渡されただけでした。
./forTest8 return First Line Second Line Third Line Fifth Line (Fourth Line is empty) 1
コマンドの実行結果 `cat sample.txt` をダブルクォートで括らないと以下のような出力になります。
./forTest8 return First 1 Line 2 Second 3 Line 4 Third 5 Line 6 Fifth 7 Line 8 (Fourth 9 Line 10 is 11 empty) 12
以下は、カレントディレクトリにある sample から始まるテキストファイルのファイル名と内容を表示するスクリプトです。
カレントディレクトリのファイルを順に読み込むには、リストに指定する際にパス名展開を使っています。
do~done 間では、echo でファイル名を、cat でファイルの内容を表示しています。
#! /bin/bash for file in sample*.txt do echo "File Name:$file" cat "$file" echo "End of: $file" done
以下は実行例です。「sample*.txt」にマッチする2つのファイルの名前と内容が表示されています。
./forTest9 return File Name:sample.txt First Line Second Line Third Line Fifth Line (Fourth Line is empty) End of: sample.txt File Name:sample2.txt this is sample2. abcdefg 1234 End of: sample2.txt
while 文
while 文は「条件が成り立っている間(指定した条件の判定が true である限り)、処理を繰り返す」制御構造です。
while 文は指定された条件を判定(評価)し、結果が true である場合のみ繰り返し処理を継続します。
繰り返す度に条件を判定して true であれば処理を実行し、条件の判定結果が false になった時点で処理を終了します。
通常 for 文は処理する回数が明確な場合に使用し、処理する回数が明確ではない場合に while 文を使用します。
以下が基本的な書式です。
条件を判定して結果が true であれば、do〜done の間に記述された処理を実行します。
while条件do処理done
while 文はコマンドラインでも使用できます。以下が基本的なコマンドラインでの書式です。
処理でコマンドを複数記述する場合は、コマンドをセミコロンで区切ります。
while条件 ;do処理 ;done
コマンドラインでもセミコロンの代わりに、return を押して改行して実行することもできます。
改行すると、2行目以降にプロンプト(>)がされるので、プロンプトの後に続きを入力して最後に done を入力し return を押すと処理が実行されます。
条件には test コマンド の [ ] やその他のコマンドなどを記述します。
以下は条件に test コマンド [ ] に数値を比較する演算子 -le(左辺が右辺より小さいか等しい場合に true を返す)を指定して1〜5を表示するスクリプトです。
最初に数値を格納する変数 i に1を代入しておきます。
条件 [ $i -le 5 ] は $i の値が5以下の場合は true を返し、5より大きい場合は false を返します。
条件が true の場合は do〜done の間に記述されている echo "$i" により変数 $i の値が表示さ、続いて ((i++)) が実行されます。
((i++)) は let コマンドのインクリメント演算子を使って変数 $i の値を1増加させています。
(( )) は let コマンドの別の書式ですが、let i++ と記述することもできます。
((i++)) は ((i=i+1)) と記述するのと同じことです。
また、((i++)) は i=$((++i)) と前置インクリメントを使って記述することもできますが、この場合後置インクリメントを使って i=$((i++)) とすると i の値は1から変わらず無限ループになってしまいます。
#! /bin/bash i=1 while [ $i -le 5 ] do echo "$i" ((i++)) #または let i++ または ((i=i+1)) または i=$((++i)) done
以下は実行例です。
./whileTest1 1 2 3 4 5
let コマンド (( )) は bash では使えますが、互換性を考慮して expr コマンドを使って記述すると以下のようになります。
expr コマンドは結果を標準出力に出力するので、計算結果を変数に入れるにはコマンド置換を使います。
但し、expr コマンドは処理が遅いので (( )) を使用した方が処理が速いです。
#! /bin/bash i=1 while [ $i -le 5 ] do echo "$i" i=`expr $i + 1` # expr コマンドで i の値を増加 done
以下は条件にも let コマンドの (( )) の書式を使う場合の例です。
(( )) の中の式では演算子 <= を使って条件を指定し、左右の値の大小の比較をして判定しています。
#! /bin/bash i=1 while ((i<=5)) do echo "$i" ((i++)) #または let i++ done
以下は前述のスクリプトをコマンドラインで実行する例です。
i=1; while ((i<=5)); do echo "$i"; ((i++)); done return 1 2 3 4 5 #以下は return で改行して入力する場合の例 i=1 return while ((i<=5)) return > do return > echo "$i" return > ((i++)) return > done return 1 2 3 4 5
前述の例のように実行する回数が決まっている場合は、for 文を使って以下のように記述しても同じになります。
#! /bin/bash for i in `seq 5` do echo "$i" done #または #! /bin/bash for ((i=1; i<=5; i++)) do echo "$i" done
以下は、キーボードからの入力を read コマンドで読み取って入力された文字列を表示し、「no」が入力された場合は終了するスクリプトです。
条件には、read コマンドで読み込んだ値が格納されている変数 $str の値が no という文字列でないかを [ ] コマンドで判定しています。
その際、変数 $str はダブルクォートで括るか、事前に変数 $str に空ではない文字列(初期値)を設定しておく必要があります。
基本的に変数はダブルクォートで括っておくと安全です。関連項目:変数と引用符
#! /bin/bash while [ "$str" != "no" ] do read -p "Enter a word or 'no' to stop: > " str echo You enter: "$str" done
以下は実行例です。
このスクリプトの場合、no と入力された後、その文字列を表示し、条件に戻った際に false になり終了します。
./whileTest2 return Enter a word or 'no' to stop: > abc return # abc と入力 You enter: abc Enter a word or 'no' to stop: > no return # no と入力 You enter: no
無限ループと break
条件にヌルコマンド : (コロン)を指定すると、ヌルコマンドは何もせず終了ステータスが 0(true)になるので、条件が true となり続け無限ループになります。
ループを抜けるには ctrl + c で強制的に終了するか、while 文の中にループを終了する break コマンドを記述します。
ヌルコマンドの代わりに true と記述しても条件が常に true になるので、無限ループになります。
以下は、条件にヌルコマンド : (コロン)を指定して無限ループにして、処理の中でキーボードからの入力を読み取り、if 文を使ってその値が「no」の場合は break コマンドでループを終了するスクリプトです。
break コマンドは for 文や while 文などで使われるループを抜けるためのコマンドです。実行すると、その時点で現在のループから抜けてそのループ内の以降の処理を実行しません。
#! /bin/bash
while : # または while true でも同じ
do
read -p "Enter a word or 'no' to stop:> " str # 入力された文字を変数 str に格納
if [ "$str" != "no" ] # 入力された文字が no でなければ、その文字を表示
then
echo You enter: "$str"
else # 入力された文字が no であれば「Stopped」と表示して break で終了
echo "Stopped"
break
fi
done
echo "done の後の echo" #ループを抜けた後はここに来る
以下が実行例です。
このスクリプトの場合、no と入力された後「Stopped」と表示し、break コマンドでループの処理(do〜done)を抜け、done の次の行に移り「done の後の echo」と表示して終了します。
./whileTest3 return Enter a word or 'no' to stop:> abc return # abc と入力 You enter: abc Enter a word or 'no' to stop:> 123 return # 123 と入力 You enter: 123 Enter a word or 'no' to stop:> no return # no と入力 Stopped done の後の echo #ループを抜けた後に最後の行が実行され、それ以降何もないので終了
条件にヌルコマンド(:)を指定しなくても、条件に指定したコマンドの実行が成功している間は処理を繰り返すことができます。
以下は前述の例をヌルコマンドを使わずに書き換えた例で、動作はほぼ同じです。
2行目は、ループの前に記述してあるので、初回のみ実行され、前述の例の read -p でのプロンプト表示のようにするため、echo コマンドに -n オプリョンを指定して出力の最後に改行しないようにしています。
条件には read コマンドを指定しているのでキーボードから文字が入力され、return キーが押されればコマンドは成功するので処理が繰り返されます。
キーボードから no が入力されると、break コマンドで終了します(前述の例と同じ)。
前述の例と異なるのは、 control + d が押されると EOF(End Of File)と言う終了を示す信号が送られるので、その場合は read コマンドは失敗するので、その時点で while 文は終了します。
#! /bin/bash
echo -n "Enter a word or 'no' to stop:> " # -n で最後に改行を出力させない
while read str #条件に read コマンドを指定
do
if [ "$str" != "no" ]
then
echo you enter: "$str"
else
echo "Stopped"
break
fi
echo -n "Enter a word or 'no' to stop: >"
done
echo "done の後の echo "
continue
continue コマンドを使うと、処理を中断して(それ以降の処理をスキップして)ループの先頭に移動することができます。
break コマンドではループから抜けてしまうのでそのループは終了してしまいますが、continue コマンドではループは終了せず、それ以降の処理をスキップしてループの先頭に戻ります。
以下は case 文を使って、y と入力されたら「You entered: y」と表示し、n と入力されたら「You entered: n」「Exiting」と表示して break コマンドでループを抜け、それ以外の文字が入力されたら「?」と表示して continue コマンドでループの先頭に戻るスクリプトです。
#! /bin/bash
while : # ヌルコマンドで無限ループに
do
read -p "Enter y or n:> " str
case "$str" in
"y") echo "You entered: y";;
"n") echo "You entered: n"; echo "Exiting"; break;; # ループを抜けて done の次へ
* ) echo "?"; continue;; # ループの先頭に戻る(y と n 以外が入力された場合)
esac
echo "Thank you!" # y と入力した場合には表示される
done
echo "bye" # n と入力してループを抜けると表示される
10行目の echo が実行されるのは「y」と入力された場合のみで、「y」や「n」以外が入力された場合は continue コマンドでループの先頭に戻るので表示されません。
12行目の echo が実行されるのは「n」と入力されて break コマンドが実行され、ループを抜ける場合のみです。
以下が実行例です。
./whileTest4 return Enter y or n:> y return # y を入力 You entered: y Thank you! # スクリプトの10行目 Enter y or n:> x return # x を入力 ? Enter y or n:> n return # n を入力 You entered: n Exiting bye # スクリプトの12行目
ファイルから読み込む
read コマンドは標準入力から文字列を読み込むので、リダイレクトまたはパイプを使ってファイルを読み込んで表示することができます。
以下の例では次のような行頭に空白(スペースやタブ)が入ったテキストファイル(sample.txt)を読み込みます。
First Line Second Line Third Line Fifth Line (Fourth Line is empty) Sixth Line \n
リダイレクト
以下はリダイレクトを使って sample.txt を読み込んで1行ずつ表示するスクリプトです。
< ./sample.txt でリダイレクトを使ってカレントディレクトリにある sample.txt を読み込んでいます。
#! /bin/bash while read line do echo "$line" done < ./sample.txt
読み込んだファイルを while read line でファイルの終了(EOF)になるまで、各行を変数 line に格納して表示しています。
変数名を line とすることが多いですが、任意の変数名を使うことができます。
read コマンドは標準入力から1行読み取ってその値を変数に代入するので、その変数を出力すればファイルの内容を表示することができます。
また、ファイルの終了(EOF)で read コマンドはそれ以上行を読み込めないのでコマンドは失敗し、while 文が終了します。
以下は実行結果の例です。行頭のスペースやタブ、エスケープ文字のバックスラッシュが取り除かれています。
./whileTest5 return First Line Second Line Third Line Fifth Line (Fourth Line is empty) Sixth Line n
エスケープ文字
前述の実行例を見ると、最後の行のバックスラッシュ\(エスケープ文字)が消えています。
エスケープ文字を解析せずにそのまま読み込むには以下のように、read コマンドに -r オプションを指定します。
#! /bin/bash while read -r line # read コマンドに -r オプリョンを指定 do echo "$line" done < ./sample.txt
行頭の空白(スペースやタブ)
また、前述の実行例では、テキストファイルにあった行頭のスペースやタブが read コマンドによりなくなっています。
これは read コマンドの行区切りや区切り文字の認識に使われる IFS(Internal Field Separator)のデフォルトの値に含まれるスペースとタブによります。
行頭や行末の空白(スペースやタブ)を取り除かれないようにするには、IFS= (一時的に IFSの値に何も指定しない)を指定して read コマンドを実行します。
「IFS=」の後に、セミコロンを付けないようにします。
#! /bin/bash while IFS= read line # read コマンドの前に IFS= と指定 do echo "$line" done < ./sample.txt
または、以下のように明示的に IFS=null と記述しても同じです。
#! /bin/bash while IFS=null read line # read コマンドの前に IFS=null と指定 do echo "$line" done < ./sample.txt
以下は実行例です。行頭のスペースやタブが取り除かれていません。
./whileTest5_1 return First Line Second Line Third Line Fifth Line (Fourth Line is empty) Sixth Line n
区切り文字の変更
read コマンドで行を読み込む際に IFS の値を一時的に変更することで、区切り文字を変更することができます。
以下のようなカンマ区切りのテキスト(sample.csv)がある場合、各行の内容をカンマで区切って読み込んで変数に格納することができます。
1st,2nd,3rd abc,def,ghi jkl,mno,pqr 123,456,789 012,345,678 901,234,567
以下は各行を読み込む際にカンマで区切って3つの変数(cs1 cs2 cs3)に格納して、2列め(cs2)だけの値を出力する例です。
この例の場合、各行がカンマで3つに区切られるので変数を3つ指定しています。
また、区切り文字を一時的にカンマ(,)変更するため、read コマンドの前に「IFS=,」を指定しています。
#! /bin/bash while IFS=, read cs1 cs2 cs3 do echo "$cs2" done < ./sample.csv
以下は実行例です。
./whileTest5_1_2 return 2nd def mno 456 345 234
パイプ
以下はパイプを使って sample.txt を読み込んで1行ずつ表示するスクリプトです。
cat コマンドでファイルを読み込みその出力をパイプで while に渡しています。
#! /bin/bash cat ./sample.txt | while read line #cat コマンドの出力をパイプで渡す do echo "$line" done
以下は for 文を使ってカレントディレクトリのテキストファイルを1つずつ取得して、ファイル名を表示し、read コマンドと if 文でユーザからの入力が y であれば、パイプを使ってそのファイル名を while 文に渡してファイルの内容を出力するスクリプトです。
#! /bin/bash
for file in *.txt #カレントディレクトリのテキストファイルを順に処理
do
echo "File Name: $file" #ファイル名を表示
read -p "show content? y/n > " str #ユーザー入力を変数 str に格納
if [ "$str" = y ] #ユーザー入力が y であれば(それ以外であれば何もしない)
then
cat "$file"| while read line #cat でファイルを読み込みパイプで while に渡す
do
echo "$line"
done # while 文はここまで
fi # if 文はここまで
done # for 文はここまで
以下は実行例です。
./whileTest5_2_1 return File Name: log.txt # File Name: ファイル名 を表示 show content? y/n > return #何も入力せず return File Name: sample.txt show content? y/n > y return # y を入力して return First Line # ファイルの内容が表示される Second Line Third Line Fifth Line (Fourth Line is empty) Sixth Line n File Name: sample2.txt show content? y/n > n return # n を入力して return
ヒアドキュメント
コマンド置換 ` ` を使って cat コマンドで読み込んだファイルの内容を変数に格納し、その変数をヒアドキュメントで読み込ませることもできます。
#! /bin/bash file=`cat ./sample.txt` #cat コマンドの出力をコマンド置換で変数へ代入 while read line do echo "$line" done << EOF #cat ヒアドキュメントで変数を読み込む $file EOF
関数
シェルスクリプトでも関数を作成することができます。
以下が書式です。
function 関数名 () {
処理・・・
}
先頭の function は省略することができます。
関数名 () {
処理・・・
}
関数を使うには、関数名に続けて引数(あれば)を指定して実行します。関数名の後のカッコは不要です。
関数名 引数
以下は実行すると「Hello Function!」と表示する関数の例です。
myFunc1 という名前のスクリプト(ファイル)を作成して以下の関数の定義を記述し、パスを通したディレクトリ(この例では ~/bin)に配置します。
#! /bin/bash
# 関数の定義
function hello() {
echo 'Hello Function!'
}
# 関数の呼び出し
hello
以下をコマンドラインで実行します(行頭の $ はプロンプトを表します)。この例ではスクリプトを配置したディレクトリにはパスを通してあるのでパスは省略できます。
$ bash myFunc1 return # myFunc1 を実行 Hello Function! # 記述されている関数 hello() が実行される
スクリプトに実行権限を設定すればスクリプト名だけで実行できます。
$ chmod a+x ~/bin/myFunc1 return # myFunc1 に実行権限を設定 $ myFunc1 return #スクリプト名だけで実行 Hello Function! # 関数 hello() が実行される
コマンドライン上で定義して実行
関数はファイルに記述しなくても、コマンドライン上で定義してそのまま実行することもできます。
$ function hello() { return # return で改行
> echo 'Hello World' return # return で改行
> } return # return で改行
$ hello return #定義した関数を実行
Hello World
別ファイルに定義して、source コマンドで呼び出す
関数を別ファイルに定義しておき、source または . コマンドでそのフィルを読み込んでから関数を実行することもできます(但し、注意が必要です)。
source(または .)コマンドは他のスクリプトファイルを現在のカレントシェルに読み込み、変数や関数を使用できるようにします。
以下は myFunc1x という関数を定義したファイルを作成し、source コマンドでファイルを読み込んで、記述されている関数を実行しています。
$ cat ~/bin/myFunc1x return // myFunc1x の内容を表示
# 関数の定義
function hello2() {
echo 'Hello 2!'
}
$ hello2 return // 関数を実行しようとするがコマンドは見つからない(エラー)
bash: hello2: command not found
$ source ~/bin/myFunc1x return //myFunc1x を source コマンドで読み込む
$ hello2 return // 関数を実行
Hello 2!
source や . での実行は注意が必要
シェルスクリプトを実行する場合、通常は source および . を使いません。
通常は bash などの引数として実行するか、シェルスクリプトに実行権を付けて実行します(シェルスクリプトの実行)。この場合、実行中のシェルとは別のシェルが新たに起動してそのシェルでスクリプトを実行し、シェルスクリプトが終了するとそれを起動した元のシェルに戻ります。
このため、実行したスクリプトが呼び出し元のシェル環境に悪い影響をもたらすことはありません。
これに対して、source や . は実行中のシェルでファイル中のコマンドを実行します。そのため、実行中のシェル環境に影響を与えて動作がおかしくなり、問題が発生する可能性があるので注意が必要です。
bashrc などのシェルの設定ファイルなどは、現在のシェル環境の状態を変更する必要があるため source で読み込みます。
関数の引数
関数は引数を持つことができます。
関数内ではシェルスクリプトの引数と同様、特殊変数 $1 ~ $n で各引数を参照することができ、$# や $@、$* も使用できます($0 は関数名ではなく、実行するスクリプト名になります)。
以下は特殊変数を使って指定された引数の値や数などを出力する関数を記述したスクリプトの例です。
#!/bin/bash
printArgs() {
#実行するスクリプト名(パスを含む)
echo "\$0=$0"
#実行するスクリプト名
echo "\${0##*/}=${0##*/}"
#引数の個数
echo "\$#=$#"
#全ての引数のリスト
echo "\$@=$@"
echo "\$*=$*"
#各引数
echo "\$1=$1"
echo "\$2=$2"
echo "\$3=$3"
}
#関数の呼び出し(3つの引数 foo、bar、baz を指定)
printArgs foo bar baz
以下が実行結果です。
$ chmod a+x ~/bin/myFunc2 return # myFunc2 に実行権限を設定 $ myFunc2 return #スクリプト名で実行 #実行結果 $0=\/Users/foo/bin/myFunc2 ${0\#\#*/}=myFunc2 $\#=3 $@=foo bar baz $*=foo bar baz $1=foo $2=bar $3=baz
関数の戻り値
シェルスクリプトの関数には戻り値というものがなく、標準出力で結果を返します。
return コマンドに指定できる値は 0 または 1~255 の正の整数値のみで、関数の終了ステータスになります(関数の戻り値としての機能ではありません)。正常終了の終了ステータスは 0。
以下は引数が指定されていない場合(引数の数が0の場合)は戻り値として1(終了ステータス)を返し、引数が指定されていれば、指定された値を出力し、戻り値0を返す関数の例です。
#!/bin/bash
printInput() {
[ $\# -eq 0 ] && return 1 #引数の数が0の場合は1を返す
echo "$1"
return 0
}
以下は上記関数の実行例です。
$ printInput return # 関数を実行(読み込まれてないのでエラー) bash: printInput: command not found # $ . ~/bin/myFunc3 return #.(ドット)コマンドで関数の記述されているスクリプトを読み込む $ printInput return # 引数無しで実行 $ echo $? return # 終了ステータスを確認 1 $ printInput Hello return # 引数を指定して実行 Hello $ echo $? return # 終了ステータスを確認 0
ローカル変数を使う
シェルスクリプトでは関数内で宣言した変数はグローバル変数となります。
変数をローカル変数として扱うには、変数に local を指定します。
local 変数名=値
以下は関数内でローカル変数を使う例です。関数の外でローカル変数の値 $from を echo していますが、アクセスできないので出力されません。
#!/bin/bash
function hello_local() {
local from="foo" # ローカル変数
echo "Hello from $from"
}
#関数の呼び出し
hello_local
# ローカル変数の出力→ローカル変数にはアクセスできない
echo "\$from= $from"
以下は実行例です。
$ myFunc4 return # 実行権限を設定していないのでエラー bash: /Users/foo/bin/myFunc4: Permission denied $ bash myFunc4 return # bash コマンドで実行 Hello from foo $from= # ローカル変数にはアクセスできない(値 foo は出力されない)
ヒアドキュメント
ヒアドキュメントは bash の機能(リダイレクト)の1つで、複数行の文字列を記述できる機能です。
以下は man bash からの抜粋です。
Here Documents This type of redirection instructs the shell to read input from the current source until a line containing only word (with no trailing blanks) is seen. All of the lines read up to that point are then used as the standard input for a command. The format of here-documents is: <<[-]word here-document delimiter
例えば、スクリプトの中で複数行の出力をするには echo コマンドを複数回記述することもできますが、ヒアドキュメントを使うと簡潔に記述することができます。
以下は echo コマンドとヒアドキュメント(と cat コマンド)を使って3行の文字列を出力する例です。
#! /bin/bash echo abc # echo で出力 echo def # echo で出力 echo ghi # echo で出力 cat << EOT # cat とヒアドキュメントで出力 abc def ghi EOT ##### 以下は実行結果 #### abc def ghi abc def ghi
ヒアドキュメントとして入力した文字列は標準入力として扱われるので、cat コマンドや tr コマンドなどと使うことができます。(cat コマンドはファイルが指定されていない場合は標準入力から読み込みます)
echo コマンドは標準入力から読み込まないので使えません。
以下が書式です。
<< IDとなる文字列 出力文字列 IDとなる文字列
「IDとなる文字列」は同じ値を指定します。 EOT や EOD などがよく使われますが、任意の文字を使うことができます。
最初(開始位置の)「IDとなる文字列」の前後にはスペースがあってもなくても構いません。
但し、終了の「IDとなる文字列」の前後に空白(スペースなど)があると正しく機能しません。
ヒアドキュメントに記述した変数は(引用符で括っても)展開され、コマンド置換も実行されます。
#! /bin/bash
foo=12345 #変数 foo を定義
bar=abcde #変数 bar を定義
cat << EOD #ヒアドキュメント開始
here document test
$foo
foo is ${foo}
foo is "$foo"
foo is '$foo'
$bar
$(date)
`date`
EOD
以下が実行結果です。
here document test 12345 #変数 foo foo is 12345 #変数 foo foo is "12345" #変数 foo foo is '12345' #変数 foo abcde #変数 bar 2019年 10月 6日 日曜日 13時53分41秒 JST #コマンド置換 $(date) 2019年 10月 6日 日曜日 13時53分41秒 JST #コマンド置換 `date`
tr コマンドを使った例
以下は cat コマンドではなく tr コマンドを使って小文字を大文字に変換する例です。
#! /bin/bash
foo=12345 #変数 foo を定義
bar=abcde #変数 bar を定義
tr a-z A-Z << ET #ヒアドキュメント開始(tr コマンドを使用)
here document test
${bar}
$PATH
ET
以下が実行結果です。
HERE DOCUMENT TEST #tr コマンドで大文字に変換 ABCDE #変数 bar(tr コマンドで大文字に変換) /USR/LOCAL/BIN:/USR/BIN:/BIN:/USR/SBIN:/SBIN:/USERS/FOO/BIN #変数 PATH
変数やコマンドを展開しない
「IDとなる文字列」を引用符(ダブルクォートまたはシングルクォート)で囲むと変数やコマンドを展開しません。
#! /bin/bash
foo=12345 #変数 foo を定義
bar=abcde #変数 bar を定義
cat <<"EDT" #ヒアドキュメント開始(IDとなる文字列を引用符で括る)
$foo
${bar}
$(date)
EDT
以下が実行結果です。
$foo #変数は展開されない
${bar} #変数は展開されない
$(date) #コマンドは展開されない
行頭のタブを無視
<<- のようにハイフン(-)を指定すると、行頭のタブ(スペースは対象外)が無視されるようになりスクリプトのインデントを崩さずにヒアドキュメントを記述できます。
#! /bin/bash cat <<- ECD #ヒアドキュメント開始 while : do this done ECD
以下が実行結果です。
while : do #行頭のタブが無視(削除)される this #行頭のタブが無視(削除)される done #行頭のタブが無視(削除)される
ヒアドキュメントの内容を変数に代入
ヒアドキュメントの内容を変数に代入するには、以下のようにコマンド置換 $( ) を使います。
変数の値を出力する際は、ダブルクォートで囲まないと1行で表示されます。
#! /bin/bash foo=12345 #変数 foo を定義 bar=abcde #変数 bar を定義 heredoc=$(cat << EOHD #変数 heredoc に内容を代入 abc def $foo $bar `date` EOHD) echo $heredoc #変数 heredoc を出力 echo "$heredoc" #変数 heredoc をダブルクォートで括って出力
以下は実行結果です。
abc def 12345 abcde 2019年 10月 6日 日曜日 14時25分02秒 JST #1行で表示 # ダブルクォートで囲むと改行が反映される abc def 12345 abcde 2019年 10月 6日 日曜日 14時25分02秒 JST
コマンドライン(ファイルの作成)
コマンドラインでも使うことができます。
tr a-z A-Z << EOD return > abcdefg return > hijklmn return > EOD return ABCDEFG HIJKLMN foo=$(cat << EOT return > apple return > grape return > orange return > EOT) return echo $foo return apple grape orange echo "$foo" return #変数に代入した場合はダブルクォートで括ると改行が反映される apple grape orange
以下のようにリダイレクトと組み合わせることでヒアドキュメントの内容のファイルを作成することができます。
リダイレクト > は指定したファイルが存在しなければ新規作成、存在すれば上書きになります。
追記は >> を使います。
cat << EOF > sample.csv return # sample.csv を新規作成(または上書き) > abc,def,ghi return > jkl,mno,pqr return > 123,456,789 return > EOF return cat sample.csv return # sample.csv の内容を確認 abc,def,ghi jkl,mno,pqr 123,456,789 cat << EOF >> sample.csv return # sample.csv に追記 > 012,345,678 return > 901,234,567 return > EOF return cat sample.csv return # sample.csv の内容を確認 abc,def,ghi jkl,mno,pqr 123,456,789 012,345,678 901,234,567
一時ファイルの作成 mktemp
mktemp コマンドを使うと、作業用に一時ファイルやディレクトリを作成することができます。
作成される一時ファイルやディレクトリの名前は、自動的に他と異なるユニークなものに設定されます。
mktemp [オプション] [文字列]
以下のようなオプションがあります。
| オプション | 意味 |
|---|---|
| -d | 一時ファイルではなく一時ディレクトリを作成 |
| -q | エラー・メッセージを表示しない |
| -t 接頭辞 | 作成されるファイル名に指定した接頭辞を付ける |
| 文字列 | 大文字「X」を末尾に含んだ文字列を指定(Xはランダムな文字に置き換えられる) |
mktemp コマンドを実行すると、空のファイルが作成され標準出力にファイルパスが表示(出力)されます。
デフォルトでは環境変数 TMPDIR に設定されているディレクトリ(一時ファイル用フォルダ)に、tmp.XXXXXXXX(Xはランダムな文字)というような名前でファイルが作成されます。
一時ファイル用フォルダに保存されたファイルは一定時間が経過すると削除されます。
mktemp return #一時ファイルを作成 /var/folders/xxx/xxxx...0000gn/T/tmp.9C98xs2h #作成されたファイルのパス
以下のようにコマンド置換 $( ) や ` ` を使ってファイルパスを変数に保存すれば、変数を使ってファイルに書き込みをしたり読み出したりすることができます。
作成したファイルのアクセス権は 600 (rw-------)になります(ディレクトリは 700/rwx------)。
tmpfile=`mktemp` return #一時ファイルを作成 # または tmpfile=$(mktemp) echo $tmpfile return #ファイルの場所(パス)を確認 /var/folders/xxx/xxxx...0000gn/T/tmp.irCNqxFo ls -l $tmpfile return #ファイルの詳細を確認 -rw------- 1 foo staff 0 9 27 10:13 /var/folders/xxx/xxxx...0000gn/T/tmp.irCNqxFo rm $tmpfile return #ファイルを削除 echo $TMPDIR return #環境変数 TMPDIR の値 /var/folders/xxx/xxxx...0000gn/T/
以下はオプションの文字列で保存先のディレクトリを指定して tmpDir という作成したディレクトリに一時ファイルを作成する例です。
mkdir tmpDir return #保存先のディレクトリを作成 tmpfile=`mktemp ./tmpDir/test.XXXXXX` return #./tmpDir/test.XXXXXX を指定してファイルを作成 echo $tmpfile return #ファイルパスを確認 ./tmpDir/test.RhWvxh rm $tmpfile return #ファイルを削除
以下は -t オプションを指定してファイル名に接頭辞を付けて作成する例です。
tmpfile=`mktemp -t test` return #-t を指定してファイルを作成 echo $tmpfile return #ファイルパスを確認 /var/folders/xxx/xxxx...0000gn/T/test.RC39yNnN rm $tmpfile return #ファイルを削除
以下はカレントディレクトリ直下の tmpDir ディレクトリに一時ファイルを作成し、 時刻と作成したファイルの情報、 ディレクトリの一覧を書き込み表示するスクリプト myscript4 の例です。
catコマンドで内容を表示後、作成した一時ファイルを削除し、確認のためディレクトリの一覧を出力するようにしています。
#!/bin/bash tmpfile=`mktemp ./tmpDir/sample.XXXXXXXXXX` #一時ファイルを作成 date > $tmpfile #日付時刻をファイルに出力 ls -l $tmpfile >> $tmpfile #作成したファイルの情報を追記 echo "tmpDir list: `ls ./tmpDir`" >> $tmpfile #tmpDir ディレクトリの一覧を追記 cat $tmpfile #一時ファイルの内容を表示 rm $tmpfile #一時ファイルを削除 echo "current tmpDir list: `ls ./tmpDir`" #tmpDir ディレクトリの一覧を表示
以下は上記ファイル myscript4 の実行結果です。
bash myscript4 return #スクリプトを実行 2019年 9月27日 金曜日 14時17分36秒 JST #date -rw------- 1 foo staff 48 9 27 14:17 ./tmpDir/sample.HGkqUGMgUB #ls -l(一時ファイルが表示される) tmpDir list: sample.HGkqUGMgUB #ls ./tmpDir current tmpDir list: #ファイルは削除されているので表示されない
スクリプト終了時に削除
前述の例では、スクリプトの最後の方に一時ファイルを削除するコマンドを記述しましたが、何らかの理由で処理の途中で終了してしまった場合はファイルを削除できない可能性があります。
trap コマンドを使うと、シェルスクリプト終了時にファイルを削除することができます。
trap コマンドでは、シグナルを受け取った際に実行するコマンドを設定することができます。
trap "実行するコマンド" シグナル
シェルスクリプト終了時に必ず実行される処理を指定するには、EXIT シグナル(0番のシグナル)を trap(捕捉)します。
trap "実行するコマンド" EXIT # または trap "実行するコマンド" 0
以下は trap コマンドを使ってスクリプトの終了時に作成した一時ファイルを削除するように myscript4 を書き換えた例です。
以下のスクリプトの trap コマンドは、終了のシグナルを捕捉してファイルを削除するのでスクリプト中では削除は確認できません。
また、rm コマンドでは -f オプションを指定してメッセージを表示せずに削除するようにしています。ディレクトリを中身ごと削除する場合は -r も併せて指定します。
#!/bin/bash tmpfile=`mktemp ./tmpDir/sample.XXXXXXXXXX` trap "rm -f $tmpfile" EXIT #終了のシグナルを捕捉してファイルを削除 date > $tmpfile ls -l $tmpfile >> $tmpfile echo "tmpDir list: `ls ./tmpDir`" >> $tmpfile cat $tmpfile
以下は実行例です。
bash myscript4 return #スクリプトを実行 2019年 9月27日 金曜日 15時27分17秒 JST -rw------- 1 foo staff 48 9 27 15:27 ./tmpDir/sample.SuRdtDwLdg tmpDir list: sample.SuRdtDwLdg ls tmpDir/ return #削除されているかを確認 #何も表示されず削除されている
シェルの展開順序
コマンドラインやシェルスクリプトでは、以下のいずれも全く同じことになります。
echo abc return abc echo 'abc' return abc echo "abc" return abc
シェルはユーザが入力した内容を受け取ってコマンドとして実行します。
その際、ユーザが入力した内容はコマンドとして実行する前にシェルにより解釈され、必要に応じて整形(変換)されます。
言い換えると、シェルは受け取った文字列をそのままコマンドとして実行するのではなく,まずシェル自身が入力された文字列を解釈し,特定のルールに従って変換してからコマンドを実行します。
上記の echo コマンドの場合、引数の文字列は空白やメタキャラクタを含まない単なる文字列なので、引数の引用符が取り除かれ(quote removal)て「echo abc」に変換されて実行されるので、全て同じことになります。(下記参照)
シェルには展開(Expansion)という機能があり、それらは特定の順序で実行されます。
man bash で「Expansion」を見ると以下のように記述されています。
EXPANSION Expansion is performed on the command line after it has been split into words. There are seven kinds of expansion performed: brace expansion, tilde expansion, parameter and variable expansion, command substitu- tion, arithmetic expansion, word splitting, and pathname expansion. The order of expansions is: brace expansion, tilde expansion, parame- ter, variable and arithmetic expansion and command substitution (done in a left-to-right fashion), word splitting, and pathname expansion.
bash の場合、シェルの展開順序は以下のようになっているようです。
- brace expansion(ブレース展開)
- tilde expansion(チルダ展開)
- parameter and variable expansion/arithmetic expansion (パラメータ・変数展開/算術式展開)
- command substitution(コマンド置換→3と同じステップ?)
- word splitting (単語分割)
- pathname expansion(パス名展開)
最後に必要であれば quote removal(クォートの削除)が行われコマンドに引数が渡されて実行されます。
| Expansion | 概要 | 記述例 |
|---|---|---|
| brace expansion ブレース展開 |
波括弧 { } の中に文字列をカンマで区切って指定すると、シェルがそれらの文字列を展開する | x{a,b,c} {a..g} |
| tilde expansion チルダ展開 |
チルダ「~」を前後の文字列によりホームディレクトリ や PWD の値などに展開 | ~/.bashrc ~/foo |
| parameter expansion パラメータ展開 |
変数の値の一部分を取り出したり置換する | ${LANG:0:5} ${PATH##*:} |
| variable expansion 変数展開 |
変数の展開 | $foo $LANG ${foo} |
| arithmetic expansion 算術式展開 |
算術式の結果を展開する | $((算術式)) |
| command substitution コマンド置換 |
コマンド名をコマンドの出力で置き換える | $( ) ` ` |
| word splitting 単語分割 |
引用符の付いていない文字列を空白など(IFSで設定)により単語に分割 | |
| pathname expansion パス名展開 |
*、?、[文字] が含まれ場合「パターン」とみなしマッチするファイルがあれば、そのファイル名に置き換える | *、?、[文字] |
前述の例では引数を引用符で括った場合とそうでない場合で同じ動作でしたが、以下の場合は異なります。
引数「*」を引用符で括らない場合、シェルが勝手に解釈して「*」を展開(パス名展開)してしまうため、find コマンドにアスタリスクが渡らないためエラーになります。(下記参照)
find . -name * return # エラー find: 1: unknown primary or operator find . -name '*' return # 正しく作動 . ./test.csv ./log.txt ./sample.txt find . -name "*" return # 正しく作動 . ./test.csv ./log.txt ./sample.txt
bash の以下の書式(オプション)を使うと、シェルが変数やパス名をどのように展開して動作しているかを確認することができます。
bash -x -c "コマンド"
例えば、カレントディレクトリを表す環境変数 $PWD を echo コマンドで出力する場合、以下のように記述すると変数 $PWD が展開されて値が表示されます。
echo $PWD return /Users/foo #カレントディレクトリが表示される
上記の書式で実行したコマンドを確認すると以下のようになります。
+ の表示のある行にはシェルにより展開されたコマンドが表示されています。
この場合、変数 PWD を展開しているのは echo コマンドではなく、シェルが行っています。
echo コマンドはシェルから文字列「/Users/foo」を渡されて表示しています。
bash -x -c "echo $PWD" return + echo /Users/foo #シェル(bash)により変数が展開されて echo コマンドに渡されている /Users/foo
以下は、変数を代入する際に値に空白があるのに引用符で括らないのでエラーになる例です。
foo=ab c return -bash: c: command not found bash -x -c "foo=ab c" return #上記コマンドの動作を確認 + foo=ab #引数には間に空白があるのでシェルにより ab と c に分割され、foo=ab を実行しようとする + c # c というコマンドを実行しようとする bash: c: command not found # c というコマンドは見つからない echo $? return # コマンドの終了ステータスを確認 127 # エラー(0意外なので失敗)
以下は変数 foo に空白を含む文字列を設定して、変数 foo をダブルクォートで括って出力する場合とそうでない場合の動作を確認する例です。
foo="a b c d" return # 変数 foo に空白を含む文字列を設定 echo $foo return a b c d # 空白が取り除かれて出力される bash -x -c "echo $foo" return # 上記コマンドの動作を確認 + echo a b c d # シェルにより空白が取り除かれて echo に渡されている a b c d echo "$foo" return a b c d # 空白はキープされる bash -x -c "echo \"$foo\"" return # 上記コマンドの動作を確認 + echo 'a b c d' # シェルにより変数が展開されシングルクォートで括られて(空白は削除されず)echo に渡されている a b c d echo a b c d return a b c d # 空白が取り除かれて出力される bash -x -c "echo a b c d" return # 上記コマンドの動作を確認 + echo a b c d # シェルにより空白が取り除かれて echo に渡されている a b c d
最初の例の echo abc の動作は以下のようになり、全て同じになっています。
bash -x -c "echo abc" return + echo abc # シェルから echo にそのまま渡される abc bash -x -c "echo 'abc'" return + echo abc # シェルによりシングルクォートが取り除かれて echo に渡される abc bash -x -c "echo \"abc\"" return + echo abc # シェルによりシダブルクォートが取り除かれて echo に渡される abc
また、先述の「find . -name *」のように「*」を引用符で括らないとエラーになる動作は以下のようになっています。
以下は、カレントディレクトリに「log.txt」「sample.txt」「test.csv」の3つのファイルがある例です。
bash -x -c "find . -name *" return + find . -name log.txt sample.txt test.csv # シェルにより * が展開され3つのファイル名が find に渡される find: sample.txt: unknown primary or operator # 空白区切りの値が渡されてエラー bash -x -c "find . -name '*'" return + find . -name '*' # シェルにより * が find に渡され想定通りに動作する . ./test.csv ./log.txt ./sample.txt
zsh の展開についての man ページは man zshexpn で確認できます。